Synthesizing the preferredinputs
for neurons in neural networks
via deep generator networks
Takashi Shinozaki
CiNet, NICT
Nov 12, 2016
tshino@nict.go.jp
2.
紹介論文
• A. Nguyen,A. Dosovitskiy, J. Yosinski, T. Brox, J. Clune
• “Synthesizing the preferred inputs for neurons in
neural networks via deep generator networks”
• メインはワイオミング大学
• フライブルク大学の可視化技術がベース
• Dosovitskiy & Brox 2016 arXiv
• “Generating images with
perceptual similarity metrics
based on deep networks”
Ex. Arithmetics oversemantic space
• Radford et al., 2016
• “Unsupervised Representation Learning with Deep
Convolutional Generative Adversarial Networks”
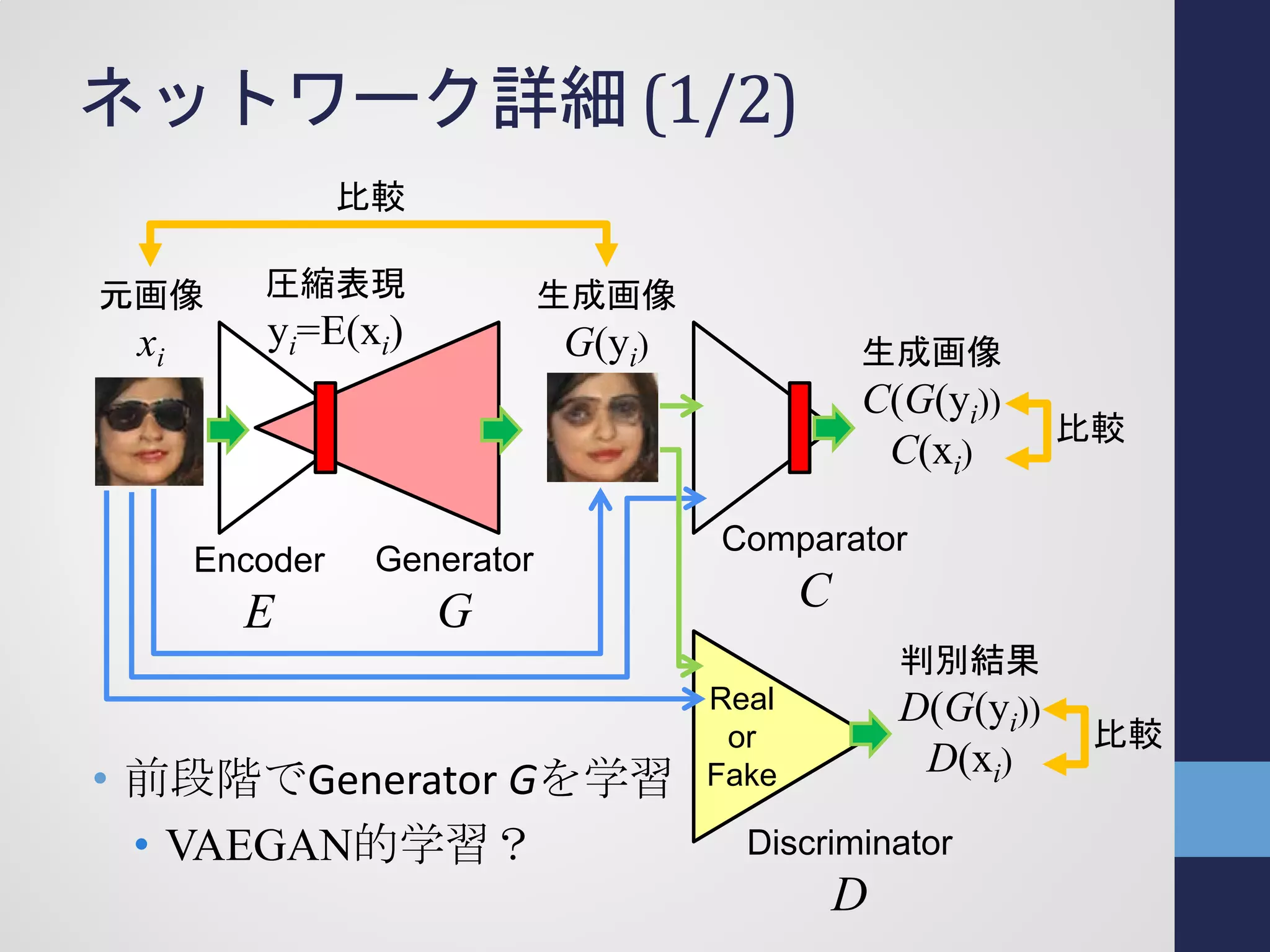
ネットワーク詳細 (1/2)
• 前段階でGeneratorGを学習
• VAEGAN的学習?
Real
or
Fake
圧縮表現
yi=E(xi)
生成画像
G(yi)
元画像
xi
Discriminator
D
Comparator
C
Encoder
E
Generator
G
生成画像
C(G(yi))
C(xi)
判別結果
D(G(yi))
D(xi)
比較
比較
比較





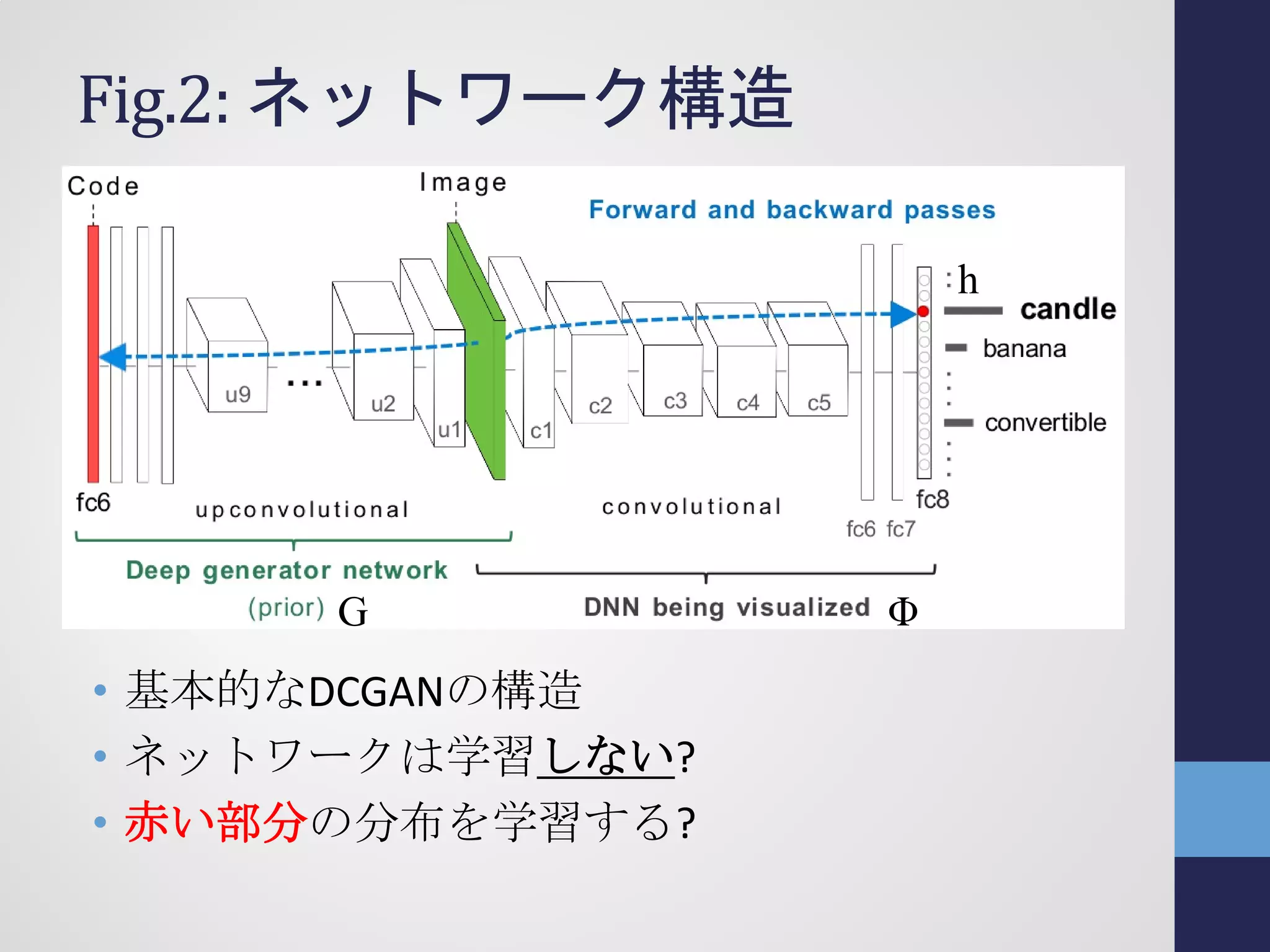
![はじめに
• Deep Neural Network (DNN)の可視化は重要
• 基礎科学として
• DNNの改良のため
• 可視化の基本
• Activation Maximization (AM) [Erhan+2009]
• 反応を最大化する入力を探す
• 可視化する先を制限するpriorが必要
• 自然画像なら自然画像のprior](https://image.slidesharecdn.com/semi161112tshino-161113071549/75/1-NIPS-5-2048.jpg)
![様々なprior
• Hand-designed priors
• Gaussian blur [Yosinski+2015]
• α-norm [Simonyan+2014]
• Total variation [Mahendran+2016]
• Jitter [Mordvintsev+2015]
• Data-driven patch [Wei+2015]
• Center-bias regularization [Nguyen+2016]
• Mean images [Nguyen+2016]
• 本研究ではImageNetを学習したCNNをpriorに!!](https://image.slidesharecdn.com/semi161112tshino-161113071549/75/1-NIPS-6-2048.jpg)
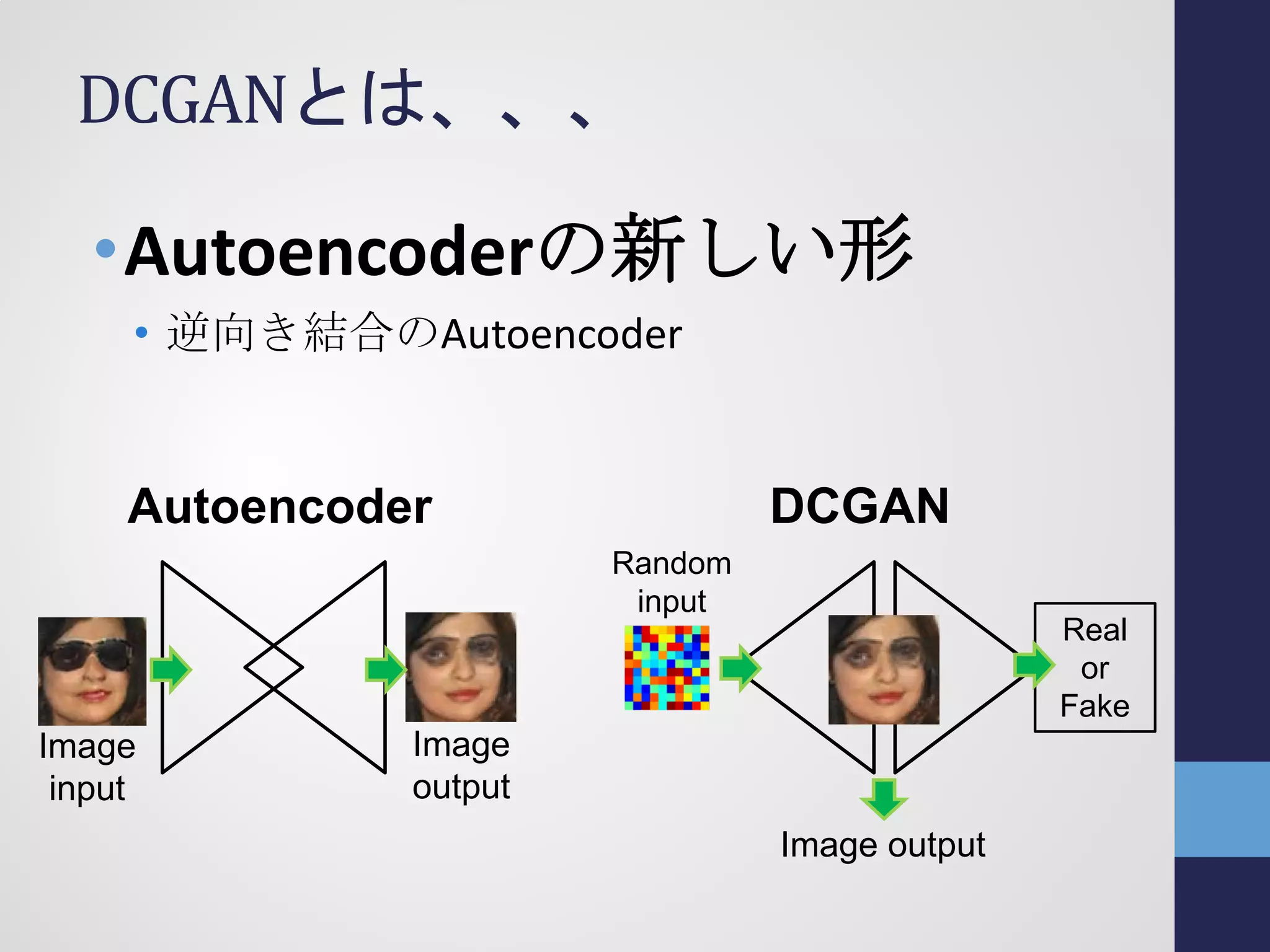
![可視化の為の生成モデル
• これまでの生成モデル
• Probabilistic model [Lee+2009]
• Auto-encoder [Alain+2014]
• Stochastic model [Kingma+2014]
• Recurrent networks [Theis+2015]
• Generative Adversarial Network (GAN)
• [Goodefellow+2014]
• 最近の流行、特にDCGAN
• Deep Convolutional GAN [Radford+2015]](https://image.slidesharecdn.com/semi161112tshino-161113071549/75/1-NIPS-7-2048.jpg)



![ネットワーク詳細 (2/2)
• ネットワークは固定して最適な圧縮表現を探索
• yiは [0,3σ]でクリッピング
• あらかじめEncoder Eの出力分布を取っておく
圧縮表現
yi=E(xi)
生成画像
G(yi)
target DNN
Φ
=可視化する
CNN
Generator
G
feature
h
ここを最適化](https://image.slidesharecdn.com/semi161112tshino-161113071549/75/1-NIPS-15-2048.jpg)
![Fig.3: Priorの汎用性 (1/3)
• MIT Places datasetで学習したDNN[Zhou+2014]
• Priorは普通のCaffeNet
• いずれもいい感じに可視化できた
• ネットの基本構造が同じなため?](https://image.slidesharecdn.com/semi161112tshino-161113071549/75/1-NIPS-16-2048.jpg)
![Fig.4: Priorの汎用性 (2/3)
• 全く異なるDNN [Donahue+2015]
• 動画像(UCF101)で学習
• 先のものと比べると性能が悪い?
• ネットのせい?データのせい?](https://image.slidesharecdn.com/semi161112tshino-161113071549/75/1-NIPS-17-2048.jpg)
![Fig.5: Priorの汎用性 (3/3)
• もっと根本から異なるネットワークでも検証
• 学習データは同一(ImageNet)
• GoogLeNet [Szegedy+2015], ResNet [Zhang+2016]
• 構造が違うほど性能は低下](https://image.slidesharecdn.com/semi161112tshino-161113071549/75/1-NIPS-18-2048.jpg)











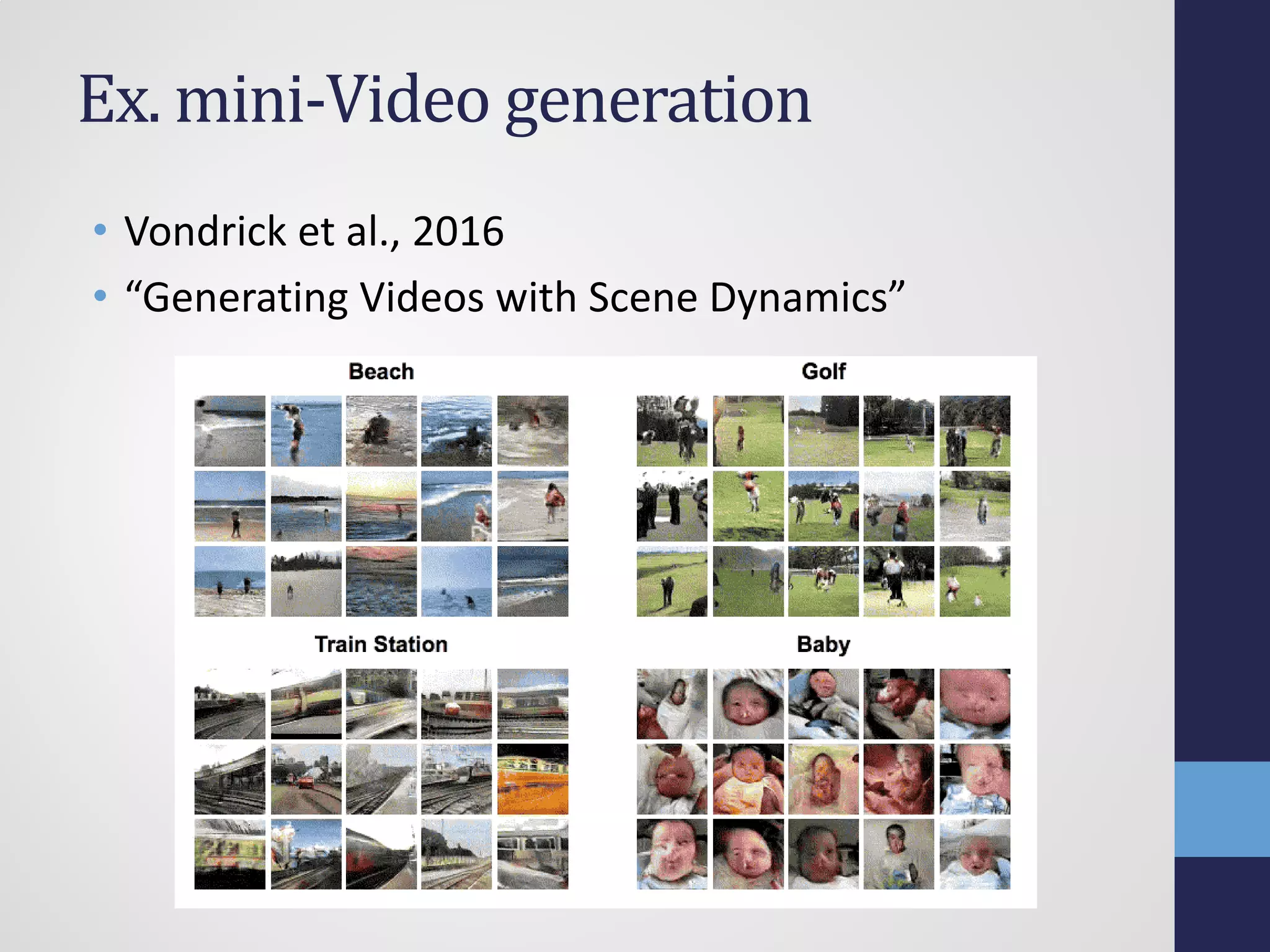
![動画の生成
• LRCN DNN[Donahue+2015]で生成モデル
• LSTMでUCF-101を判定するDNN
• 動画
• https://goo.gl/pCPIHA](https://image.slidesharecdn.com/semi161112tshino-161113071549/75/1-NIPS-30-2048.jpg)









![Fig.S15: 場所CNNでの各層 (2/2)
• 場所判定CNN[Zhou+2015]の学習表現
• 3-5層は物体検出に対応?
• fc6,fc7層では複数の表現が混ざり合う?](https://image.slidesharecdn.com/semi161112tshino-161113071549/75/1-NIPS-40-2048.jpg)
















![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)







![[cvpaper.challenge] 超解像メタサーベイ #meta-study-group勉強会](https://cdn.slidesharecdn.com/ss_thumbnails/metastudysr-190314071853-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]HoloGAN: Unsupervised learning of 3D representations from natural images](https://cdn.slidesharecdn.com/ss_thumbnails/hologanslideshare-190906010228-thumbnail.jpg?width=640&height=640&fit=bounds)















