Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Teruyuki Sakaue
PDF, PPTX
23,078 views
Marketing×Python/Rで頑張れる事例16本ノック
・Tokyo Marketers Talkでの発表資料
Technology
◦
Read more
20
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 39
2
/ 39
3
/ 39
4
/ 39
5
/ 39
6
/ 39
7
/ 39
8
/ 39
9
/ 39
10
/ 39
11
/ 39
12
/ 39
13
/ 39
14
/ 39
15
/ 39
16
/ 39
17
/ 39
18
/ 39
19
/ 39
20
/ 39
21
/ 39
22
/ 39
23
/ 39
24
/ 39
25
/ 39
26
/ 39
27
/ 39
28
/ 39
29
/ 39
30
/ 39
31
/ 39
32
/ 39
33
/ 39
34
/ 39
35
/ 39
36
/ 39
37
/ 39
38
/ 39
39
/ 39
More Related Content
PDF
Optuna Dashboardの紹介と設計解説 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PPTX
[DL輪読会]機械学習におけるカオス現象について
by
Deep Learning JP
PDF
【DL輪読会】Code as Policies: Language Model Programs for Embodied Control
by
Deep Learning JP
PPTX
パワポ版の落合先生流論文要旨のテンプレートを作ったので配布する
by
森 哲也
PPTX
ブラックボックスからXAI (説明可能なAI) へ - LIME (Local Interpretable Model-agnostic Explanat...
by
西岡 賢一郎
PPTX
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
PDF
画像認識の初歩、SIFT,SURF特徴量
by
takaya imai
PDF
3次元レジストレーションの基礎とOpen3Dを用いた3次元点群処理
by
Toru Tamaki
Optuna Dashboardの紹介と設計解説 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
[DL輪読会]機械学習におけるカオス現象について
by
Deep Learning JP
【DL輪読会】Code as Policies: Language Model Programs for Embodied Control
by
Deep Learning JP
パワポ版の落合先生流論文要旨のテンプレートを作ったので配布する
by
森 哲也
ブラックボックスからXAI (説明可能なAI) へ - LIME (Local Interpretable Model-agnostic Explanat...
by
西岡 賢一郎
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
画像認識の初歩、SIFT,SURF特徴量
by
takaya imai
3次元レジストレーションの基礎とOpen3Dを用いた3次元点群処理
by
Toru Tamaki
What's hot
PDF
Sift特徴量について
by
la_flance
PDF
Social GAME における AI 活用事例 [第 4 回 Google Cloud INSIDE Games & Apps]
by
Google Cloud Platform - Japan
PDF
MICの解説
by
logics-of-blue
PDF
画像局所特徴量と特定物体認識 - SIFTと最近のアプローチ -
by
MPRG_Chubu_University
PDF
semantic segmentation サーベイ
by
yohei okawa
PDF
【メタサーベイ】Neural Fields
by
cvpaper. challenge
PDF
Python入門 : 4日間コース社内トレーニング
by
Yuichi Ito
PDF
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
PDF
SLAM開発における課題と対策の一例の紹介
by
miyanegi
PDF
SSII2018TS: 3D物体検出とロボットビジョンへの応用
by
SSII
PDF
多人数不完全情報ゲームにおけるAI ~ポーカーと麻雀を例として~
by
Kenshi Abe
PDF
Prophet入門【理論編】Facebookの時系列予測ツール
by
hoxo_m
PDF
実践コンピュータビジョン 3章 画像間の写像
by
yaju88
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
PPTX
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
by
Hitomi Yanaka
PDF
Deeplearning輪読会
by
正志 坪坂
PPTX
【初心者向】ロジカルシンキングをゼロからはじめる
by
Ryosuke Ishii
PDF
Marp入門
by
Rui Watanabe
PDF
Deep Learning Lab 異常検知入門
by
Shohei Hido
PDF
レコメンドアルゴリズムの基本と周辺知識と実装方法
by
Takeshi Mikami
Sift特徴量について
by
la_flance
Social GAME における AI 活用事例 [第 4 回 Google Cloud INSIDE Games & Apps]
by
Google Cloud Platform - Japan
MICの解説
by
logics-of-blue
画像局所特徴量と特定物体認識 - SIFTと最近のアプローチ -
by
MPRG_Chubu_University
semantic segmentation サーベイ
by
yohei okawa
【メタサーベイ】Neural Fields
by
cvpaper. challenge
Python入門 : 4日間コース社内トレーニング
by
Yuichi Ito
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
SLAM開発における課題と対策の一例の紹介
by
miyanegi
SSII2018TS: 3D物体検出とロボットビジョンへの応用
by
SSII
多人数不完全情報ゲームにおけるAI ~ポーカーと麻雀を例として~
by
Kenshi Abe
Prophet入門【理論編】Facebookの時系列予測ツール
by
hoxo_m
実践コンピュータビジョン 3章 画像間の写像
by
yaju88
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
by
Hitomi Yanaka
Deeplearning輪読会
by
正志 坪坂
【初心者向】ロジカルシンキングをゼロからはじめる
by
Ryosuke Ishii
Marp入門
by
Rui Watanabe
Deep Learning Lab 異常検知入門
by
Shohei Hido
レコメンドアルゴリズムの基本と周辺知識と実装方法
by
Takeshi Mikami
Similar to Marketing×Python/Rで頑張れる事例16本ノック
PDF
『手を動かしながら学ぶ ビジネスに活かすデータマイニング』で目指したもの・学んでもらいたいもの
by
Takashi J OZAKI
PDF
財布にやさしいRを使ったデータマイニング
by
Ryoji Yanashima
PDF
全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
PDF
おしゃスタ@リクルート
by
Issei Kurahashi
PDF
20180807_全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
PDF
データマイニングCROSS 第2部-機械学習・大規模分散処理
by
Koichi Hamada
PDF
Rにおける大規模データ解析(第10回TokyoWebMining)
by
Shintaro Fukushima
PDF
20150421 日経ビッグデータカンファレンス
by
Akira Shibata
PPTX
PythonとRによるデータ分析環境の構築と機械学習によるデータ認識
by
Katsuhiro Morishita
PDF
Oracle Cloud Developers Meetup@東京
by
tuchimur
PDF
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V k-1
by
Shunsuke Nakamura
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで
by
Shunsuke Nakamura
PPTX
20181219_全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
『手を動かしながら学ぶ ビジネスに活かすデータマイニング』で目指したもの・学んでもらいたいもの
by
Takashi J OZAKI
財布にやさしいRを使ったデータマイニング
by
Ryoji Yanashima
全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
おしゃスタ@リクルート
by
Issei Kurahashi
20180807_全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
データマイニングCROSS 第2部-機械学習・大規模分散処理
by
Koichi Hamada
Rにおける大規模データ解析(第10回TokyoWebMining)
by
Shintaro Fukushima
20150421 日経ビッグデータカンファレンス
by
Akira Shibata
PythonとRによるデータ分析環境の構築と機械学習によるデータ認識
by
Katsuhiro Morishita
Oracle Cloud Developers Meetup@東京
by
tuchimur
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V k-1
by
Shunsuke Nakamura
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで
by
Shunsuke Nakamura
20181219_全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
More from Teruyuki Sakaue
PDF
実務と論文で学ぶジョブレコメンデーション最前線2022
by
Teruyuki Sakaue
PDF
警察庁オープンデータで交通事故の世界にDeepDive!
by
Teruyuki Sakaue
PDF
[丸ノ内アナリティクスバンビーノ#23]データドリブン施策によるサービス品質向上の取り組み
by
Teruyuki Sakaue
PDF
[Music×Analytics]プロの音に近づくための研究と練習
by
Teruyuki Sakaue
PDF
[DSO] Machine Learning Seminar Vol.8 Chapter 9
by
Teruyuki Sakaue
PDF
データ分析ランチセッション#24 OSSのAutoML~TPOTについて
by
Teruyuki Sakaue
PDF
[第11回]データ分析ランチセッション - モダンな機械学習データパイプラインKedroを触ってみる
by
Teruyuki Sakaue
PDF
[DSO] Machine Learning Seminar Vol.2 Chapter 3
by
Teruyuki Sakaue
PDF
[第6回]データ分析ランチセッション - Camphrでモダンな自然言語処理
by
Teruyuki Sakaue
PDF
[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2
by
Teruyuki Sakaue
PDF
地理データを集め、可視化し分析することが簡単にできるプログラミング言語について @ BIT VALLEY -INSIDE- Vol.16
by
Teruyuki Sakaue
PDF
[第1回]データ分析ランチセッション ~ Qiita Advent Calendar2019から得た情報10選
by
Teruyuki Sakaue
PDF
流行りの分散表現を用いた文書分類について Netadashi Meetup 7
by
Teruyuki Sakaue
PDF
HRビジネスにおけるデータサイエンスの適用 @ BIT VALLEY -INSIDE- Vol.1
by
Teruyuki Sakaue
PDF
機械学習による積極的失業〜オウンドメディアの訪問予測
by
Teruyuki Sakaue
実務と論文で学ぶジョブレコメンデーション最前線2022
by
Teruyuki Sakaue
警察庁オープンデータで交通事故の世界にDeepDive!
by
Teruyuki Sakaue
[丸ノ内アナリティクスバンビーノ#23]データドリブン施策によるサービス品質向上の取り組み
by
Teruyuki Sakaue
[Music×Analytics]プロの音に近づくための研究と練習
by
Teruyuki Sakaue
[DSO] Machine Learning Seminar Vol.8 Chapter 9
by
Teruyuki Sakaue
データ分析ランチセッション#24 OSSのAutoML~TPOTについて
by
Teruyuki Sakaue
[第11回]データ分析ランチセッション - モダンな機械学習データパイプラインKedroを触ってみる
by
Teruyuki Sakaue
[DSO] Machine Learning Seminar Vol.2 Chapter 3
by
Teruyuki Sakaue
[第6回]データ分析ランチセッション - Camphrでモダンな自然言語処理
by
Teruyuki Sakaue
[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2
by
Teruyuki Sakaue
地理データを集め、可視化し分析することが簡単にできるプログラミング言語について @ BIT VALLEY -INSIDE- Vol.16
by
Teruyuki Sakaue
[第1回]データ分析ランチセッション ~ Qiita Advent Calendar2019から得た情報10選
by
Teruyuki Sakaue
流行りの分散表現を用いた文書分類について Netadashi Meetup 7
by
Teruyuki Sakaue
HRビジネスにおけるデータサイエンスの適用 @ BIT VALLEY -INSIDE- Vol.1
by
Teruyuki Sakaue
機械学習による積極的失業〜オウンドメディアの訪問予測
by
Teruyuki Sakaue
Marketing×Python/Rで頑張れる事例16本ノック
1.
Marketing×Python/Rで頑張れる事例16本ノック 2018/04/10 Tokyo Marketers Talk Mr_Sakaue
2.
・Twitterアカウント名:Mr_Sakaue ・経歴:某大学院で経済学修士 渋谷のベンチャー企業に新卒で入社 Webマーケティング周りでの雑務 をこなす。 ・スキル:R少々、Python少々 ・趣味:ブログをやっています。 「かものはしの分析ブログ」 →データを集めて調理するブログ 何者か
3.
・マーケティング課題にデータ分析の適用を始めました。 ・マーケティング課題にPythonやRの力で向き合うと得られそうなご利益 ・手法やライブラリなどの紹介 ※話さないこと ・各手法の細かい説明 ※※NGワード ・それTableauでもできますやん 今日伝えたいこと
4.
・Python ・汎用のプログラミング言語 ・わかりやすいコードが特徴 ・科学技術系の研究で多用されており、それに派生したライブラリが充実 ・R ・統計解析に特化したプログラミング言語 ・様々な統計解析手法をカバーするライブラリ群が魅力 Python/Rとは
5.
メリデメ for マーケター メリット
デメリット Python ・Rよりも計算が早い ・大きなデータも扱える ・機械学習系のライブラリが充実 ・RよりもDS界隈では人気 ・プログラミング初心者には若干厳しい (最近はAnaconda入れたら大丈夫かも ) ・同じことをRでやるよりもコードが長くなりが ち(汎用言語なので) R ・Marketer Friendly(Excellで慣れ親しんだ 行列を使えたり、デフォルトでも色々分析で きる) ・統計解析系が充実、機械学習系も十分に ある。 ・大きめのデータで動かない ・困った時にググりにくい
6.
ノック開始!
7.
状況:営業が蓄積したデータの分析依頼をされたが、 そのデータがそのまま分析していいのか気になる。 アプローチ:pandas-tdを使ってTresureDataからデータを取得 pandasで日付データから月のついたちデータを生成 欠損データに関しては欠損確認用のデータを生成 月をもとにgroupbyを行い、その結果を時系列プロット ご利益: ・もらったデータの時系列的なムラを確認し、怪しい傾向を分析着手前に気付ける。 ・欠損の傾向から、データ蓄積に問題が生じてそうな兆候に気付ける。 Knock1:時系列プロット
8.
dataset.groupby('month').agg([np.mean]).plot(subplots=True, figsize=(15, 200)) 1行で時系列プロットや!
9.
状況:生アクセスログからCVしている人とそうでない人の差を見つけたい。 アプローチ:pandas-tdを使ってTresureDataからデータを取得 numpyで正規表現でページカテゴリーを付与 pandasでCVする前までのセッションのインデックスで絞り込み 行がストレージクッキー、列がページカテゴリーのピボットテーブルを 作成 ご利益: ・SQLでできるが、データサイズが大き過ぎなければコードも短いしサクッとできて便利。たま に買い切り型の広告系のログだとSQLじゃない環境だったりするので、その時は便利。 Knock2:ピボットテーブル
10.
#ユーザーごとに触れたページのカテゴリ別に集計する pageview_table = pd.pivot_table(data=result
, fill_value=0, index="storage_cookie", columns="page_category",aggfunc = { 'page_category' : 'count' } )
11.
状況:生アクセスログから、あるページを触れた人がどのようなページを見ているのか傾向を 知りたい。(平均値は嘘をつくのでできればヒストグラムがいい) アプローチ:先ほど作成したピボットテーブルに対して、pandasで groupbyしてplotでヒストグラムを指定 ご利益: ・エクセルで多数のヒストグラムを作るとなるとツラミがあるが、どんなにデータの種類が多くて も1行で可視化できる。 Knock3:ヒストグラム
12.
dataset[dataset.ef_flag == 1].filter(regex=target_column).plot(subplots=True ,kind="hist",figsize=(15,
100), bins=200, xlim=[1, 100 ], ylim=[0,1000 ])
13.
状況:NPSなどのデータがどのような変数と相関してそうか細かく見たい。 アプローチ:ExcelなどのデータをRにインポート Rのggplot2のgeom_pointとfacet_gridを適用 4次元分のデータを一つの散布図で描写 ご利益: ・各属性ごとに、NPSとの相関の強さは変わってくるはずで、その傾向を簡単に見れる。もは やExcelで同様のことをしようと思えない。 Knock4:散布図
15.
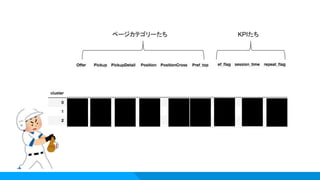
状況:アクセスログをそのまま分析しても傾向が見れず捗らない。 アプローチ:セッションカウントデータの標準化 Pythonのscikit-learnでチャネルクラスタリング 同様にページカテゴリクラスタリング ベストなクラスターの数を推定し、適用 クラスターごとにKPIを繋いで傾向を把握 ご利益: ・サービス理解が浅い段階で使うと、素早く主要なユーザーの傾向を掴める。 ・クラスターごとにさらに深ぼって分析できる。 Knock5:ユーザークラスタリング
16.
KPIたちページカテゴリーたち ≈ç ≈ç ≈ç
ō ō ō ō ō ō
17.
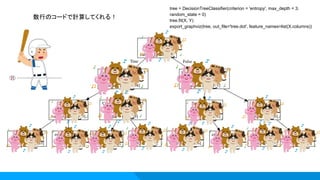
状況:ユーザーがCVするかどうかを決めるキーファクターを見つけたい。 アプローチ:作ったクラスターごとにscikit-learnのDecisionTreeを適用 ご利益: ・サービス理解が浅い段階で使うと、CVに近い行動の把握ができる。 ・意外な傾向が見つかれば、サイト改善の施策などに繋がる。 ・分析後は実際にどれくらいの対象ユーザへのインパクトがあるのかを検算。 Knock6:決定木
18.
数行のコードで計算してくれる! tree = DecisionTreeClassifier(criterion
= 'entropy', max_depth = 3, random_state = 0) tree.fit(X, Y) export_graphviz(tree, out_file='tree.dot', feature_names=list(X.columns))
19.
状況:来月の応募数を知りたい アプローチ:応募ログデータ、営業日数、最終営業日などのデータを収集 Facebook社の提供しているProphetを用いて予測 直近数ヶ月のRMSE (Root Mean
Squared Error)の低いモデルを採用 ご利益: ・月間目標を目指す際に、10日や15日時点でそこそこの応募数がわかるので、 目標乖離時にアクションを取るべきかの判断をすることができる。 Knock7:時系列予測
20.
Prophetを使って、新幹線予約の検索クエリのトレンドを予測 12月25日12月3日~12月9日12月1日 大人の余裕前のめり 後の祭り
21.
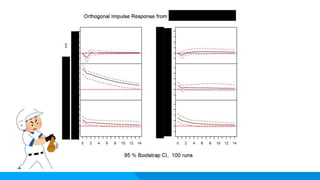
状況:運用型広告での競合の動きを捉える アプローチ:自社と競合サイトの時系列のインプレッションデータなどを用意 RのVARパッケージを利用 単位根検定などを経て、VARの推定 インパルス応答関数からどの競合が自社に影響があるのか分析 ご利益: ・特定の競合のインプレッションが自社サービスの指標にどのように影響を与えるのかを知っ た上で、運用型広告をまわせる。 Knock8:VAR(Vector AutoRegression)
23.
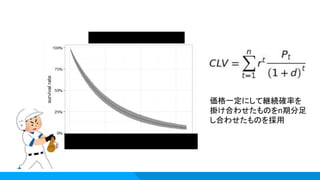
状況:顧客生涯価値(LifeTimeValue)をもとめたい。 アプローチ:顧客との取引レコードを用意 解約の定義を決め Rのflexsurvパッケージを利用 1~3年間の売上を予測する上でパフォーマンスの良い手法を採用 ご利益: ・より精度の高いLTVを手に入れることができる。 ・オレオレな謎エクセルではなく、再現性のあるRコードが残る。 Knock9:LTVの推定
24.
価格一定にして継続確率を 掛け合わせたものをn期分足 し合わせたものを採用
25.
状況:フリーテキストばかりのデータから意味のありそうな特徴を掴みたい。 アプローチ:フリーテキストまみれのデータと解約者のデータを繋ぐ 6ヶ月後に解約するかどうかのデータを作る MeCabパッケージでテキストを形態素解析する 解約する人としない人のテキスト上での差異を比較する ご利益: ・フリーテキストが多くても、意味のある傾向を掴めそうなので、改善のアクションに繋がる発 見があるかもしれない。 Knock10:テキストマイニング
26.
MeCab neologdを使えば蒙古タンメンも分解され ずに単語を分解できる。 汗を含んでいるかどうかと、リピート率を比較
27.
状況:メディア記事の分類をしたい アプローチ:DBから記事データを取得 不用語の除去 記事の本文に対してPythonでMeCabによる形態素解析をする Gensimでトピックを推定する トピックごとの意味合いを解釈し記事分類に利用する ご利益: ・数百記事のカテゴライズされていない記事があったとしても、うまく推定できればいい感じに 記事のカテゴリを分けれるので便利。 Knock11:トピックモデル
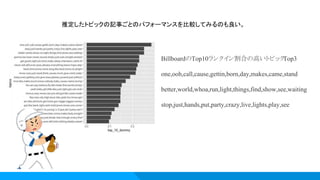
28.
BillboardのTop10ランクイン割合の高いトピックTop3 one,ooh,call,cause,gettin,born,day,makes,came,stand better,world,whoa,run,light,things,find,show,see,waiting stop,just,hands,put,party,crazy,live,lights,play,see 推定したトピックの記事ごとのパフォーマンスを比較してみるのも良い。
29.
状況:ユーザーが過去に見た情報に近そうな情報をしたい アプローチ:記事の本文に対してPythonでMeCabによる形態素解析し、 テキストデータを行列データに変換(行:単語、列:文書) scikit-learnでTF-IDFを計算し、COS類似度を計算 (トピック間の類似度で出すやり方もある) ご利益: ・細かいカテゴリデータがなくても、文書内の構成単語の近さから、記事を推薦できる。うまく いけばカテゴリデータよりも精度の良い推薦が可能。 Knock12:類似度計算
30.
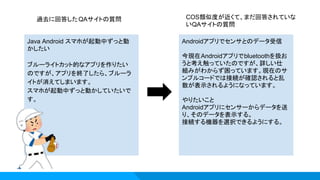
Java Android スマホが起動中ずっと動 かしたい ブルーライトカット的なアプリを作りたい のですが、アプリを終了したら、ブルーラ イトが消えてしまいます。 スマホが起動中ずっと動かしていたいで す。 Androidアプリでセンサとのデータ受信 今現在Androidアプリでbluetoothを扱お うと考え触っていたのですが、詳しい仕 組みがわからず困っています。現在のサ ンプルコードでは接続が確認されると乱 数が表示されるようになっています。 やりたいこと Androidアプリにセンサーからデータを送 り、そのデータを表示する。 接続する機器を選択できるようにする。 過去に回答したQAサイトの質問
COS類似度が近くて、まだ回答されていな いQAサイトの質問
31.
状況:広告文を考える時に文脈的に近そうな表現を知りたい。 アプローチ:テキストデータに対してPythonでMeCabによる形態素解析 GensimでWord2Vecを適用 任意の単語を入力し、文脈的に近いものを抽出 ご利益: ・大量のデータから、コンテクストの近そうな単語の上位を知れるので、広告文のアイデア出し に使えるかもしれない。 (昔、サイバーエージェントさんがWord2Vecを広告文言の自動生成に適用していた論文を見 たことがあります) Knock13:Word2Vec
32.
コンテクストの近い単語を見てみよう!
33.
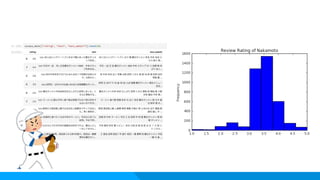
状況:蒙古タンメン中本の口コミの点数の分布を知りたい アプローチ:PythonのBeautifulSoupを使い、タグを指定 口コミ点数と口コミのコメント情報を取得(紳士的に) matplotlibで可視化 ご利益: ・手元にデータがなくても、インターネット上にあるデータをもとにマーケティングリサーチをす ることが可能。 Knock14:Webスクレイピング
35.
状況:好きな商品が値引きになった時に購入したい。 アプローチ:PythonのSeleniumパッケージを利用 定期的にログイン 価格の情報を取得 一定の価格以下ならカード情報やフォームを自動で入力 決済完了後の画面をスクショで自動撮影 ご利益: ・フォームの入力などが必須のサービスでもいろいろ自動化できる。 ※こちらも紳士的な頻度で。 Knock15:Selenium
36.
状況:分析終わったらレポートも欲しいなと言われる。 アプローチ:PythonのJupyter上でRISEパッケージを利用 jupyter notebookの1セルごとにスライドの指定ができる 指定は「見せる、独立して見せる、入れ子にして見せる、隠すなど」 指定して保存すればスライド完成 ご利益: ・分析しているjupyter notebookのソースコードをそのまま使ってスライド生成できるので、 分析+スライド作成のツラミから、かなり解放される。 Knock16:スライド作成
39.
ご静聴ありがとうございました!
Download









![dataset.groupby('month').agg([np.mean]).plot(subplots=True, figsize=(15, 200))
1行で時系列プロットや!](https://image.slidesharecdn.com/test-180410144551/85/MarketingxPython-R-16-8-320.jpg)



![dataset[dataset.ef_flag == 1].filter(regex=target_column).plot(subplots=True
,kind="hist",figsize=(15, 100), bins=200, xlim=[1, 100 ], ylim=[0,1000 ])](https://image.slidesharecdn.com/test-180410144551/85/MarketingxPython-R-16-12-320.jpg)




















![[DL輪読会]機械学習におけるカオス現象について](https://cdn.slidesharecdn.com/ss_thumbnails/20190419dlhacks-190510023936-thumbnail.jpg?width=640&height=640&fit=bounds)







![Social GAME における AI 活用事例 [第 4 回 Google Cloud INSIDE Games & Apps]](https://cdn.slidesharecdn.com/ss_thumbnails/0607inside4socialgame-180612044555-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[丸ノ内アナリティクスバンビーノ#23]データドリブン施策によるサービス品質向上の取り組み](https://cdn.slidesharecdn.com/ss_thumbnails/marunouchianalytics202107-210729113930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Music×Analytics]プロの音に近づくための研究と練習](https://cdn.slidesharecdn.com/ss_thumbnails/muanalt-210227062125-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSO] Machine Learning Seminar Vol.8 Chapter 9](https://cdn.slidesharecdn.com/ss_thumbnails/chapter9slides-200927083926-thumbnail.jpg?width=640&height=640&fit=bounds)

![[第11回]データ分析ランチセッション - モダンな機械学習データパイプラインKedroを触ってみる](https://cdn.slidesharecdn.com/ss_thumbnails/lunchsession11-200325093135-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSO] Machine Learning Seminar Vol.2 Chapter 3](https://cdn.slidesharecdn.com/ss_thumbnails/chapter3slides-200226170409-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第6回]データ分析ランチセッション - Camphrでモダンな自然言語処理](https://cdn.slidesharecdn.com/ss_thumbnails/dsolunchsession6-200219123751-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2](https://cdn.slidesharecdn.com/ss_thumbnails/chapter12slides-200211153032-thumbnail.jpg?width=640&height=640&fit=bounds)

![[第1回]データ分析ランチセッション ~ Qiita Advent Calendar2019から得た情報10選](https://cdn.slidesharecdn.com/ss_thumbnails/dsolunchsession1-200110120923-thumbnail.jpg?width=640&height=640&fit=bounds)


