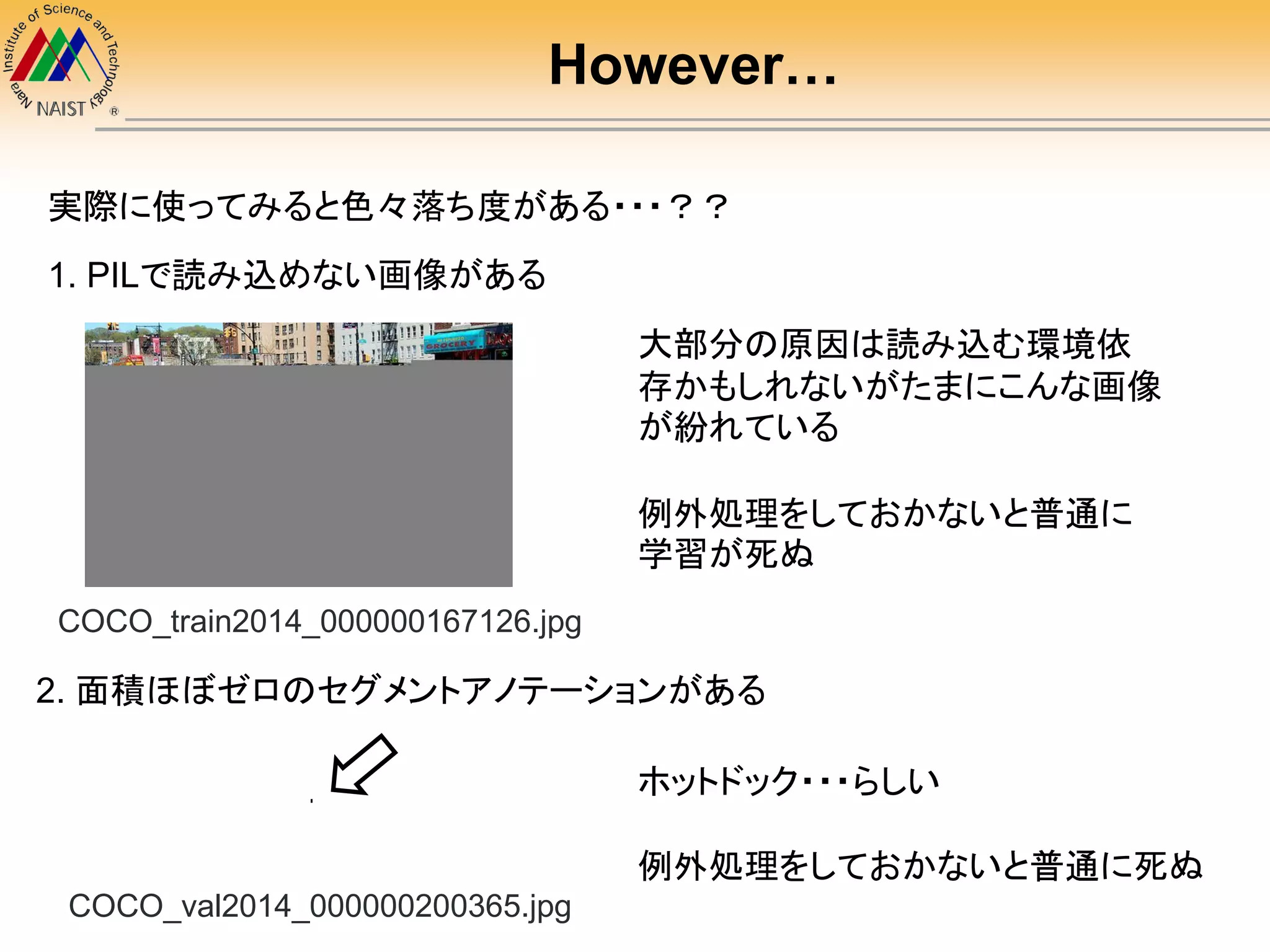
キャプションの実例(validationから)
最初が大文字、ピリオド A womanstanding in a kitchen preparing tea.
全部小文字(理想的) a woman wearing a hat holding onto an umbrella
全部大文字 A MAN OPENING A DOOR TO AN OVEN IN A
RESTAURANT KITCHEN
最初にスペース A man riding his bike with his dog in the side kick seat
どうしようもないケース a corner of a bathroom shows part of a vanity and the
commode sits of the other side of the wa]]
キャプションを前処理なく使うのは自殺行為
最初が大文字、小文字、ピリオドがあるない、全て大文字、など表記ゆれが
結構ひどい
最後のは wall がwa]] となっていて笑う
悪いことは言わない、前処理に
coco-caption API のPTBTorknizer in Stanford CoreNLPを使おう
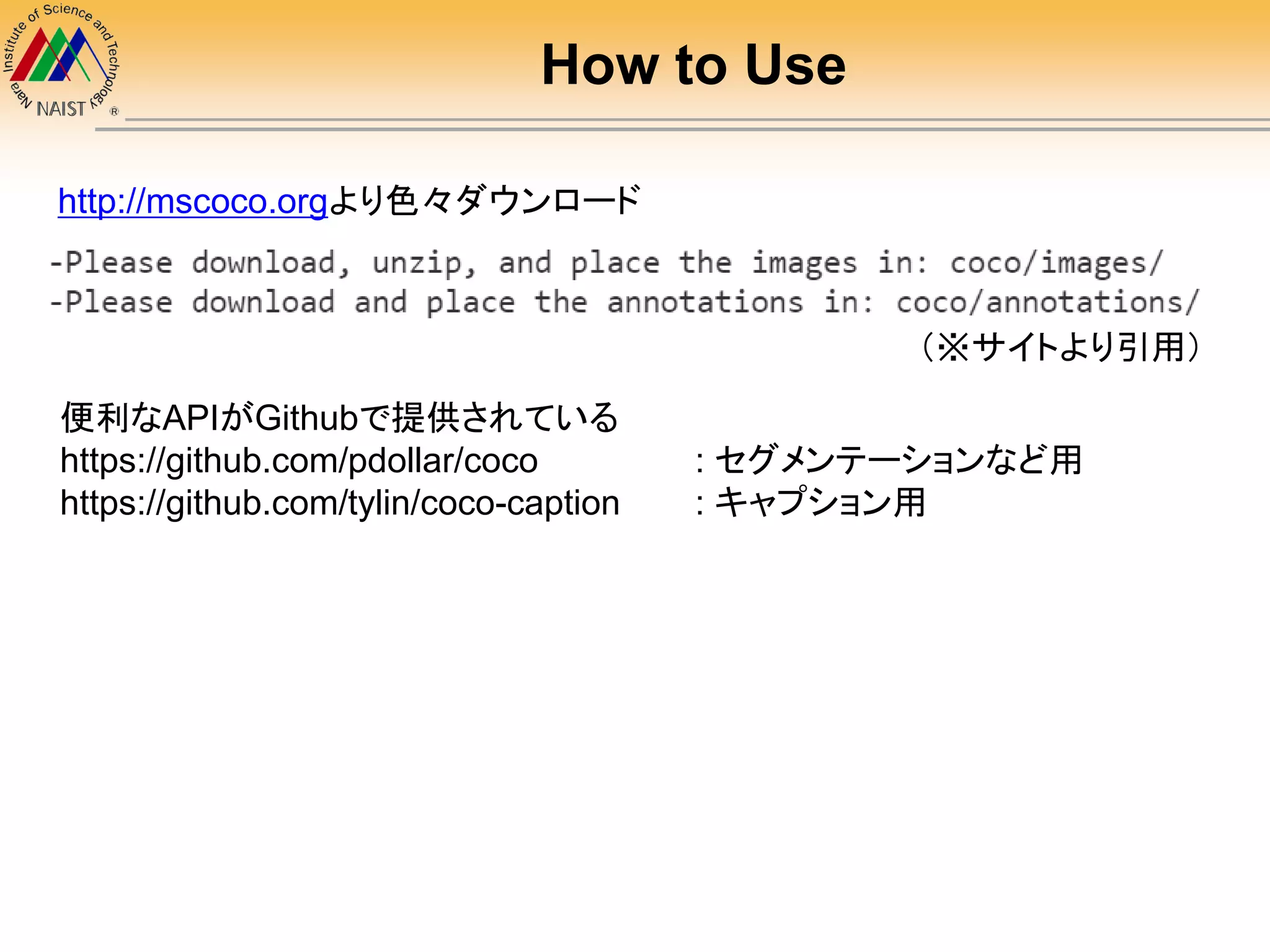
However…
Caption Evaluation
coco-caption APIには
BLEU,METEOR, ROUGE-L, CIDErによる自動評価尺度が
用意されている
必要なもの・・・生成したキャプションと対応する画像idの組
(データセット内の任意の数)をdumpしたjsonファイル
[{“image_id”: 404464, “caption”: “black
and white photo of a man standing in
front of a building”}, {“image_id”:
380932, “caption”: “group of people are
on the side of a snowy field”},
{“image_id”: 565778, “caption”: “train
traveling down a train station”}, … ]
(coco-caption/results/captions_val2014_fakecap_results.json)
http://arxiv.org/abs/1504.00325
BLEU
仮説(生成した文)とリファレンスのN-gramの一致率による評価尺度
N-gram : 局所的な単語の塊、Nは塊あたりの単語数
例:I have a pen .
N N-gram 語彙数
1 I have a pen . 5
2 I have a pen . 4
3 I have a pen . 3
4 I have a pen . 2
I, have, a, pen, .
の5つ
I have, have a, a pen, pen .
の4つ
I have a, have a pen, a pen .
の3つ
I have a pen, have a pen .
の2つ
N-gramの一致率が高いほど良い仮説を生成しているだろうという仮定がある
(高いほど良い)
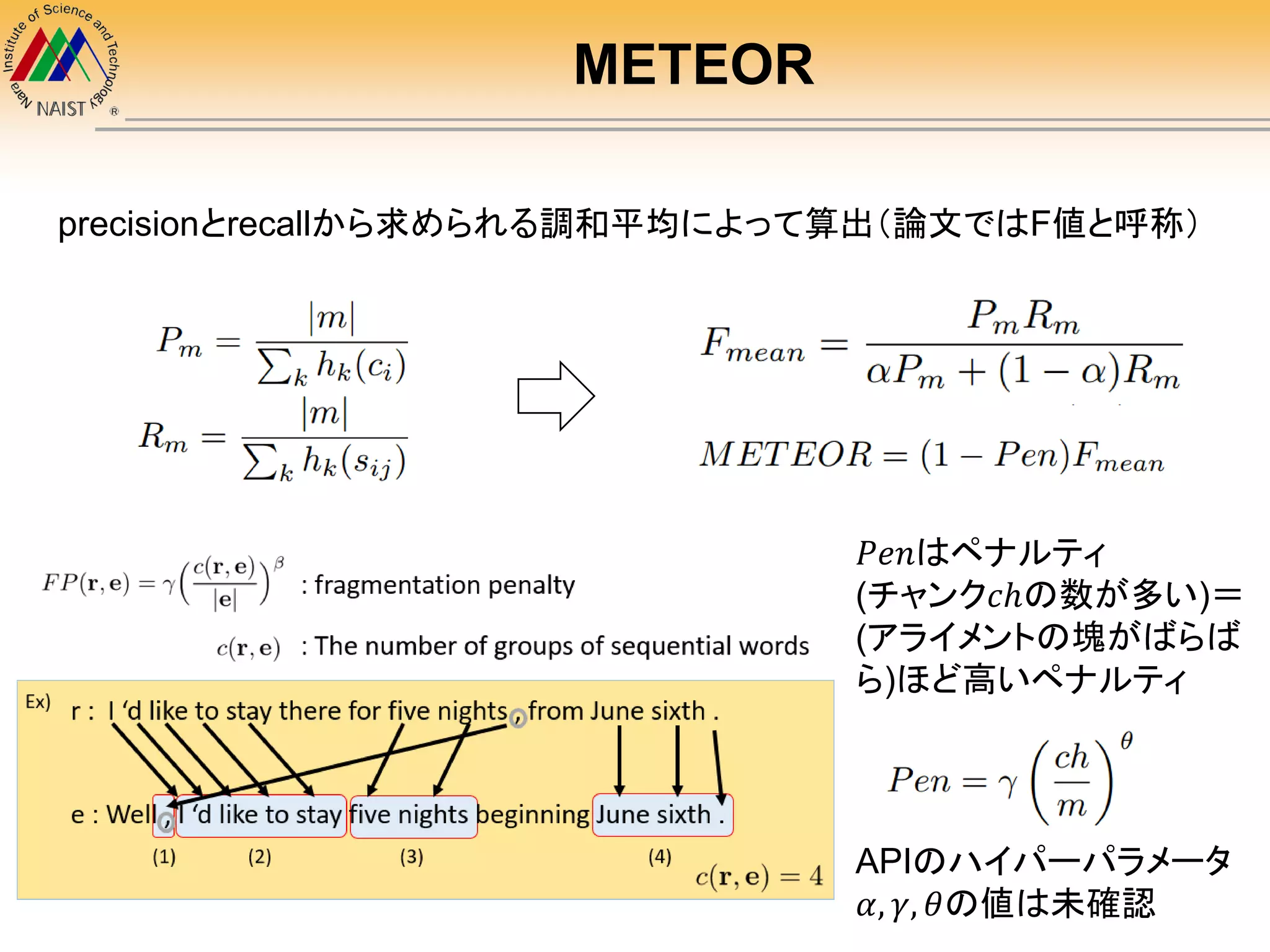
ROUGE
(亜種)𝑅𝑂𝑈𝐺𝐸𝑠 : basedon the skip bi-grams
skip bi-gram : 飛び越しありのbi-gram
例: I have a pen . bi-gram
I have
have a
a pen
pen .
skip bi-gramで追加される語彙
I a, I pen, I .
have pen, have .
a .
Iとの組み合わせ
語彙数(文中の単語数をWとする)
bi-gram : W-1
skip bi-gram : 𝑊∁2
あとは𝑅𝑂𝑈𝐺𝐸 𝑁と似た方法でrecallとprecisionから算出
(ただし、計算量が増えるのでAPIでは飛
び越しは3つまでに制限されている)


![MS COCO API
フィルター条件を満たすアノテーションIDをゲット
フィルター条件を満たすカテゴリIDをゲット
フィルター条件を満たす画像IDをゲット
[ID]のアノテーションをロード
[ID]のカテゴリをロード
[ID]の画像をロード
アルゴリズムの結果をロードし、アクセスするAPIをつくる
アノテーションを表示
ポリゴンセグメンテーションをバイナリマスクにコンバート
run-length encoding (RLE)エンコード済みバイナリマスクMをデ
コード
RLEによってバイナリマスクMをエンコード](https://image.slidesharecdn.com/mscocodataset-151220205256/75/MS-COCO-Dataset-Introduction-4-2048.jpg)





![More Detail
記号の削除
PTBTorknizer in Stanford CoreNLPの役割について(前ページ参考コードより)
-LRB-, -RRB- == ( , )
-LCB-, -RCB- == { , }
-LSB-, -RSB- == [ , ]
は最初からないっぽい?
PUNCTUATIONS = ["''", "'", "``", "`", "-LRB-", "-RRB-", "-LCB-", "-RCB-",
".", "?", "!", ",", ":", "-", "--", "...", ";"]
小文字への統一
-lowerCase
lineの削除の例外処理(cutting-edgeなどの横棒は例外的に削除しない)
-preserveLines
cmd = ['java', '-cp', STANFORD_CORENLP_3_4_1_JAR,
'edu.stanford.nlp.process.PTBTokenizer',
'-preserveLines', '-lowerCase']](https://image.slidesharecdn.com/mscocodataset-151220205256/75/MS-COCO-Dataset-Introduction-10-2048.jpg)
![キャプションの実例(validationから)
最初が大文字、ピリオド A woman standing in a kitchen preparing tea.
全部小文字(理想的) a woman wearing a hat holding onto an umbrella
全部大文字 A MAN OPENING A DOOR TO AN OVEN IN A
RESTAURANT KITCHEN
最初にスペース A man riding his bike with his dog in the side kick seat
どうしようもないケース a corner of a bathroom shows part of a vanity and the
commode sits of the other side of the wa]]
キャプションを前処理なく使うのは自殺行為
最初が大文字、小文字、ピリオドがあるない、全て大文字、など表記ゆれが
結構ひどい
最後のは wall がwa]] となっていて笑う
悪いことは言わない、前処理に
coco-caption API のPTBTorknizer in Stanford CoreNLPを使おう
However…](https://image.slidesharecdn.com/mscocodataset-151220205256/75/MS-COCO-Dataset-Introduction-12-2048.jpg)

![Caption Evaluation
coco-caption APIには
BLEU, METEOR, ROUGE-L, CIDErによる自動評価尺度が
用意されている
必要なもの・・・生成したキャプションと対応する画像idの組
(データセット内の任意の数)をdumpしたjsonファイル
[{“image_id”: 404464, “caption”: “black
and white photo of a man standing in
front of a building”}, {“image_id”:
380932, “caption”: “group of people are
on the side of a snowy field”},
{“image_id”: 565778, “caption”: “train
traveling down a train station”}, … ]
(coco-caption/results/captions_val2014_fakecap_results.json)
http://arxiv.org/abs/1504.00325](https://image.slidesharecdn.com/mscocodataset-151220205256/75/MS-COCO-Dataset-Introduction-14-2048.jpg)














![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)






![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DLHacks]Fast and Accurate Entity Recognition with Iterated Dilated Convoluti...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-180604045159-thumbnail.jpg?width=640&height=640&fit=bounds)















