Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Deep Learning JP
1,821 views
[DL輪読会]Training RNNs as Fast as CNNs
2017/10/2 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
5
Save
Share
Embed
Embed presentation
Download
Downloaded 11 times
1
/ 31
2
/ 31
3
/ 31
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...
by
Deep Learning JP
PDF
[DLHacks 実装] DeepPose: Human Pose Estimation via Deep Neural Networks
by
Deep Learning JP
PDF
[DL輪読会] Towards an Automatic Turing Test: Learning to Evaluate Dialogue Respo...
by
Deep Learning JP
PDF
論文 Solo Advent Calendar
by
諒介 荒木
PPTX
[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection
by
Deep Learning JP
PDF
[DLHacks 実装]Network Dissection: Quantifying Interpretability of Deep Visual R...
by
Deep Learning JP
PDF
Deep Learning技術の最近の動向とPreferred Networksの取り組み
by
Kenta Oono
PDF
[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−
by
Deep Learning JP
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...
by
Deep Learning JP
[DLHacks 実装] DeepPose: Human Pose Estimation via Deep Neural Networks
by
Deep Learning JP
[DL輪読会] Towards an Automatic Turing Test: Learning to Evaluate Dialogue Respo...
by
Deep Learning JP
論文 Solo Advent Calendar
by
諒介 荒木
[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection
by
Deep Learning JP
[DLHacks 実装]Network Dissection: Quantifying Interpretability of Deep Visual R...
by
Deep Learning JP
Deep Learning技術の最近の動向とPreferred Networksの取り組み
by
Kenta Oono
[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−
by
Deep Learning JP
What's hot
PPTX
Res netと派生研究の紹介
by
masataka nishimori
PPTX
[DL輪読会]Meta-Learning Probabilistic Inference for Prediction
by
Deep Learning JP
PDF
第1回NIPS読み会・関西発表資料
by
Takashi Shinozaki
PPTX
[DL輪読会]LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking
by
Deep Learning JP
PPTX
Pred net使ってみた
by
koji ochiai
PDF
ArtTrack: Articulated Multi-Person Tracking in the Wild : CV勉強会関東
by
Yukiyoshi Sasao
PPTX
MS COCO Dataset Introduction
by
Shinagawa Seitaro
PPTX
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
PDF
SSD: Single Shot MultiBox Detector (ECCV2016)
by
Takanori Ogata
PDF
[DL輪読会]Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Ima...
by
Deep Learning JP
PDF
0から理解するニューラルネットアーキテクチャサーチ(NAS)
by
MasanoriSuganuma
PPTX
[DL輪読会]DropBlock: A regularization method for convolutional networks
by
Deep Learning JP
PPTX
[DL輪読会]Deep Face Recognition: A Survey
by
Deep Learning JP
PPTX
[DL輪読会]Objects as Points
by
Deep Learning JP
PDF
Overcoming Catastrophic Forgetting in Neural Networks読んだ
by
Yusuke Uchida
PPTX
[DL輪読会]Xception: Deep Learning with Depthwise Separable Convolutions
by
Deep Learning JP
PPTX
[DL輪読会]SOLAR: Deep Structured Representations for Model-Based Reinforcement L...
by
Deep Learning JP
PDF
論文紹介 "DARTS: Differentiable Architecture Search"
by
Yuta Koreeda
PDF
CVPR2015読み会 "Joint Tracking and Segmentation of Multiple Targets"
by
Yuki Nagai
PDF
Deep Residual Learning (ILSVRC2015 winner)
by
Hirokatsu Kataoka
Res netと派生研究の紹介
by
masataka nishimori
[DL輪読会]Meta-Learning Probabilistic Inference for Prediction
by
Deep Learning JP
第1回NIPS読み会・関西発表資料
by
Takashi Shinozaki
[DL輪読会]LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking
by
Deep Learning JP
Pred net使ってみた
by
koji ochiai
ArtTrack: Articulated Multi-Person Tracking in the Wild : CV勉強会関東
by
Yukiyoshi Sasao
MS COCO Dataset Introduction
by
Shinagawa Seitaro
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
SSD: Single Shot MultiBox Detector (ECCV2016)
by
Takanori Ogata
[DL輪読会]Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Ima...
by
Deep Learning JP
0から理解するニューラルネットアーキテクチャサーチ(NAS)
by
MasanoriSuganuma
[DL輪読会]DropBlock: A regularization method for convolutional networks
by
Deep Learning JP
[DL輪読会]Deep Face Recognition: A Survey
by
Deep Learning JP
[DL輪読会]Objects as Points
by
Deep Learning JP
Overcoming Catastrophic Forgetting in Neural Networks読んだ
by
Yusuke Uchida
[DL輪読会]Xception: Deep Learning with Depthwise Separable Convolutions
by
Deep Learning JP
[DL輪読会]SOLAR: Deep Structured Representations for Model-Based Reinforcement L...
by
Deep Learning JP
論文紹介 "DARTS: Differentiable Architecture Search"
by
Yuta Koreeda
CVPR2015読み会 "Joint Tracking and Segmentation of Multiple Targets"
by
Yuki Nagai
Deep Residual Learning (ILSVRC2015 winner)
by
Hirokatsu Kataoka
Viewers also liked
PPTX
[DL Hacks 実装]The Conditional Analogy GAN: Swapping Fashion Articles on People...
by
Deep Learning JP
PDF
[DLHacks 実装]Neural Machine Translation in Linear Time
by
Deep Learning JP
PDF
[DL輪読会]Deep Recurrent Generative Decoder For Abstractive Text Summarization(E...
by
Deep Learning JP
PDF
[DLHacks 実装]Perceptual Adversarial Networks for Image-to-Image Transformation
by
Deep Learning JP
PDF
[DL輪読会]Energy-based generative adversarial networks
by
Deep Learning JP
PDF
[DL輪読会]Opening the Black Box of Deep Neural Networks via Information
by
Deep Learning JP
PDF
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
PDF
[DL輪読会]Deep Direct Reinforcement Learning for Financial Signal Representation...
by
Deep Learning JP
[DL Hacks 実装]The Conditional Analogy GAN: Swapping Fashion Articles on People...
by
Deep Learning JP
[DLHacks 実装]Neural Machine Translation in Linear Time
by
Deep Learning JP
[DL輪読会]Deep Recurrent Generative Decoder For Abstractive Text Summarization(E...
by
Deep Learning JP
[DLHacks 実装]Perceptual Adversarial Networks for Image-to-Image Transformation
by
Deep Learning JP
[DL輪読会]Energy-based generative adversarial networks
by
Deep Learning JP
[DL輪読会]Opening the Black Box of Deep Neural Networks via Information
by
Deep Learning JP
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
[DL輪読会]Deep Direct Reinforcement Learning for Financial Signal Representation...
by
Deep Learning JP
Similar to [DL輪読会]Training RNNs as Fast as CNNs
PPTX
[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS
by
Deep Learning JP
PDF
[ML論文読み会資料] Training RNNs as Fast as CNNs
by
Hayahide Yamagishi
PPTX
論文紹介:「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」
by
Naonori Nagano
PDF
LSTM (Long short-term memory) 概要
by
Kenji Urai
PPTX
Paper: seq2seq 20190320
by
Yusuke Fujimoto
PDF
ChainerによるRNN翻訳モデルの実装+@
by
Yusuke Oda
PDF
Learning to forget continual prediction with lstm
by
Fujimoto Keisuke
PDF
Deep Forest: Towards An Alternative to Deep Neural Networks
by
harmonylab
PPTX
Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation
by
tomoaki0705
PPTX
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
PDF
Recurrent Neural Networks
by
Seiya Tokui
PDF
深層学習レポートDay3(小川成)
by
ssuser441cb9
PPTX
CVPR2017 参加報告 速報版 本会議 4日目
by
Atsushi Hashimoto
PDF
dl-with-python01_handout
by
Shin Asakawa
PPTX
LSTMで話題分類
by
__john_smith__
DOCX
レポート深層学習Day3
by
ssuser9d95b3
PDF
[DLHacks 実装] The statistical recurrent unit
by
Deep Learning JP
PPTX
Generating Better Search Engine Text Advertisements with Deep Reinforcement L...
by
harmonylab
PDF
拡がるディープラーニングの活用
by
NVIDIA Japan
PDF
文献紹介:Recursive Deep Models for Semantic Compositionality Over a Sentiment Tre...
by
Shohei Okada
[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS
by
Deep Learning JP
[ML論文読み会資料] Training RNNs as Fast as CNNs
by
Hayahide Yamagishi
論文紹介:「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」
by
Naonori Nagano
LSTM (Long short-term memory) 概要
by
Kenji Urai
Paper: seq2seq 20190320
by
Yusuke Fujimoto
ChainerによるRNN翻訳モデルの実装+@
by
Yusuke Oda
Learning to forget continual prediction with lstm
by
Fujimoto Keisuke
Deep Forest: Towards An Alternative to Deep Neural Networks
by
harmonylab
Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation
by
tomoaki0705
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
Recurrent Neural Networks
by
Seiya Tokui
深層学習レポートDay3(小川成)
by
ssuser441cb9
CVPR2017 参加報告 速報版 本会議 4日目
by
Atsushi Hashimoto
dl-with-python01_handout
by
Shin Asakawa
LSTMで話題分類
by
__john_smith__
レポート深層学習Day3
by
ssuser9d95b3
[DLHacks 実装] The statistical recurrent unit
by
Deep Learning JP
Generating Better Search Engine Text Advertisements with Deep Reinforcement L...
by
harmonylab
拡がるディープラーニングの活用
by
NVIDIA Japan
文献紹介:Recursive Deep Models for Semantic Compositionality Over a Sentiment Tre...
by
Shohei Okada
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
[DL輪読会]Training RNNs as Fast as CNNs
1.
1 DEEP LEARNING JP [DL
Papers] http://deeplearning.jp/ “Training RNNs as Fast as CNNs” Hiroki Kurotaki, Matsuo Lab
2.
目目次次 • 概要 • 1
Introduction • 2 Method • 3 Related Works • 4 Experiments • 5 Conclusion 2
3.
目目次次 • 概要 • 1
Introduction • 2 Method • 3 Related Works • 4 Experiments • 5 Conclusion 3
4.
書書誌誌情情報報 • Training RNNs
as Fast as CNNs • Tao Lei, Yu Zhang • 9/12/2017(v1: 9/8/2017) • https://arxiv.org/abs/1709.02755v2 • https://github.com/taolei87/sru • Arxiv Sanityで Last monthのtop hype #2 (329 tweets) • 1st authorはICML, EMNLPなどに通している – Deriving neural architectures from sequence and graph kernels 4
5.
提提案案手手法法 • RNNのゲートに前の時間の情報を入れない – 大幅な並列化が可能 •
cuDNNで最適化されたLSTMに比べ、5-10x 速い • PyTorch and CNTKでオープンソース公開 5
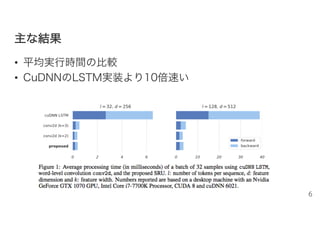
6.
主主なな結結果果 • 平均実行時間の比較 • CuDNNのLSTM実装より10倍速い 6
7.
目目次次 • 概要 • 1
Introduction • 2 Method • 3 Related Works • 4 Experiments • 5 Conclusion 7
8.
11 IInnttrroodduuccttiioonn • 深層学習の研究開発において、実行時間は大きな障害 •
LSTMは並列化の恩恵を最大限に受け取れていない – h_tがh_{t-1}に依存しているため、並列化が不可能 • 依存項をカットした、Simple Recurrent Unitを提案 • CUDAレベルで最適化した実装を公開した – conv2dと同等の速度を達成した 8
9.
目目次次 • 概要 • 1
Introduction • 2 Method • 3 Related Works • 4 Experiments • 5 Conclusion 9
10.
22..11 SSRRUU iimmpplleemmeennttaattiioonn •
ベース:LSTM+頻出のテクニック二つ – Highway connection • 下のh’_tの式。r_tがreset gateと呼ばれるもの – Variational dropout : • 入力x_tに時間で変わらないマスク • 細かいこと – Forget gateは、i = 1-fとする – h_tに普通のdropout – g(・)は活性化関数 10
11.
22..22 SSppeeeeddiinngg--uupp tthhee
rreeccuurrrreennccee • 従来のボトルネック – 隠れ状態の各次元が、他を参照してしまい、並列化が不可能 – h_{t-1}の全体が計算されるまで待たないと、h_tを計算不可 • 提案: ゲートにおける時間t-1の参照をカット – ボトルネックは(3)-(5)の行列計算のみ 11
12.
22..33 CCUUDDAA lleevveell
ooppttiimmiizzaattiioonn • (3)-(5)式の行列演算は一つにまとめる 12
13.
22..33 CCUUDDAA lleevveell
ooppttiimmiizzaattiioonn • 計算が並列化できるようになる 13
14.
目目次次 • 概要 • 1
Introduction • 2 Method • 3 Related Works • 4 Experiments • 5 Conclusion 14
15.
33 RReellaatteedd WWoorrkk •
系列処理の効率化 – Recurrent convolution (RCNN) (Lei et al., 2015, 2016) – kernel network (KNN) (Lei et al., 2017) – Quasi-RNN (Bradbury et al., 2017) • カットによる表現力の減少有無 – 単純化RNNのcapacityの調査(Balduzzi and Ghifary (2016)) – SRUやword-level CNNは、系列類似度関数→隠れ空間の埋め込み (Lei et al. (2017)) 15
16.
目目次次 • 概要 • 1
Introduction • 2 Method • 3 Related Works • 4 Experiments • 5 Conclusion 16
17.
44 EExxppeerriimmeennttss • 提案手法のSRUを、先行研究やCuDNNのLSTM実装と比較 •
SRUの、レイヤーを積み増すバージョンで、 良い精度と速度を出した • 実装は4.5以外PyTorch、4.5はCNTK 17
18.
44..11 CCllaassssiiffiiccaattiioonn • データセット –
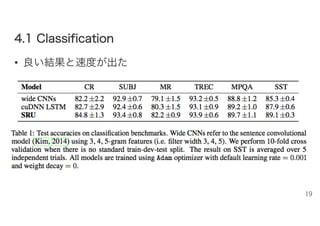
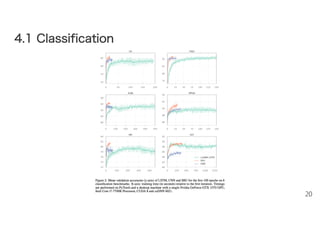
movie reviews (MR) (Pang and Lee, 2005) – subjectivity data (SUBJ) (Pang and Lee, 2004) – customer reviews (CR) (Hu and Liu, 2004) – TREC questions (Li and Roth, 2002) – opinion polarity from MPQA data (Wiebe et al., 2005) – Stanford sentiment treebank (SST) (Socher et al., 2013) • モデル、準備 – 2レイヤー、隠れ128次元 • SSTデータセットでは4レイヤー – CNNでも比較 • (Convolutional neural networks for sentence classification) 18
19.
44..11 CCllaassssiiffiiccaattiioonn • 良い結果と速度が出た 19
20.
44..11 CCllaassssiiffiiccaattiioonn 20
21.
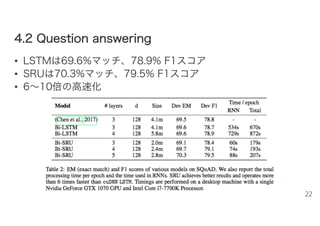
44..22 QQuueessttiioonn aannsswweerriinngg •
データセット – Stanford Question Answering Dataset (SQuAD) (Rajpurkar et al., 2016) • wikipedia からの100,000 QAペア • モデル、準備 – Document Reader model (Chen et al., 2017) • LSTM版とSRU版を作って比較 – 50エポック、32バッチ、隠れ128次元、 – ドロップアウト 入力0.5、SRU0.2、LSTM0.3 21
22.
44..22 QQuueessttiioonn aannsswweerriinngg •
LSTMは69.6%マッチ、78.9% F1スコア • SRUは70.3%マッチ、79.5% F1スコア • 6~10倍の高速化 22
23.
44..33 LLaanngguuaaggee mmooddeelliinngg •
データセット – Penn Treebank corpus (PTB) • 1Mトークン、10k辞書 • truncated BPTTで学習 • モデル、前準備 – truncated BPTTが35エポック、バッチサイズ32、dropout0.75 – 300エポックの訓練 23
24.
44..33 LLaanngguuaaggee mmooddeelliinngg •
Perplexitiesで先行研究やcuDNN LSTMを上回る 24
25.
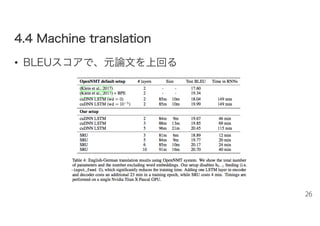
44..44 MMaacchhiinnee ttrraannssllaattiioonn •
データセット – WMT’14 English→German translation – 4Mの翻訳ペア • モデル、前処理 – OpenNMTという翻訳システムをSRUに拡張した – seq2seq w/ attention • h_{t-1}は並列化を妨げるため、次の時間の入力には追加しない – 15エポック、バッチ64、word embeddings size 500 – dropout rateを、よく使われるものより小さい0.1に落とした 25
26.
44..44 MMaacchhiinnee ttrraannssllaattiioonn •
BLEUスコアで、元論文を上回る 26
27.
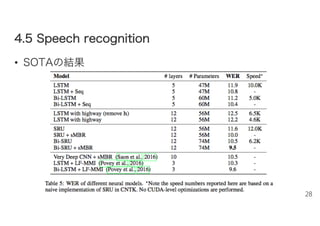
44..55 SSppeeeecchh rreeccooggnniittiioonn •
データセット – Switchboard-1 corpus (Godfrey et al., 1992) • 4,870会話(300時間) 話者520人 • モデルなど – MFCC、Kaldiを使用 – Computational Network Toolkit (CNTK)で実装 27
28.
44..55 SSppeeeecchh rreeccooggnniittiioonn •
SOTAの結果 28
29.
目目次次 • 概要 • 1
Introduction • 2 Method • 3 Related Works • 4 Experiments • 5 Conclusion 29
30.
55 CCoonncclluussiioonn • Simple
Recurrent Unit (SRU)を提案 – ゲートのh_{t-1}参照項をカット • 5つのタスクで性能を確認した • 従来のCuDNNのLSTM実装などに比べ、最大10倍の高速化 – 精度も向上した 30
31.
31
Download
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
“Training RNNs as Fast as CNNs”
Hiroki Kurotaki, Matsuo Lab](https://image.slidesharecdn.com/20171002dlhacks-171002105129/85/DL-Training-RNNs-as-Fast-as-CNNs-1-320.jpg)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
“Training RNNs as Fast as CNNs”
Hiroki Kurotaki, Matsuo Lab](https://image.slidesharecdn.com/20171002dlhacks-171002105129/75/DL-Training-RNNs-as-Fast-as-CNNs-1-2048.jpg)

























![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks 実装] DeepPose: Human Pose Estimation via Deep Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/20170821onodeepposepresentation-170928100207-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Towards an Automatic Turing Test: Learning to Evaluate Dialogue Respo...](https://cdn.slidesharecdn.com/ss_thumbnails/170925dlhackstowardsanautomaticturingtest-170925104902-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks 実装]Network Dissection: Quantifying Interpretability of Deep Visual R...](https://cdn.slidesharecdn.com/ss_thumbnails/171030netdissectimple1-171030120240-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−](https://cdn.slidesharecdn.com/ss_thumbnails/20190415dlhacks-190422075753-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking](https://cdn.slidesharecdn.com/ss_thumbnails/200124dlseminar-200124001212-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/20190125misono-190125024053-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]DropBlock: A regularization method for convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/dlyokota20190222-190222002832-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Face Recognition: A Survey](https://cdn.slidesharecdn.com/ss_thumbnails/20181221-181221023935-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Xception: Deep Learning with Depthwise Separable Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/2017-06-22-170623004409-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]SOLAR: Deep Structured Representations for Model-Based Reinforcement L...](https://cdn.slidesharecdn.com/ss_thumbnails/20190816-190816001737-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL Hacks 実装]The Conditional Analogy GAN: Swapping Fashion Articles on People...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackscaganimplementation-171114051745-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks 実装]Neural Machine Translation in Linear Time](https://cdn.slidesharecdn.com/ss_thumbnails/0925dlhacks-171005051158-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Recurrent Generative Decoder For Abstractive Text Summarization(E...](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dlhacksseki-171106101534-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks 実装]Perceptual Adversarial Networks for Image-to-Image Transformation](https://cdn.slidesharecdn.com/ss_thumbnails/20171017dlhacks-171019082642-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Energy-based generative adversarial networks](https://cdn.slidesharecdn.com/ss_thumbnails/energy-basedgenerativeadversarialnetworks-171030102253-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Opening the Black Box of Deep Neural Networks via Information](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks10161-171027055615-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Direct Reinforcement Learning for Financial Signal Representation...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks171113miyazaki-171114063842-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS](https://cdn.slidesharecdn.com/ss_thumbnails/quasi-recurrentneuralnetworks-170512014332-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ML論文読み会資料] Training RNNs as Fast as CNNs](https://cdn.slidesharecdn.com/ss_thumbnails/ml-171110024905-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DLHacks 実装] The statistical recurrent unit](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackssru0828-170928101102-thumbnail.jpg?width=640&height=640&fit=bounds)






















