NAS-RL [Zoph+, ICLRʼ17]
1.RNNでCNNの各層のハイパーパラメータ(フィルタ数/サイズなど)を出⼒
2. CNNをtraining setで訓練し,validation setでのaccuracyを報酬!とする
3. 報酬!の期待値を最⼤化するようにPolicy gradientでRNNのパラメータを最適化
9
強化学習によるNAS
Controller (RNN)
Train a network with
architecture A and get
validation accuracy 2
Update the controller based on 2
Sample architecture A
AmoebaNet [Real+, AAAIʼ19]
•進化計算法ベースで⾼精度な⽅法の⼀つ(しかし計算コスト⼤)
• NAS-Net [Zoph+, CVPRʼ18]と同じ探索空間
• Mutationによって新しい構造を⽣成
• Hidden state mutation:セル内の⼀つの演算を選択し,それの⼊⼒元をランダムに変更
• Op mutation :セル内の⼀つの演算を選択し,その演算をランダムに変更
21
進化計算法+Cellベース
a. (個体をランダムに選択
b. (個体中最も優れた個体を選択
a〜eの繰返し
…
×
d. 最も古い個体を除外
e. 新しい個体を追加
c. 選択された個体に対して
mutationを適⽤
21.
AmoebaNet [Real+, AAAIʼ19]
•CIFAR-10上でerror rate=3.34, 3150 GPU days
• RLベースの⼿法[Zoph+, CVPRʼ18]は, error rate=3.41, 1800 GPU days
• 収束は進化計算ベースの⽅がRLベースよりも早い
22
進化計算法+Cellベース
CNN全体の構造 Normal cell Reduction cell
進化の様⼦
22.
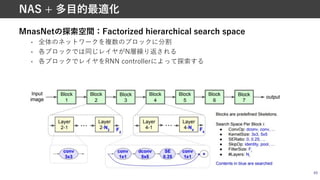
Progressive NAS [Liu+,ECCVʼ18]
• ⼀気に全てのブロックに関して最適化をするのではなく,
徐々にCell内のブロック数$を増やしていきながら,Cellの設計を⾏う
• % = $時の全ての組み合わせを列挙 → LSTMで各組み合わせの性能を予測
→ 上位'個の組み合わせのみ学習 → LSTMの学習 → % ← $ + 1時での
全ての組み合わせ列挙 → …
23
Sequential model-based optimization+Cellベース
sep
3×3
sep
5×5
+
ブロック
Predictor
apply and predict scores
…
until B=5
H = Iで可能な全ての構造
…
H = Iの中でのTop-K
train/finetune
H = I + 1で可能な全ての構造
…
apply and predict scores
23.
Progressive NAS [Liu+,ECCVʼ18]
• 探索空間は基本的にNAS-RLに準拠
• 1種類のCellのみを設計(strideを変えることで解像度を変更)
• CIFAR-10上でerror rate=3.63, 150 GPU days
24
Sequential model-based optimization+Cellベース
獲得されたCell
MnasNet [Tan+, CVPRʼ19]
1.RNNからCNN modelをサンプルし,対象タスクで訓練,性能評価
2. モバイル器上(Pixel Phone)で実⾏し,推論時のlatencyを実際に取得
3. 報酬を計算
4. 報酬を最⼤化するようにRNNのパラメータをProximal Policy Optimizationで更新
50
NAS + 多⽬的最適化
e,E4f0(g) = hii(g) N
jhk g
k
0
g = h
Y, -L ijk(() ≤ k
m, "nℎ/pg-q/
k = 80(q, Y = m = −0.07 を論⽂では使⽤
wはlatencyに関する制約
50.
• MnasNetの探索空間をもとにベースラインとなるアーキテクチャを探索
• EfficientNet-B0
•EfficientNet-B0のdepth, channel数,⼊⼒解像度を調整
• 0 = B>, E = l>, f = m>
• q. n. Y ⋅ m!
⋅ s ≈ 2, Y ≥ 1, m ≥ 1, s ≥ 1
• Y, m, sはグリッドサーチで探索,uはユーザが指定
51
EfficientNet [Tan+, ICMLʼ19]
+を増加
最近EfficientNetV2が提案されました
[Tan+, arXiv2104.00298]
51.
NAS-FPN [Ghaisi+, CVPRʼ19]
•RetinaNetをベースにFeature Pyramid Networkの構造を最適化(NAS-FPN)
• NAS-FPNはN個のmerging cellで構成
• RNN controllerでmerging cell内の以下を決定
• どの⼆つの⼊⼒特徴マップを受け取るか
• Sum or Global pooling
• 出⼒スケール
52
Object detection + NAS
Binary Op
Auto-DeepLab [Liu+, CVPRʼ19]
•NASを利⽤することで,⼈⼿で設計した場合と
同等程度の性能を達成可能
• 探索コストは3 GPU days
• 序盤は⾼解像度,終盤は低解像度での処理を
⾏う過程が獲得されている
55
Semantic segmentation + NAS
55.
56
Adversarial training +NAS [Guo+, CVPRʼ20]
One-shot NASを利⽤して,多数のCNNを⽣成し,
それらCNNのAdversarial attackに対する頑健性を調査
Supernet
…
sampling
Finetuning the network with adversarial
training and evaluate it on eval samples
Subnets
…
…
Finetuning the network with adversarial
training and evaluate it on eval samples
TuNAS [Bender+, CVPRʼ20]
•先の結果は⼩さいデータセットが影響している.探索空間が⼩さい.Tuningが難しいだけ.
• よりeasy-to-tune and scalableなNASとして,TuNASを提案
• ImageNet + ProxylessNASの探索空間では,random searchより優れている
• より⼤きな探索空間でも同様
• WSを調整すれば,ほかのドメインでも良好に動作可能(データセット,タスク)
64
上述の結果への反論
Search space
Complexity of
search space
TuNAS
Random search
w = xy
ProxylessNAS ~10!,
76.3±0.2 75.4±0.2
ProxylessNAS-Enlarged ~10!D 76.4±0.1 74.6±0.3
MobileNetV3-Like ~1031
76.6±0.1 74.6±0.3
Test accuracy on the three search spaces


![所属
• 2017.10 ‒ 現在 理化学研究所 AIP 特別研究員
• 2018.10 ‒ 現在 東北⼤学 助教
2
⾃⼰紹介(菅沼 雅徳)
興味のある研究分野
• コンピュータビジョン
• Neural Architecture Search (NAS)
• Vision and Language
NAS + 画像分類
[GECCOʼ17 (Best paper)]
NAS + 画像復元
[ICMLʼ18, CVPRʼ19]
Vision and Language
[ECCVʼ20, IJCAIʼ21]](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-2-320.jpg)
![0
5
10
15
20
25
30
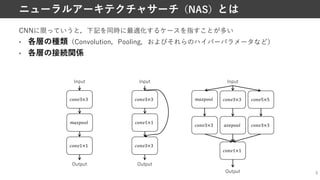
• CNNの成功はアーキテクチャの改良がそれなりに牽引
• 画像分類,物体検出など多くのタスクでも同様の傾向
4
Why NAS?
error
rate
Traditional
CNN
2010 2011
AlexNet
2012 2013
ZFNet VGG
2014 2015
GoogleNet
2016
SENet
2017
ResNet
ImageNet Top 5 Error Rate
CNNのアーキテクチャの改善で
20%以上の性能向上 ResNet [He+, CVPRʼ16]
EfficientDet [Tan+, CVPRʼ20]
year](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-4-320.jpg)
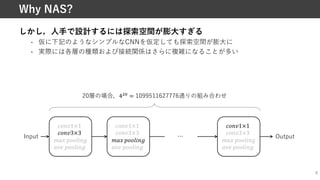
![NASを利⽤することで,⼈⼿でCNNを設計するよりも良好な精度と
パラメータ数(演算量)のパレート解を達成可能
6
NASの性能例
引⽤: EfficientNet [Tan+, ICMLʼ19] 引⽤: EfficientDet [Tan+, CVPRʼ20]
Image classification (ImageNet) Object detection (MS COCO)](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-6-320.jpg)
![8
ざっくりとNASの歴史(CIFAR-10)
0
1
2
3
4
5
6
7
8
0.1 1 10 100 1000 10000
NAS-RL [ICLRʼ17]
Large-scale Evolution [ICMLʼ17]
AmoebaNet [AAAIʼ19]
NASNet [CVPRʼ18]
PNAS [ECCVʼ18]
MetaQNN [ICLRʼ17]
CGPCNN [GECCOʼ17]
ENAS [ICMLʼ18]
P-DARTS [ICCVʼ19]
PC-DARTS [CVPRʼ20]
Search cost (GPU days)
Test
error
rate
DARTS [ICLRʼ19]](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-7-320.jpg)
![NAS-RL [Zoph+, ICLRʼ17]
1. RNNでCNNの各層のハイパーパラメータ(フィルタ数/サイズなど)を出⼒
2. CNNをtraining setで訓練し,validation setでのaccuracyを報酬!とする
3. 報酬!の期待値を最⼤化するようにPolicy gradientでRNNのパラメータを最適化
9
強化学習によるNAS
Controller (RNN)
Train a network with
architecture A and get
validation accuracy 2
Update the controller based on 2
Sample architecture A](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-8-320.jpg)
![NAS-RL [Zoph+, ICLRʼ17]
1. RNNでCNNの各層のハイパーパラメータ(フィルタ数/サイズなど)を出⼒
2. CNNをtraining setで訓練し,validation setでのaccuracyを報酬!とする
3. 報酬!の期待値を最⼤化するようにPolicy gradientでRNNのパラメータを最適化
10
強化学習によるNAS
各層のフィルタのハイパーパラメータ(候補は事前に定義)を
softmaxで推定
探索空間
• Filter height ∈ [1,3, 5,7]
• Filter width ∈ [1,3, 5,7]
• # of filters ∈ [24,36, 48,64]
• Stride ∈ [1,2,3]
• Skip connectionの有無](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-9-320.jpg)
![NAS-RL [Zoph+, ICLRʼ17]
1. RNNでCNNの各層のハイパーパラメータ(フィルタ数/サイズなど)を出⼒
2. CNNをtraining setで訓練し,validation setでのaccuracyを報酬!とする
3. 報酬!の期待値を最⼤化するようにPolicy gradientでRNNのパラメータを最適化
11
強化学習によるNAS
< =# = >$(&!:#;()[2]
∇($
< =#
= @
*+,
-
>$(&!:#;($)[∇ ($
logD )* )*.,:,; =# 2]
RNNの報酬および勾配
各層のフィルタのハイパーパラメータ(候補は事前に定義)を
softmaxで推定
直感的には,⾼い性能を⽰すCNN構造に
⾼い確率を割り当てるようにRNNを更新](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-10-320.jpg)
![• 右図はCIFAR-10上で獲得された構造
• 受容野が⼤きいフィルタが多く使われている
• skip connectionが多い
○ CNN全体を設計可能
× ⼿法の制約上,直列的な構造しか設計できない
× 計算コストの割に,精度がよろしくない
• 22400 GPU daysでerror rate=3.65
12
NAS-RLで獲得されたCNNの例
※ GPU800台使⽤
引⽤: NAS-RL [Zoph+, ICLRʼ17]](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-11-320.jpg)
![Large-scale Evolution [Real+, ICMLʼ17]
• シンプルな遺伝的アルゴリズム (GA)を⽤いた⼿法
• CIFAR-10上でError rate=5.40, 2600 GPU days(※GPU250台使⽤)
13
進化計算法によるNAS
進化の様⼦
引⽤: [Real+, ICMLʼ17]](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-12-320.jpg)
![Large-scale Evolution [Real+, ICMLʼ17]
• 個体(CNN構造)集団からランダムに2つ個体をサンプルし,性能⽐較を⾏い,
性能が良い⽅のCNN構造を変更し(mutation) ,もとの集団に戻す,を繰り返す
• Mutationの例
• Conv層の追加・除去,strideの変更,チャネル数の変更,フィルタサイズの変更
• skip connectionの追加・除去
• 学習率の変更
• 重みの初期化
14
進化計算法によるNAS
current generation next generation
a. 2個体を選択
b. 2個体を⽐較し,
良い⽅を残す
c. 新しい個体を⽣成(mutation)し,
元の個体と⽣成個体を戻す a〜cの繰返し
…
※ validation accuracy](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-13-320.jpg)
![CGPCNN [Suganuma & Shirakawa+, GECCOʼ17]
• CNNの構造をDirected acyclic graph(DAG)で表現し,DAGの情報を整数列で記述
• Validation setでの性能を最⼤化するように,整数列を進化計算法によって最適化
15
進化計算法によるNAS
Convolution
32 output channels
3 3 receptive filed
Max Pooling
2 2 receptive field
Stride 2
Convolution
64 output channels
5 5 receptive field
Convolution
64 output channels
3 3 receptive field
softmax
Summation
1
3 4
2
6
Max Pooling
conv
(32, 3)
1
pool
(max)
2
conv
(64, 3)
4
conv
(64, 5)
3
pool
(max)
5
sum
6
input
0 7
output
DAG
0
(Node no.) 1 2
Function ID 1st input node no. 2nd input node no.
4 5
3 6 7
0 2 1 0 0 3 1 2 2 2 1 1 2 2 4 3 4 O 6
整数列(Genotype) CNN
+
6](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-14-320.jpg)

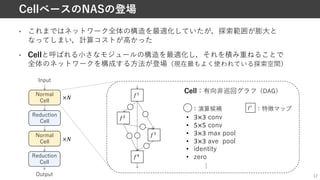
![LSTMでCell内の演算種類および接続関係を決定
1. どの特徴マップを⼊⼒とするか
• 前2つのCellの出⼒(ℎ%, ℎ%&!)もしくはCell内の中間層出⼒
2. 上記で選択された2つの特徴マップに対して
どの演算⼦を適⽤するか
3. どうやって上記2つの出⼒を結合するか
• 要素和もしくはchannel次元で結合
• 上記をH回分出⼒=中間層がH層のCellの設計
• $ = 5のとき,探索空間のサイズ(候補アーキテクチャの総数)は10"'
18
強化学習+Cellベース NAS-Net [Zoph+, CVPRʼ18]
演算候補
• 1×1 conv
• 3×3 conv
• 3×3 separable conv
• 5×5 separable conv
• 7×7 separable conv
• 3×3 dilated separable conv
• 1×7 then 7×1 conv
• 1×3 then 3×1 conv
• 3×3 max pooling
• 5×5 max pooling
• 7×7 max pooling
• 3×3 ave pooling
• identity](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-17-320.jpg)
![LSTMでCell内の演算種類および接続関係を決定
1. どの特徴マップを⼊⼒とするか
• 前2つのCellの出⼒(ℎ%, ℎ%&!)もしくはCell内の中間層出⼒
2. 上記で選択された2つの特徴マップに対して
どの演算⼦を適⽤するか
3. どうやって上記2つの出⼒を結合するか
• 要素和もしくはchannel次元で結合
• 上記をH回分出⼒=中間層がH層のCellの設計
• $ = 5のとき,探索空間のサイズ(候補アーキテクチャの総数)は10"'
19
強化学習+Cellベース NAS-Net [Zoph+, CVPRʼ18]
Cellの例](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-18-320.jpg)
![• フィルタのchannel数はreduction cell時に2倍にする(解像度は1/2)
• LSTMはProximal policy optimizationで最適化
• CIFAR-10上で,error rate=3.41, 1800 GPU days
• CNN全体を設計するNAS-RL [Zoph+, ICLRʼ17]は, error rate=5.40, 2600 GPU days
20
強化学習+Cellベース NAS-Net [Zoph+, CVPRʼ18]
獲得されたReduction Cellの例
獲得されたNormal Cellの例](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-19-320.jpg)
![AmoebaNet [Real+, AAAIʼ19]
• 進化計算法ベースで⾼精度な⽅法の⼀つ(しかし計算コスト⼤)
• NAS-Net [Zoph+, CVPRʼ18]と同じ探索空間
• Mutationによって新しい構造を⽣成
• Hidden state mutation:セル内の⼀つの演算を選択し,それの⼊⼒元をランダムに変更
• Op mutation :セル内の⼀つの演算を選択し,その演算をランダムに変更
21
進化計算法+Cellベース
a. (個体をランダムに選択
b. (個体中最も優れた個体を選択
a〜eの繰返し
…
×
d. 最も古い個体を除外
e. 新しい個体を追加
c. 選択された個体に対して
mutationを適⽤](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-20-320.jpg)
![AmoebaNet [Real+, AAAIʼ19]
• CIFAR-10上でerror rate=3.34, 3150 GPU days
• RLベースの⼿法[Zoph+, CVPRʼ18]は, error rate=3.41, 1800 GPU days
• 収束は進化計算ベースの⽅がRLベースよりも早い
22
進化計算法+Cellベース
CNN全体の構造 Normal cell Reduction cell
進化の様⼦](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-21-320.jpg)
![Progressive NAS [Liu+, ECCVʼ18]
• ⼀気に全てのブロックに関して最適化をするのではなく,
徐々にCell内のブロック数$を増やしていきながら,Cellの設計を⾏う
• % = $時の全ての組み合わせを列挙 → LSTMで各組み合わせの性能を予測
→ 上位'個の組み合わせのみ学習 → LSTMの学習 → % ← $ + 1時での
全ての組み合わせ列挙 → …
23
Sequential model-based optimization+Cellベース
sep
3×3
sep
5×5
+
ブロック
Predictor
apply and predict scores
…
until B=5
H = Iで可能な全ての構造
…
H = Iの中でのTop-K
train/finetune
H = I + 1で可能な全ての構造
…
apply and predict scores](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-22-320.jpg)
![Progressive NAS [Liu+, ECCVʼ18]
• 探索空間は基本的にNAS-RLに準拠
• 1種類のCellのみを設計(strideを変えることで解像度を変更)
• CIFAR-10上でerror rate=3.63, 150 GPU days
24
Sequential model-based optimization+Cellベース
獲得されたCell](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-23-320.jpg)
![• Cellベースにすることで探索空間の削減はできたが,依然として計算コストが⾼い
(⾼い性能を⽰すためには数百〜数千GPU days必要)
• 理由:アーキテクチャのサンプル → スクラッチから学習 → アーキテクチャのサンプル → …
25
さらなる⾼速化:Weight sharing
ENAS [Pham+, ICMLʼ18]
• 探索空間全てを包含する1つのDAG(super net)を⽤意し,アーキテクチャ候補はsuper netの
サブグラフとして表現
• 探索過程でsuper netの重みは再利⽤ =各サブグラフをスクラッチから学習する必要がない
Super net
…
Candidate nets
sampling](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-24-320.jpg)
![26
さらなる⾼速化:Weight sharing
ENAS [Pham+, ICMLʼ18]
• Super netからのサンプリングはLSTMで実施(NASNetと同様)
• ⼊⼒ソースの選択
• 適⽤する演算⼦の選択
1. LSTMによるCNNのサンプリングおよびCNNの学習
2. サンプルされたCNNのValidation accuracyを最⼤化するように
REINFORCEでLSTMの学習
を繰り返す
Input 1
Input 2
sep
5×5
id
+
sep
3×3
avg
3×3
+
block 4
block 3
sep
3×3
sep
5×5
avg
3×3
id
+
LSTM](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-25-320.jpg)
![27
さらなる⾼速化:Weight sharing
ENAS [Pham+, ICMLʼ18]
• 例えば,次のステップで+,- 3×3, /0が選択されたときに,
過去に使⽤した+,- 3×3の重みを再利⽤する
= スクラッチから学習する必要がないため⾼速
• CIFAR-10でerror rate=3.54, 0.45 GPU days
• 論⽂内で使⽤しているセルベースの探索空間は1.3×10,,
• CNN全体の構造も効率的に探索可能(探索空間は1.6×10!0 )
• NAS-Net [Zoph+, CVPRʼ18]はerror rate=3.41, 1800 GPU days
Input 1
Input 2
sep
5×5
id
+
sep
3×3
id
+
block 4
block 3
sep
3×3
sep
5×5
avg
3×3
id
+
)*
LSTM](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-26-320.jpg)
![これまで探索空間が離散で微分不可能なため,対象となるCNNのほかに
SamplerとしてRNNが別途必要であった
28
勾配法によるNAS
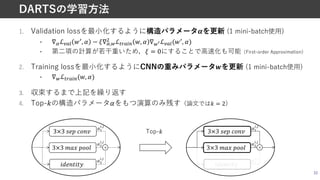
Differentiable Architecture Search (DARTS) [Liu+, ICLRʼ19]
• 探索空間を微分可能にすることでSamplerを必要としない,より効率的かつ
優れたNASを実⾏可能に
• Cellベース+weight sharing+SGDによるNAS.代表的なNAS⼿法の1つ
• CIFAR-10でerror rate=2.76, 1 GPU days
※ 論⽂中の表では4 GPU days(4回探索をした中のベストを選択しているため)
https://github.com/quark0/darts](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-27-320.jpg)
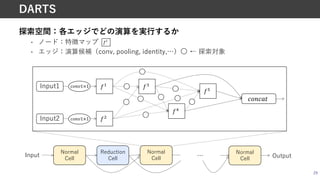

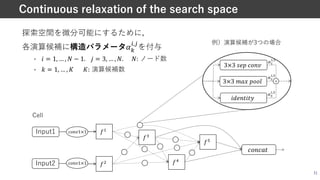
![• Cell内のノード数4での結果例(CIFAR-10上で探索)
• Reduction cellにはNon-learnable operationしか含まれていない
34
DARTSで獲得された構造例
Normal cell Reduction cell
引⽤:DARTS [Liu+, ICLRʼ19]](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-33-320.jpg)
![Test error Params (M)
Search cost
(GPU days)
Method
DenseNet 3.46 25.6 - manual
NAS-Net + cutout [Zoph+, CVPRʼ18] 2.83 3.1 1800 RL
AmoebaNet + cutout [Real+, AAAIʼ19] 2.55 2.8 3150 evolution
PNAS [Liu+,ECCVʼ18] 3.41 3.2 150 SMBO
ENAS + cutout [Pham+, ICMLʼ18] 2.89 4.6 0.5 RL
DARTS (1st order) + cutout [Liu+, ICLRʼ19] 3.00 3.3 1.5 gradient
DARTS (2nd order) + cutout [Liu+, ICLRʼ19] 2.76 3.3 4 gradient
35
性能⽐較
※ DARTSは4試⾏分のSearch cost
• 勾配法で構造も直接最適化することで,効率的かつ優れたCNNの探索が可能
• NASを利⽤することで,⼿動での設計(DenseNet)と⽐べて軽量かつ⾼精度な
モデルの設計が可能](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-34-320.jpg)
![• 学習データへのoverfit
• Skip connectionが過剰に含まれる構造が獲得されやすい
• 探索空間:3×3, 5×5 sep conv, 3×3, 5×5 dilated conv, max/ave pooling, identity, zero
• 構造探索中の性能とテスト時の性能差が⽣じやすい
• メモリ消費が激しい
36
DARTSの使⽤はあまりオススメできない
引⽤: [Zela+, ICLRʼ20]
探索
8 Cell
テスト時
20 Cell
獲得されたCellの例](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-35-320.jpg)
![Robust DARTS [Zela+, ICLRʼ20]
• DARTSが学習データにoverfitしてしまう課題について調査
• DARTSでは探索が進むにつれて,へシアン⾏列∇*
1 ℒ,-.!5の最⼤固有値H6-7
* も増加
→ loss landscapeが急峻になり,汎化性能の低い解に収束(⼤量のskip connectionなど)
37
DARTSの改良:学習データへのoverfit
引⽤: [Zela+, ICLRʼ20]
Hypothetical illustration of loss landscape
異なる探索空間(S1-4)
での検証
2∗: 探索中の構造パラメータ
2"#$%: top-k抽出後の構造パラメータ](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-36-320.jpg)

![Progressive DARTS(P-DARTS) [Chen+, IJCVʼ20]
• DARTSは探索時→テスト時にCellの個数を増加させるが,この操作により,
探索時の最良構造≠テスト時の最良構造 となるケースが存在
• PC-DARTSでは,探索中に徐々にCell数を増加させていくことで,上述の問題を緩和
• Cell増加と同時に,下位の構造パラメータ値Yをもつ演算を除外(8 → 5 → 3)
• Cell内のSkip connection数が2となるように調整
39
DARTSの改良:探索時とテスト時の性能差の抑制
5 Cells 20 Cells
11 Cells 17 Cells
Search phase Test phase
Test error Search cost
(GPU days)
DARTS 3.00 0.5
P-DARTS on
CIFAR-10
2.50 0.3
P-DARTS on
CIFAR-100
2.62 0.3
Test error on CIFAR-10
※ DARTS on CIFAR-100は探索が失敗する](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-38-320.jpg)
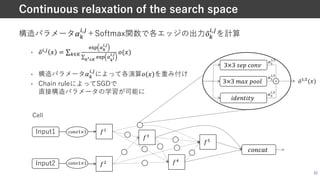
![Partially-connected DARTS (PC-DARTS) [Xu+, ICLRʼ20]
• DARTSは全ての演算候補についてForward/Backward計算を必要とするため,
メモリ消費が激しい
• ⼊⼒特徴マップの⼀部チャネルのみに対して演算を実施することで省メモリ化([:,< ∈ {0,1})
• J!,#
89
K!; M!,# = ∑:∈;
'() *,,.
4
∑
4/∈5
'() *,,.
4/ N 2 M!,# ∗ K! + (1 − M!,#) ∗ K!
40
DARTSの改良:メモリ消費の抑制
Test error Search cost
(GPU days)
DARTS 3.00 0.5
P-DARTS 2.50 0.3
PC-DARTS 2.57 0.1
Test error on CIFAR-10
※ 上記の探索コストは1080Tiを使⽤した結果.
Tesla V100を使⽤すると,PC-DARTSの探索コストは0.06 days.](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-39-320.jpg)
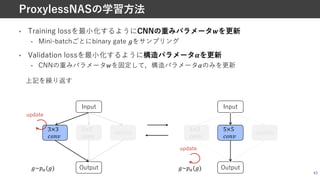
![ProxylessNAS [Cai+, ICLRʼ20]
• これまでの⽅法では,メモリ効率などの観点から⼤規模なデータセット上で
直接構造探索ができず,CIFAR-10など⼩規模データセット(Proxy)上で構造探索し,
Cell数やチャネル数などを増加させて,⼤規模データセットに転⽤させていた
• ProxylessNASでは省メモリ化により,直接⼤規模データセット上での探索を可能に
41
更なるメモリ消費の抑制
Input
3×3
!"#$
5×5
!"#$
identity
Output
Input
3×3
!"#$
5×5
!"#$
identity
Output
DARTS ProxylessNAS](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-40-320.jpg)
![• パスを2値化することで,特定の演算のみを実⾏する
• DARTSは全ての演算結果をメモリに保持する必要があるため,メモリ消費⼤
• 2値化は,構造パラメータBをもとに多項分布からサンプリング
• P = binarize -<, … , -= = X
1,0, … , 0 with probability -<
…
0,0, … , 1 with probability -=
42
ProxylessNAS
Input
3×3
!"#$
5×5
!"#$
identity
Output
Input
3×3
!"#$
5×5
!"#$
identity
Output
+: =
exp Y:
∑; exp Y;
. = [1,0,0] . = [0,1,0]](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-41-320.jpg)
![• ProxylessNASでは,モデルのlatencyも考慮して最適化可能
• '()) = '()))* + ,-[latency]
• ` latency = ∑! `[latency!] = ∑# -#
!
×d(2#
!
)
• 各演算のlatency d(2#
!
)を予測するモデルを別途⽤意
• Google Pixel 1 phoneおよびTensorFlow-Liteを⽤いて構築
• 勾配法ではなく,REINFORCEでも
構造パラメータBを最適化可能
44
ProxylessNASによるlatency考慮した構造設計
Test error Params (M)
DARTS 2.83 3.4
AmoebaNet-B 2.13 34.9
ProxylessNAS-G 2.08 5.7
ProxylessNAS-R 2.30 5.8
Test error rate on CIFAR-10
< Y = c=~7 2 d
= = @
:
+:2(d(/ = "))
1
)はbinary gate2に基づいた2値化されたネットワーク
∇7< Y ≈
1
f
@
:+,
?
2 d=* ∇7log(+(.:
))](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-43-320.jpg)
![• Cellベース+weight sharing+ランダムサーチ [Bender+, ICMLʼ18]
• 構造パラメータもしくはRNNを導⼊しなくとも,ランダムサーチでそれなりに探索可能
• Super netにDropoutを適⽤しながら学習を⾏い,学習終了後にランダムにアーキテクチャを
サンプリングし,validation set上で最良アーキテクチャを選択
• 学習の安定化のために,Dropout ratioのスケジューリング,ghost batch normalizationなど
の⼯夫は必要
45
Weight sharing + ランダムサーチ
引⽤: [Bender+, ICMLʼ18]
Test error
ENAS 3.5
DARTS 2.8
Bender+, ICMLʼ18 3.9
Test error rate on CIFAR-10
※ DARTSと探索空間が若⼲異なっていることに注意](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-44-320.jpg)
![DARTSの探索空間でランダムサーチを実施 [Li+, UAIʼ19]
• Cell内の各ノードにおいて,演算および2つの⼊⼒元をランダムにサンプルし,学習
を繰り返す = super netの学習
• Super netの学習終了後,ランダムにアーキテクチャをサンプルし,0から再学習し,
validation set上での最良モデルを抽出
• 下記表に⽰すように,ランダムサーチでもDARTSと遜⾊ないアーキテクチャを探索可能
46
DARTS + ランダムサーチ
Test error
(Best)
Test error
(ave)
Search cost
(GPU days)
DARTS (2nd order) 2.62 2.78±0.12 10
Random search
with weight sharing
2.71 2.85±0.08 9.7
Test error rate on CIFAR-10
※ Search costはテスト評価⽤の再訓練含む](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-45-320.jpg)
![• DARTS [Liu+, ICLRʼ19] vs ProxylessNAS [Cai+, ICLRʼ20] vs PC-DARTS [Xu+, ICLRʼ20]
• ImageNet50で検証
• ImageNetからランダムに50クラスをサンプリング
• 実験設定は基本的に原著論⽂もしくは著者公開コードに準拠
• ProxylessNASだけうまく探索が進まなかったため,初期学習率および
そのスケジューリングなど調整しました
• 探索の⾼速化のために,Mixed-Precision Trainingを利⽤(https://github.com/NVIDIA/apex)
• GPUはA6000を使⽤
47
実際に動かしてみた
Test error rate
DARTS 14.77
PC-DARTS 12.84
ProxylessNAS 10.76](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-46-320.jpg)
![MnasNet [Tan+, CVPRʼ19]
• Accuracyと処理速度の良好なトレードオフを達成するCNNをNASで設計
• Controller(RNN)の報酬に推論時のlatencyを追加
• ImageNet classificationでMovileNetV2よりも良好なパレート解を獲得可能
48
NAS + 多⽬的最適化
Channel数を増加させたときの性能⽐較 他⼿法との⽐較](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-47-320.jpg)
![MnasNet [Tan+, CVPRʼ19]
1. RNNからCNN modelをサンプルし,対象タスクで訓練,性能評価
2. モバイル器上(Pixel Phone)で実⾏し,推論時のlatencyを実際に取得
3. 報酬を計算
4. 報酬を最⼤化するようにRNNのパラメータをProximal Policy Optimizationで更新
50
NAS + 多⽬的最適化
e,E4f0(g) = hii(g) N
jhk g
k
0
g = h
Y, -L ijk(() ≤ k
m, "nℎ/pg-q/
k = 80(q, Y = m = −0.07 を論⽂では使⽤
wはlatencyに関する制約](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-49-320.jpg)
![• MnasNetの探索空間をもとにベースラインとなるアーキテクチャを探索
• EfficientNet-B0
• EfficientNet-B0のdepth, channel数,⼊⼒解像度を調整
• 0 = B>, E = l>, f = m>
• q. n. Y ⋅ m!
⋅ s ≈ 2, Y ≥ 1, m ≥ 1, s ≥ 1
• Y, m, sはグリッドサーチで探索,uはユーザが指定
51
EfficientNet [Tan+, ICMLʼ19]
+を増加
最近EfficientNetV2が提案されました
[Tan+, arXiv2104.00298]](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-50-320.jpg)
![NAS-FPN [Ghaisi+, CVPRʼ19]
• RetinaNetをベースにFeature Pyramid Networkの構造を最適化(NAS-FPN)
• NAS-FPNはN個のmerging cellで構成
• RNN controllerでmerging cell内の以下を決定
• どの⼆つの⼊⼒特徴マップを受け取るか
• Sum or Global pooling
• 出⼒スケール
52
Object detection + NAS
Binary Op](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-51-320.jpg)
![• NASを利⽤することで,精度・推論速度ともに良好な構造を設計可能
• ⼈⼿で構築したモデルよりも優れたパレート解を獲得できている
53
Object detection + NAS
獲得されたNAS-FPNの例
引⽤: NAS-FPN [Ghaisi+, CVPRʼ19]](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-52-320.jpg)
![Auto-DeepLab [Liu+, CVPRʼ19]
• CellレベルとNetworkレベルの⼆つの探索空間で構成
• Cell : DARTSと同じ
• Network : L層までのパスを探索(解像度を2倍,1/2倍,維持,のいずれかを選択).
各パスに重みm@
A
を割りふる
• 学習⽅法もDARTSと同様
• ネットワークの重みgを更新
• 構造パラメータY, mを更新,を繰り返す
54
Semantic segmentation + NAS](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-53-320.jpg)
![Auto-DeepLab [Liu+, CVPRʼ19]
• NASを利⽤することで,⼈⼿で設計した場合と
同等程度の性能を達成可能
• 探索コストは3 GPU days
• 序盤は⾼解像度,終盤は低解像度での処理を
⾏う過程が獲得されている
55
Semantic segmentation + NAS](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-54-320.jpg)
![56
Adversarial training + NAS [Guo+, CVPRʼ20]
One-shot NASを利⽤して,多数のCNNを⽣成し,
それらCNNのAdversarial attackに対する頑健性を調査
Supernet
…
sampling
Finetuning the network with adversarial
training and evaluate it on eval samples
Subnets
…
…
Finetuning the network with adversarial
training and evaluate it on eval samples](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-55-320.jpg)
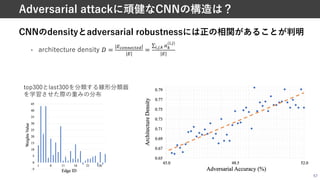
![58
Adversarial training + NAS [Guo+, CVPRʼ20]
Q1. Adversarial attackに頑健なCNNの構造は何なのか?
A1. Densely connected pattern
Q2. パラメータ数に制限がある場合,どのように畳み込み層を配置すべきか?
A2. 少ないパラメータ制約下では,隣接するノード間に畳み込み層を配置
Q3. 統計的に頑健性を計る指標は何が良いか?
A3. Flow of solution procedure (FSP) matrix loss
より詳しい解説はこちら](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-57-320.jpg)

![• DARTS [Liu+, ICLRʼ19], ENAS [Pham+, ICMLʼ18], NAO [Luo+, NeurIPSʼ18],
BayesNAS [Zhou+, ICMLʼ19] をランダムサーチと⽐較
• ランダムサーチ:探索空間はDARTSに準拠し,各ノードで演算と1つの⼊⼒元をランダムに選択.
10個のアーキテクチャをランダムにサンプルし,収束するまでそれぞれを学習.
• 下記表に⽰すように,単純なランダムサーチがNAS⼿法と同等程度の性能を達成可能
→ 探索空間がリッチすぎる or NAS⼿法の探索が失敗している?
60
ランダムサーチ vs NAS
Test error
(Average)
Test error
(Best)
DARTS 3.38±0.23 3.20
NAO 3.14±0.17 2.90
ENAS 3.24±0.10 3.05
BayesNAS 4.01±0.25 3.59
Random 3.52±0.18 3.26
Test error rate on CIFAR-10
• 各⼿法は異なるランダムシードで10回試⾏
• NAS⼿法はvalidation set上での最良モデルを
再訓練し,test set上で評価
• 学習エポック数は全て同じ
[Yu+, ICLRʼ20]](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-59-320.jpg)
![• NASBench-101*にNAS⼿法を適⽤し,探索が良好に実⾏されているのかを検証
• NASBench-101では探索空間の縮⼩を⾏い,探索空間からサンプル可能な全てのアーキテクチャの
性能を記録している(node数7の場合だと,合計で423624個のアーキテクチャが存在)
• NASによって発⾒されたアーキテクチャのrankingを確認することで,探索性能の検証が可能
• どのNAS⼿法も最良のアーキテクチャを発⾒できていないことがわかる
• NAOが良さそうにみえるが,毎回初期poolから最良アーキテクチャが選択されていたため,
探索が良好に⾏われているとは断⾔できない
61
NASの探索性能の検証
Test error
(Average)
Test error
(Best)
Best
ranking
DARTS 7.19±0.61 6.98 57079
NAO 7.41±0.59 6.67 19552
ENAS 8.17±0.42 7.46 96939
Random 9.07±5.84 4.94 -
Test error rate on NASBench (10試⾏)
* Ying+, NAS-Bench-101: Towards Reproducible Neural Architecture Search, ICMLʻ19
[Yu+, ICLRʼ20]](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-60-320.jpg)
![• NASBench-101を使⽤して,Weight sharing(WS)の影響について検証
• WSありで学習,WSなしで学習(ground truth)間の相関を確認
• WSありでは,mini-batchごとにアーキテクチャを⼀様分布からサンプリングして,
200エポック学習
• 上記の学習を10試⾏し,各試⾏で200アーキテクチャをサンプルし,Kendall Tau metricを
算出( [−1.0, 1.0]の値をとり,1.0に近いほどrankingが近いことを⽰す)
• 結果として,Kendall Tau metric=0.195かつ下記表から,WSはモデルサンプリングに悪影響を
与えることがわかる
62
Weight sharingの検証
Test error
(Average)
Test error
(Best)
Best
ranking
NAO 6.92±0.71 5.89 3543
ENAS 6.46±0.45 5.96 4610
Test error rate on NASBench (WSなし)
Test error
(Average)
Test error
(Best)
Best
ranking
7.41±0.59 6.67 19552
8.17±0.42 7.46 96939
WSあり
引⽤:Yu+, Evaluating the search space of neural architecture search, ICLRʻ20
[Yu+, ICLRʼ20]](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-61-320.jpg)
![• 複数のデータセット上でNAS⼿法をランダムサーチと⽐較
• ランダムサーチ:探索空間からランダムにアーキテクチャを8つサンプルし,学習
• NAS:構造探索を8試⾏
• PDARTS以外のNAS⼿法は安定してランダムサーチよりも優れているとは⾔い難い
• ランダムサーチに劣っているケースも⾒られる
63
ランダムサーチ vs NAS(別論⽂) [Yang+, ICLRʼ20]
NAS method CIFAR-10 CIFAR-100 Sport8 MIT67 Flowers102
DARTS 0.32 0.23 -0.13 0.10 0.25
PDARTS 0.52 1.20 0.51 1.19 0.20
ENAS 0.01 -3.44 0.67 0.13 0.47
NAO 0.44 -0.01 -2.05 -1.53 -0.13
Relative improvement over random search (higher is better) 2v = 100×
B##,'-.BCC.',
B##.',](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-62-320.jpg)
![TuNAS [Bender+, CVPRʼ20]
• 先の結果は⼩さいデータセットが影響している.探索空間が⼩さい.Tuningが難しいだけ.
• よりeasy-to-tune and scalableなNASとして,TuNASを提案
• ImageNet + ProxylessNASの探索空間では,random searchより優れている
• より⼤きな探索空間でも同様
• WSを調整すれば,ほかのドメインでも良好に動作可能(データセット,タスク)
64
上述の結果への反論
Search space
Complexity of
search space
TuNAS
Random search
w = xy
ProxylessNAS ~10!,
76.3±0.2 75.4±0.2
ProxylessNAS-Enlarged ~10!D 76.4±0.1 74.6±0.3
MobileNetV3-Like ~1031
76.6±0.1 74.6±0.3
Test accuracy on the three search spaces](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-63-320.jpg)

![• DARTS探索空間からランダムにアーキテクチャを8つサンプルし,それぞれ異なるtraining
protocolで学習
• auxiliary tower, droppath, cutout, AutoAugment, larger training epoch, increase the
number of channels,を適⽤
• 重要度:学習⽅法>アーキテクチャ (※ 今回の実験設定では)
66
学習⽅法およびハイパーパラメータの重要性 [Yang+, ICLRʼ20]](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-65-320.jpg)
![• 探索空間の拡⼤
• Transformerへの適⽤
• MLPの再来
• ハイパーパラメータ最適化との融合・協調
• 探索空間の⾃動設計
• Large-scale Evolution [Real+, ICMLʼ17]で取り組まれているが,
精度および計算コストが微妙
• NASに費やすコストを⼤規模データセットおよび学習に
費やしたほうが良い?
• Self-supervised learning, Contrastive learning
• Understanding robustness of ViT [Bhojanapalli+, arXiv2103.14586]
• Randomly wired NN [Xie+, ICCVʼ19]
67
今後の展望](https://image.slidesharecdn.com/20210529nassuganuma-210529022656/85/0-NAS-66-320.jpg)


![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0804-170803075139-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/20190125misono-190125024053-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Dl輪読会]dl hacks輪読](https://cdn.slidesharecdn.com/ss_thumbnails/dldlhacks-161125051944-thumbnail.jpg?width=640&height=640&fit=bounds)