Recommended
PDF
Active Learning from Imperfect Labelers @ NIPS読み会・関西
PDF
PPTX
Vanishing Component Analysis
PDF
[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2
PDF
DL Hacks輪読 Semi-supervised Learning with Deep Generative Models
PDF
2013.07.15 はじパタlt scikit-learnで始める機械学習
PDF
公平性を保証したAI/機械学習
アルゴリズムの最新理論
PDF
PDF
[DSO] Machine Learning Seminar Vol.2 Chapter 3
PPTX
Pythonとdeep learningで手書き文字認識
PDF
TensorFlowによるニューラルネットワーク入門
PDF
論文紹介 Semi-supervised Learning with Deep Generative Models
PDF
Data-Intensive Text Processing with MapReduce ch6.1
PDF
Microsoft Malware Classification Challenge 上位手法の紹介 (in Kaggle Study Meetup)
PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
PDF
クラシックな機械学習の入門 4. 学習データと予測性能
PDF
PDF
LCCC2010:Learning on Cores, Clusters and Cloudsの解説
PDF
PDF
PDF
PDF
Semi-Supervised Learning Using Gaussian Fields and Harmonic Functions (ICML2003)
PDF
PDF
PDF
KDD2014勉強会: Large-Scale High-Precision Topic Modeling on Twitter
PPTX
Dimensionality reduction with t-SNE(Rtsne) and UMAP(uwot) using R packages.
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification)
PDF
Joint Modeling of a Matrix with Associated Text via Latent Binary Features
PDF
Information-Theoretic Metric Learning
More Related Content
PDF
Active Learning from Imperfect Labelers @ NIPS読み会・関西
PDF
PPTX
Vanishing Component Analysis
PDF
[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2
PDF
DL Hacks輪読 Semi-supervised Learning with Deep Generative Models
PDF
2013.07.15 はじパタlt scikit-learnで始める機械学習
PDF
公平性を保証したAI/機械学習
アルゴリズムの最新理論
PDF
What's hot
PDF
[DSO] Machine Learning Seminar Vol.2 Chapter 3
PPTX
Pythonとdeep learningで手書き文字認識
PDF
TensorFlowによるニューラルネットワーク入門
PDF
論文紹介 Semi-supervised Learning with Deep Generative Models
PDF
Data-Intensive Text Processing with MapReduce ch6.1
PDF
Microsoft Malware Classification Challenge 上位手法の紹介 (in Kaggle Study Meetup)
PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
PDF
クラシックな機械学習の入門 4. 学習データと予測性能
PDF
PDF
LCCC2010:Learning on Cores, Clusters and Cloudsの解説
PDF
PDF
PDF
PDF
Semi-Supervised Learning Using Gaussian Fields and Harmonic Functions (ICML2003)
PDF
PDF
PDF
KDD2014勉強会: Large-Scale High-Precision Topic Modeling on Twitter
PPTX
Dimensionality reduction with t-SNE(Rtsne) and UMAP(uwot) using R packages.
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification)
Viewers also liked
PDF
Joint Modeling of a Matrix with Associated Text via Latent Binary Features
PDF
Information-Theoretic Metric Learning
PDF
PDF
PPTX
MIRU2014 tutorial deeplearning
PDF
Practical recommendations for gradient-based training of deep architectures
PDF
Deep Learningと画像認識� �~歴史・理論・実践~
Similar to A Machine Learning Framework for Programming by Example
PDF
Deep learning reading club @ nimiri for SWEST
PDF
Raspberry Pi Deep Learning Hand-on
PDF
Unified Expectation Maximization
PDF
PDF
PyConJP Keynote Speech (Japanese version)
PDF
Python 機械学習プログラミング データ分析ライブラリー解説編
PDF
PFI Christmas seminar 2009
PDF
PDF
PDF
DATUM STUDIO PyCon2016 Turorial
PDF
PPTX
PPT
PDF
PDF
PDF
[第2版] Python機械学習プログラミング 第1章
PPTX
PDF
PPT
PDF
More from Koji Matsuda
PPTX
Reading Wikipedia to Answer Open-Domain Questions (ACL2017) and more...
PPTX
KB + Text => Great KB な論文を多読してみた
PPTX
Large-Scale Information Extraction from Textual Definitions �through Deep Syn...
PPTX
PDF
「今日から使い切る」�ための GNU Parallel�による並列処理入門
PDF
PPTX
Entity linking meets Word Sense Disambiguation: a unified approach(TACL 2014)の紹介
PDF
いまさら聞けない “モデル” の話 @DSIRNLP#5
PDF
Align, Disambiguate and Walk : A Unified Approach forMeasuring Semantic Simil...
PDF
Language Models as Representations for Weakly-Supervised NLP Tasks (CoNLL2011)
PDF
PDF
PDF
Word Sense Induction & Disambiguaon Using Hierarchical Random Graphs (EMNLP2010)
PPTX
Approximate Scalable Bounded Space Sketch for Large Data NLP
A Machine Learning Framework for Programming by Example 1. A
Machine
Learning
Framework
for
Programming
by
Example
Aditya
Menon,
Omer
Tamuz,
Sumit
Gulwani,
Butler
Lampson,
Adam
Kalai
ICML
2013
すずかけ論文読み会
#3
(2013/06/01)
紹介者
:
matsuda
1
2. Programming
by
Example
(PBE)
• 「例」からのプログラミング
– UI
/
プログラム生成の分野で研究されてきた問題
– 「変換前」,「変換後」のペアから変換プログラム
を生成
• たとえば・・・)
Excel2013のFlash
Fill
– セル情報に基づくテキストの書き換え
– 百聞は一見にしかず (YouTube)
– すでに実用化されている
– ただし,
line
by
lineの書き換え
2
3. 4. 何が難しいか
• 一般に,トレーニングデータは非常に少ない
– もしかしたら,
1
事例しか与えられないかもしれない
• f(x)
=
y
を満たすような
f(プログラム)
は一般に無限に存在
– ものすごく長い
f
,汎用性のない
f
,,,,
– brute-‐forceにやっても恐らくは見つかるが,たいへん時間がか
かる
• 複数の事例から同時に学習を行う
– 書き換えプログラムの「一般的な性質」を学習!
• ランキング問題として定式化し,もっともらしい
f
を「探索」
する問題に落とす
– 探索の高速化!
4
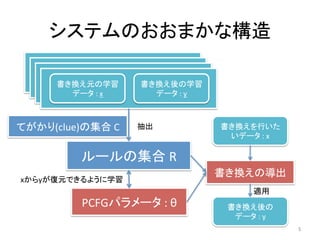
5. システムのおおまかな構造
書き換え元の学習
データ
:
x
書き換え元の学習
データ
:
y
書き換え元の学習
データ
:
x
書き換え元の学習
データ
:
y
書き換え元の学習
データ
:
x
書き換え元の学習
データ
:
y
書き換え元の学習
データ
:
x
書き換え後の学習
データ
:
y
ルールの集合
R
てがかり(clue)の集合
C
PCFGパラメータ
:
θ
書き換えの導出
抽出
書き換えを行いた
いデータ
:
x
書き換え後の
データ
:
y
5
xからyが復元できるように学習
適用
6. 問題の定式化
• 学習対象
:
f
∈
{
S
-‐>
S
}
– 文字列から文字列への書き換えプログラム
• データ
:
x(書き換え前)
,
y(書き換え後),
x(書き換
えを適用したいデータ)
• F(・)
:
(x
-‐>
y)
の変換を実現する全てのプログラ
ム(膨大)
– この上で 「もっともらしさ」 に基づいてランキングを行
う関数を学習する
– 「もっともらしさ」をどのように表現するか,どのように
学習するか
6
7. 8. 9. 書き換えとルールの関連付け:clues
• clues
(手がかり)
– c
:
S3
-‐>
2R
• データの組を受け取って,ルールの集合を返す
– こういう特徴の場合こういうルールが適応できる,という知識
• Givenであると仮定?
– CRFで言うところの素性関数テンプレートのようなもの
書き換え元の学習
データ
:
x
書き換え後の学習
データ
:
y
てがかり(clue)の集合
C
ルールの集合
R
抽出
9
10.
clueの例
prior_cue,
unique_inp_cue,
dedup_cue,
case_cue
trim_cue,
strip_space_cue,
simple_append_prepend
extract_numbers_cue,
numeric_cue,
sequence_cue
generalized_sequence_cue,
count_occ_cue,
line_num_cue
comma_and_cue,
num_to_word_cue,
matricize_cue,
sort_cue
map_each_line_cue,
remove_char_cue
他にもたとえば)
※完全なリストは hip://cseweb.ucsd.edu/~akmenon/pbe/ にあります
10
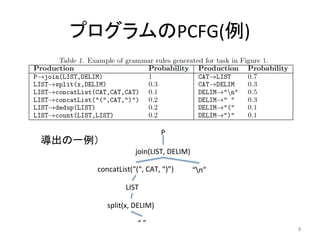
11. Pr[
r
|
z;
θ
]のモデル
• ごくふつうのlog
linear
モデル
θ
:
ルールひとつひとつの重み(実数)
ci(z)
:
テキストを受け取ってルールの集合を返す関数(前述のclue)
Z
:
正規化
ルールの左辺(
LHS(r)
)から導出されるすべての右辺を足しあわせ
0
or
1
11
12. 13. 正解データは?
• 正解データを用意するのは難しい
• bootstrapによって学習(x,
yペアのみから学習)
– θ(0)
=
0
と初期化(すべてのルールが同じ重み)
– f(x)
=
y
を満たす(正しく変換する)尤もらしいプログラ
ムを推論
• 最初は「短い」
f
が優先される?
• 見つからなければその事例は無視
– それを正解データとして,θを更新
– 収束するまで繰り返し
13
14. 未知のデータに対するプログラム生成
• 入力
– データ z
:
(x,
x,
y
)
(学習には使っていないもの)
– 手がかり
:
c1,
c2,
…
cn
– モデルパラメータ
:
θ
∈
Rn
,
タイムアウト τ
1. データから手がかりを探し出し,ルール集合Rを生成
2. ルール集合の元に対してパラメータを用いて確率値を付与
(PCFGの各導出に対する確率値の付与)
3. PCFGの導出( プログラム:f )を確率値の降順に探索,
x,
y
を正しく変換している導出を返す
4. タイムアウトまでに正しく変換する導出が見つからなけれ
ば失敗(タイムアウトを設定しないと永遠に導出し続ける)
14
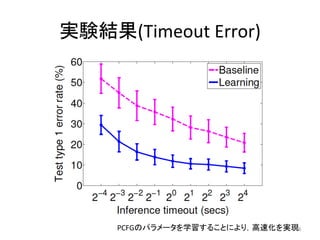
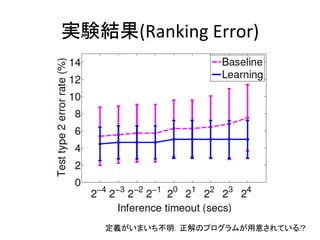
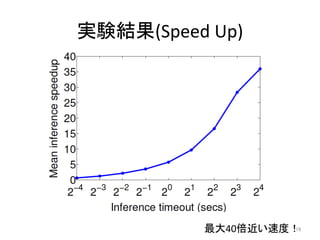
15. 実験
• データ
– (x,
y)
280ペア
• 一部は人手で作成(Gulwani,
2011)
• 残りはExcelのヘルプフォーラムから人手で収集
– base
funcqon(ルールの元)
:
100個くらい
– clues(テキスト組とルール集合の対応づけ)
:
100個くらい
– データは hip://cseweb.ucsd.edu/~akmenon/pbe/
にあるよ
• ベースライン
– θ
=
0
のもの
(すべてのルールが同じ重み)
• 実験設定
– 80(train)
−20(test)
splitを10組
– タイムアウト
τ
を変化させる
– bootstrapは3回
15
16. 17. 18. 19. まとめ /
感想
• 「例からのプログラミング」に対する機械学習か
らのアプローチ
• プログラムをPCFGからの導出で表現し,そのパ
ラメータをbootstrapに学習
• 学習しない場合と比較して最大40倍の高速化,
正解率も向上
• 感想
– clueとルールの対応付けは人手?何か出来そう
– 似た枠組みをNLPに応用できないかな?
• 略語の推定,要約etc…
19






![プログラムを確率モデルとして表す
• プログラムの上の確率モデル(PCFG)
– Pr[
f
|
z
;
θ
]
• z
:
(x,
x,y)の組, θ:確率モデルのパラメータ
r
:
書き換えルール ex.
(
LIST
-‐>
dedup(LIST)
)
(あらかじめいっぱい用意してある)
• データ(z)とルールをどのように関連付けるか?
• Pr
[
r
|
z
;
θ
]
をどのようにモデル化するか?
7](https://image.slidesharecdn.com/pbe-130601022906-phpapp01/85/A-Machine-Learning-Framework-for-Programming-by-Example-7-320.jpg)


![Pr[
r
|
z;
θ
]のモデル
• ごくふつうのlog
linear
モデル
θ
:
ルールひとつひとつの重み(実数)
ci(z)
:
テキストを受け取ってルールの集合を返す関数(前述のclue)
Z
:
正規化
ルールの左辺(
LHS(r)
)から導出されるすべての右辺を足しあわせ
0
or
1
11](https://image.slidesharecdn.com/pbe-130601022906-phpapp01/85/A-Machine-Learning-Framework-for-Programming-by-Example-11-320.jpg)








![[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2](https://cdn.slidesharecdn.com/ss_thumbnails/chapter12slides-200211153032-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSO] Machine Learning Seminar Vol.2 Chapter 3](https://cdn.slidesharecdn.com/ss_thumbnails/chapter3slides-200226170409-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[第2版] Python機械学習プログラミング 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-01-180905090109-thumbnail.jpg?width=640&height=640&fit=bounds)

















