More Related Content

PDF
【論文紹介】Seq2Seq (NIPS 2014) ![[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20190119dljournalclubweb-190401063633-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning ![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De... 
PDF
![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,... 
PDF
SchNet: A continuous-filter convolutional neural network for modeling quantum... 
PDF
KDD Cup 2021 時系列異常検知コンペ 参加報告 
PDF
Disentanglement Survey:Can You Explain How Much Are Generative models Disenta... What's hot
![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Neural Ordinary Differential Equations 
PDF

PDF
汎用ニューラルネットワークポテンシャル「PFP」による材料探索_MRS-J2021招待講演_2021/12/15 
PPTX
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models 
PDF
Deep learningの発展と化学反応への応用 - 日本化学会第101春季大会(2021) 
PPTX
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021) 
PDF

PDF
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜 ![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF

PDF
Layer Normalization@NIPS+読み会・関西 
PDF
機械学習によるハイスループット 第一原理計算の代替の可能性_日本化学会_20230323 
PDF
【DL輪読会】Patches Are All You Need? (ConvMixer) 
PDF

PDF

PDF

PDF

PDF
深層学習の判断根拠を理解するための 研究とその意義 @PRMU 2017熊本 
PDF

PPTX
Similar to Paper: seq2seq 20190320

PDF
LSTM (Long short-term memory) 概要 
PDF
Recurrent Neural Networks 
PDF
再帰型ニューラルネット in 機械学習プロフェッショナルシリーズ輪読会 
PDF

PDF
Learning to forget continual prediction with lstm 
PDF

PPTX
Generating Better Search Engine Text Advertisements with Deep Reinforcement L... 
PDF
TensorFlow math ja 05 word2vec 
PDF
RNN-based Translation Models (Japanese) 
PDF

PDF

PDF

PDF

PPTX
論文紹介:「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」 
PDF
Semantic_Matching_AAAI16_論文紹介 
PDF

PDF
20181123 seq gan_ sequence generative adversarial nets with policy gradient 
PPTX

PDF

DOCX
More from Yusuke Fujimoto

PPTX
Tensor コアを使った PyTorch の高速化 
PPTX
Paper: Objects as Points(CenterNet) 
PPTX
Paper: Bounding Box Regression with Uncertainty for Accurate Object Detection 
PDF
Paper LT: Mask Scoring R-CNN 
PPTX
Paper: clinically accuratechestx-rayreport generation_noself 
PPTX
論文LT会用資料: Attention Augmented Convolution Networks Recently uploaded

PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版 
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望 
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf 
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S... 
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信 
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard 
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector 
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis 
PDF
PMBOK 7th Edition Project Management Process Scrum 
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development 
PDF
PMBOK 7th Edition_Project Management Context Diagram 
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」 
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研) Paper: seq2seq 20190320
- 1.
論文輪読会 #20
Sequence toSequence Learning with
Neural Networks
(https://arxiv.org/abs/1409.3215) 2019/03/19
藤本裕介
- 2.
Agenda
事前知識
この論文について
LSTM
Deep-LSTM
用語整理
Paper
0. Abstract
1. Introduction
2. The model
3. Experiments (一部)
4. Related work
5. Conclusion
1
- 3.
事前知識:この論文について
当時(2014年) Google翻訳のアップグレードで話題になった
機械翻訳の主流を変えた
従来 :統計的機械翻訳 (SMT, Statistical Machine Translation)
本論文以降:ニューラル機械翻訳 (NMT, Neural Machine Translation)
http://deeplearning.hatenablog.com/entry/neural_machine_translation_theory
LSTM が流行るきっかけの1つ
系列データを扱うなら始めに候補に挙げておくくらいには流行ってるような…
画像系にも応用されている(ConvLSTM 等)
2
- 4.
事前知識:LSTM
LSTM(Long ShortTerm Memory)
https://upload.wikimedia.org/wikipedia/commons/3/3b/The_LSTM_cell.png
σ を通すと 0~1 の値になる -> 忘却度合いとかを表す
3
- 5.
事前知識:LSTM
LSTM(Long ShortTerm Memory)
https://upload.wikimedia.org/wikipedia/commons/3/3b/The_LSTM_cell.png
それまでの記憶を、ほどよく忘れてほどよく憶えてるイメージ
4
O: output ゲート
tanh(Ct) の各要素について、次時刻の
隠れ状態としてどれだけ重要かを調整
f: forget ゲート
不要な記憶を忘れる
ためのゲート
i: input ゲート
g の各要素に対し、C に
追加する情報として
価値があるのか判断
g: 新しく記憶する情報
新しく情報を追加するので tanh(値域が (-1, 1))
Ct: 記憶セル
LSTM 内部だけで完結するので
他の層に受け渡さない
(実装だと private なインスタンス変数)
ht: 隠れ層
通常の層と同じく他の層に渡す
- 6.
事前知識:LSTM
LSTM(Long ShortTerm Memory)
記憶セル C については、次の C までにアダマール積と足し算しか行われない
誤差逆伝搬時の足し算とアダマール積をしている箇所の勾配
足し算 : 流れてきた勾配をそのまま流す
アダマール積 : forget ゲートで忘れるべきでないと判断された要素は消失せずに流れる
上記の結果勾配消失が起きづらい(らしい)
5
f: forget ゲート
不要な記憶を忘れる
ためのゲート
- 7.
事前知識:Deep LSTM
Deepな LSTM (4層・イメージ図)[2]
c と h の上下が逆であることに注意
6
LSTM
LSTM
LSTM
“A”
LSTM
LSTM
LSTM
LSTM
“B”
LSTM
LSTM
LSTM
LSTM
“EOS”
LSTM
Softmax
“α”
LSTM
LSTM
LSTM
LSTM
Softmax
“β”
“α”
LSTM
LSTM
LSTM
LSTM
Softmax
“EOS”
“β”
h
c
- 8.
事前知識:用語整理
phrase-based SMT
Statistical Machine Translation
“原言語を与えた時に対訳の尤度が最大となる確率モデルを学習して
目的言語に翻訳するシステムを指す”
http://deeplearning.hatenablog.com/entry/neural_machine_translation_theory
ニューラル機械翻訳 (NMT, Neural Machine Translation) に対し、確率モ
デルに NN を使っていないものを主に指す
BLEU
BiLingual Evaluation Understudy
0 ~ 1 で高いほどよい
http://unicorn.ike.tottori-u.ac.jp/2010/s072046/paper/graduation-
thesis/node32.html
7
- 9.
0. Abstract
大規模なラベル付データセットではDNN はうまく機能する
しかし文から文へのマッピングには使えなかった
本稿では 2種類の多層 LSTM を使った
1: 入力文を固定次元のベクトルにマッピングする LSTM
2: ベクトルから対象言語の文にデコードする LSTM
WMT’ 14 dataset で成果出た (BLEU score 34.8)
English -> French タスク
phrase-based SMT システムでは 33.3
上記 SMT システムによって出力された 1000 個の仮説?をLSTM によっ
て再ランク付けすると、36.5 に増加
具体的には後述されている?
これは当時の SOTA に近いスコア
8
- 10.
0. Abstract
LSTMは語順に対して鋭敏(語順で意味が大きく変わる等)
句や文の表現を学習した
またこの表現は能動態(active voice)や受動態(passive voice)に
対して不変
能動態: 主語 + 動詞 + 目的語[※1]
受動態: 主語 + Be動詞 + 過去分詞 + by (能動態の主語) [※1]
例: 「私はこの論文を読んだ」≒「この論文は私に読まれた」
入力文を逆順にして学習すると LSTM の精度が劇的に向上す
ることを発見した
上記の操作により入力文と対象文の間の短い区間での依存関係
(short term dependencies)が多くもたらされたため
上記によって最適化問題が簡単になった
2つめの LSTM は sequence vector と 一つ前の対象文の単語から次の
単語を出力するので、最初の単語が大事っぽい?
9[※1] https://www.kaplaninternational.com/jp/blog/active-passive-voice
- 11.
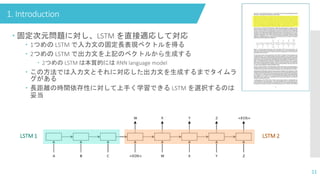
1. Introduction
10
DeepNeural Networks(DNNs) は強力な機械学習モデル
並列計算可能、表現力高い
ラベル付きデータが十分な情報を持っていれば、大きい DNN も 教師
付き backpropagation によって学習可能
したがって良い結果を達成できる DNN のパラメータが存在すれば、
教師付き backpropagation はパラメータを見つけられる
ただし、DNNは 入力とターゲット文を固定次元のベクトルに
エンコードできる問題にしか適用できない -> 強い制限
系列問題において系列長は事前に分からないことが多いため
音声認識や機械翻訳も系列問題
質疑応答は、質問文を回答文にマッピングする問題ともみれる
ドメインに依存せずに系列から系列へのマッピングを学習する方法は
有用
- 12.
1. Introduction
11
固定次元問題に対し、LSTMを直接適応して対応
1つめの LSTM で入力文の固定長表現ベクトルを得る
2つめの LSTM で出力文を上記のベクトルから生成する
2つめの LSTM は本質的には RNN language model
この方法では入力文とそれに対応した出力文を生成するまでタイムラ
グがある
長距離の時間依存性に対して上手く学習できる LSTM を選択するのは
妥当
LSTM 1 LSTM 2
- 13.
1. Introduction
12
達成したスコアと既存baseline との比較
BLEU score of 34.81
ensemble of 5 deep LSTMs
384M parameters and 8,000 dimensional state each
参考: VGG16 のパラメータ数が約 138M
using a simple left-to-right beam search decoder
beam search ? -> 後述
大きい NN による direct translation ではすごく良い結果
一方 SMT システムによるスコア baseline は 33.30
上記の LSTM によるスコアは語彙数 80k
評価対象文がこの 80k 個に含まれない語彙を含んでいる場合
→ BLEU score が下がる
80k は小規模(らしい)
まだ最適化の余地がある(unoptimized) -> 語彙数やどの語彙を選ぶか?
最適化の余地を残しつつも phrase-based SMT system を超えているので
LSTM base が優れていることを確認できる
- 14.
1. Introduction
13
“1000-bestlists of the SMT baseline” に対し LSTM を使ってリス
コアしたらスコアが 33.3 -> 36.5 に改善
既存モデルのベストスコアが 37.0 なのでそれに近い
LSTM は長文に苦戦しなかった
これまでの類似の研究をしてる人は苦戦した経験がある
入力文の語順を逆にした影響が大きい
出力文の語順はそのまま
それにより最適化問題を簡単にする短期的な依存関係を増やせたため
section 2 と 3 で触れます
そのおかげで SGD で問題なく学習できた
この論文の key technical contribution の1つ
- 15.
1. Introduction
14
LSTMは入力文の固定次元へのマッピングを学習する
翻訳は元の文の言い換えであることが多い
違う場合がある?(個人的疑問)
翻訳を目的とした場合、LSTM が文章の意味表現(固定次元ベ
クトル)を獲得することを後押しする
意味が似ているなら近い、意味が違うなら遠い
結果として意味表現を得たという部分は word2vec に似ている?
この後の定性的評価で確認した
特に能動態と受動態に対しロバストであることを確認した
- 16.
2. The model
15
Recurrent Neural Network (RNN) は系列生成の自然な一般化モデ
ル
Input: (x1, x2, ... , xT )
Output: (y1, y2, ... , yT )
長さが一緒であることに注意
RNN は入力文と出力文の対応が単純な場合は有効
長さが同じ
入力文の単語と出力文の単語が 1on1 対応等
長さが違ったり対応が複雑である場合は難しい
直前の隠れ状態
を使っている
- 17.
2. The model
16
RNN で一般的な系列問題に対応するためには…
2つの RNN(RNN1 と RNN2) を使って下記 2step
step1: RNN1 で入力文を固定次元ベクトルにマッピング
step2: RNN2 で固定次元ベクトルから出力文をマッピング
原理的には全ての関連情報が RNN に与えられているのでうま
く学習できるはず
しかし RNN では長期的な依存関係を学習しづらい
-> LSTM !
- 18.
2. The model
17
LSTM のゴール = p(出力文 | 入力文) を求める
下記のように条件付き確率を定式化
入力文の表現ベクトルを最初の隠れ状態とした LSTM-Language Model
を構成する
各単語の確率は語彙数次元の softmax で表現される
加えて文章の終わりとして “<EOS>” という語彙も追加した
fig1(スライド p.9) の例
入力: “A”, “B”, “C”, “<EOS>”
出力: “W”, “X”, “Y”, “Z”, “<EOS>”
この定式化では LSTM は 1つでも良い想定
入力文と長さが
違う可能性あり
入力文の表現
ベクトル
- 19.
2. The model
18
実際に使ったモデルは以下の違いがある
1: 2種類の LSTMs を使った
モデルのパラメータを増やしても計算コストがあまり増えないため
同時に複数の言語ペアを自然に学習できるため(?)
2: deep な LSTMs を使った
shallow LSTMs より精度良かった
“so we chose an LSTM with four layers”
3: 入力文の語順を逆にした
例
“a, b, c” を “α, β, γ” と翻訳したい場合
LSTM には “c, b, a” を “α, β, γ” にマッピングするように要求する
上記の例では “a” と “α” が近接
入力単語と出力単語の平均距離は変わらない
このおかげで SGD は入力文と出力文の間の “やりとりを確立” しやすく
なった
(個人所感): LSTM-LM も最初らへんの単語が大事なので、まずはそこをしっか
り出力するように学習することで最初以降の単語も学習しやすそう
- 20.
3. Experiment (Datasetdetails)
19
実験は 2通りの方法で行った
1. SMT システムの出力を参考にせずに直接翻訳
2. SMT システムの出力を rescore
3.1 Dataset details
WMT’14 English to French dataset
train
12M sentences
348M French words and 304M English words
test
1000-best lists from the baseline SMT
語彙数について(softmax 等で固定次元にする必要あり)
入力文(English) からは頻出 160,000 語彙
出力文(French) からは頻出 80,000 語彙
上記に属さない単語は全て “UNK” とした
- 21.
3. Experiment (Decodingand Rescoring)
20
訓練時は下記の最大化を目的関数として学習
予測(翻訳文生成)時は下記の式を満たすような文を探す
1単語ずつ最も確率が高い単語を選べばよいのでは?
→ 各単語が独立に生成されているわけではないのに?
どうやって探すのか(単純なクラスとは探索範囲がかなり違う)
文長を固定しても、探索範囲は語彙数^文長 (例: 80,000 の 5乗)
実際には文長は固定していないので事実上無限
→ “simple left-to-right beam search decoder” で解決
いい感じに単語を順番に生成する方法
出力時に softmax を通した分布を得
られるけど、そこで出力を “w” に
確定してしまってよいのか?🤔
- 22.
3. Experiment (Decodingand Rescoring)
21
beam search (ビーム探索)[1]
近似的探索法の1つ
解きたい問題(今回は最大値をとる単語列の探索)を部分問題に分割各
部分問題を解いていく
最初の単語から順番に1単語ずつ選んでいくイメージ
各順に最適な単語を選んでも最適解にならない可能性がある
他に系列変換モデルで用いられるのは貪欲法(greedy algorithm)
各部分問題の評価値がもっとも高いものを1つ選択する
ビーム探索では、事前に決めた上位 K個の候補を保持しつつ処理を進
める(K は beam size) にあたる
貪欲法はビーム探索の特殊な場合(K=1) とも考えられる
時刻 j (左から数えて j 番目の単語) の予測において、位置1から j まで
の累積生成確率が探索範囲内で上位 K 個の予測結果を出力候補として
保持する
貪欲法より精度が高いが K 倍の計算コスト
- 23.
- 24.
3. Experiment (Decodingand Rescoring)
23
beam size について
beam size = 1 でも上手く機能した
beam size = 2 が最も利点があった
5 LSTMs with a beam size 2 の方が single LSTM with a beam size 12 より
cheaper(計算コスパが良い?)
加えて LSTM で baseline system の 1000-best lists を rescore した
全ての hypothesis について log probability とって LSTM の hypothesis か
らとったものと平均して new score とした
- 25.
3. Experiment (Reversingthe Source Sentences)
24
入力文を逆順にしたら精度がかなり高くなったのを発見した
どうしてこうなるのか完全な説明できない
短期的な依存関係を多く学習に導入できたためだと思われる
入力文と対象文をただ concat すると、入力文の各単語と対象文の各単
語の距離は長くなる
“minimal time lag” が起きている
今回これは調べてないです
ただし入力文を逆順にすると、平均距離は変わらないが、最初の数単
語の距離は短くなる
→ “minimal time lag” が減少
誤差伝搬が楽になる
当初は文の前半は良くなって後半は悪くなると思ってた
全体で精度良くなった
- 26.
4. Related work
25
これまで見た中で簡単で効果的な方法は NNLM ベース
RNN-Language Model (RNNLM)
Feedforward Neural Network Language Model (NNLM)
改良版 NNLM
Topic model と組み合わせて精度向上(Auli et al.)
Devlin らは上記にさらに色々加え、高い精度を実現
NNLM を MT システムのデコーダに組み込む
デコーダのアライメント情報を使うことで、入力文中で有用な単語をを
NNLM に与えるようにした
- 27.
4. Related work
26
本研究は Kalchbrenner and Blunsom の手法に近い
一度入力文をベクトルにマッピングして出力文をマッピング
ただし CNN でベクトルにマッピングしてたので語順の情報を失った
Cho らは LSTM-like な RNN を使ったが、あくまで SMT システムに組み
込むためだった
Bahdanau らは Cho らの手法に対し Attention (注意機構)を使って長文に
おける性能を改善した
Pouget-Abadie らは Cho et らの手法に対して部分的に翻訳をすること
でスムーズな翻訳を生成しようとした
上記手法に対しても、入力文を逆順にするだけで改善する可
能性を感じてる
Hermann らは end-to-end で入力文と出力文を空間内の座標に
マッピングするモデルを考えた
しかしマッピングするだけ
翻訳するには一番近い点を探すか、rescore する必要があった
- 28.
5. Conclusion
27
従来のSMT-based system を超えた
入力文を逆順にすると精度がかなり良くなった
short term dependencies(短い区間での依存関係) が増えて、最適化が簡
単になったと思われるため
おそらく RNN での良くなることが想定される(本稿では試してない)
LSTM は非常に長い文章に対しても翻訳能力が高い
単純で直接 Seq2Seq できるモデルにも関わらず、既存のSMT
をベースとしたシステムより良かった
- 29.
- 30.






![事前知識:Deep LSTM
Deep な LSTM (4層・イメージ図)[2]
c と h の上下が逆であることに注意
6
LSTM
LSTM
LSTM
“A”
LSTM
LSTM
LSTM
LSTM
“B”
LSTM
LSTM
LSTM
LSTM
“EOS”
LSTM
Softmax
“α”
LSTM
LSTM
LSTM
LSTM
Softmax
“β”
“α”
LSTM
LSTM
LSTM
LSTM
Softmax
“EOS”
“β”
h
c](https://image.slidesharecdn.com/seq2seq20190320-190620034320/85/Paper-seq2seq-20190320-7-320.jpg)


![0. Abstract
LSTMは語順に対して鋭敏(語順で意味が大きく変わる等)
句や文の表現を学習した
またこの表現は能動態(active voice)や受動態(passive voice)に
対して不変
能動態: 主語 + 動詞 + 目的語[※1]
受動態: 主語 + Be動詞 + 過去分詞 + by (能動態の主語) [※1]
例: 「私はこの論文を読んだ」≒「この論文は私に読まれた」
入力文を逆順にして学習すると LSTM の精度が劇的に向上す
ることを発見した
上記の操作により入力文と対象文の間の短い区間での依存関係
(short term dependencies)が多くもたらされたため
上記によって最適化問題が簡単になった
2つめの LSTM は sequence vector と 一つ前の対象文の単語から次の
単語を出力するので、最初の単語が大事っぽい?
9[※1] https://www.kaplaninternational.com/jp/blog/active-passive-voice](https://image.slidesharecdn.com/seq2seq20190320-190620034320/85/Paper-seq2seq-20190320-10-320.jpg)










![3. Experiment (Decoding and Rescoring)
21
beam search (ビーム探索)[1]
近似的探索法の1つ
解きたい問題(今回は最大値をとる単語列の探索)を部分問題に分割各
部分問題を解いていく
最初の単語から順番に1単語ずつ選んでいくイメージ
各順に最適な単語を選んでも最適解にならない可能性がある
他に系列変換モデルで用いられるのは貪欲法(greedy algorithm)
各部分問題の評価値がもっとも高いものを1つ選択する
ビーム探索では、事前に決めた上位 K個の候補を保持しつつ処理を進
める(K は beam size) にあたる
貪欲法はビーム探索の特殊な場合(K=1) とも考えられる
時刻 j (左から数えて j 番目の単語) の予測において、位置1から j まで
の累積生成確率が探索範囲内で上位 K 個の予測結果を出力候補として
保持する
貪欲法より精度が高いが K 倍の計算コスト](https://image.slidesharecdn.com/seq2seq20190320-190620034320/85/Paper-seq2seq-20190320-22-320.jpg)
![3. Experiment (Decoding and Rescoring)
22
beam search (ビーム探索)の擬似コード[1]](https://image.slidesharecdn.com/seq2seq20190320-190620034320/85/Paper-seq2seq-20190320-23-320.jpg)






![参考資料
29
[0] 元論文(https://arxiv.org/abs/1409.3215)
[1] 深層学習による自然言語処理
[2] ゼロから作る Deep Learning② 自然言語処理編](https://image.slidesharecdn.com/seq2seq20190320-190620034320/85/Paper-seq2seq-20190320-30-320.jpg)