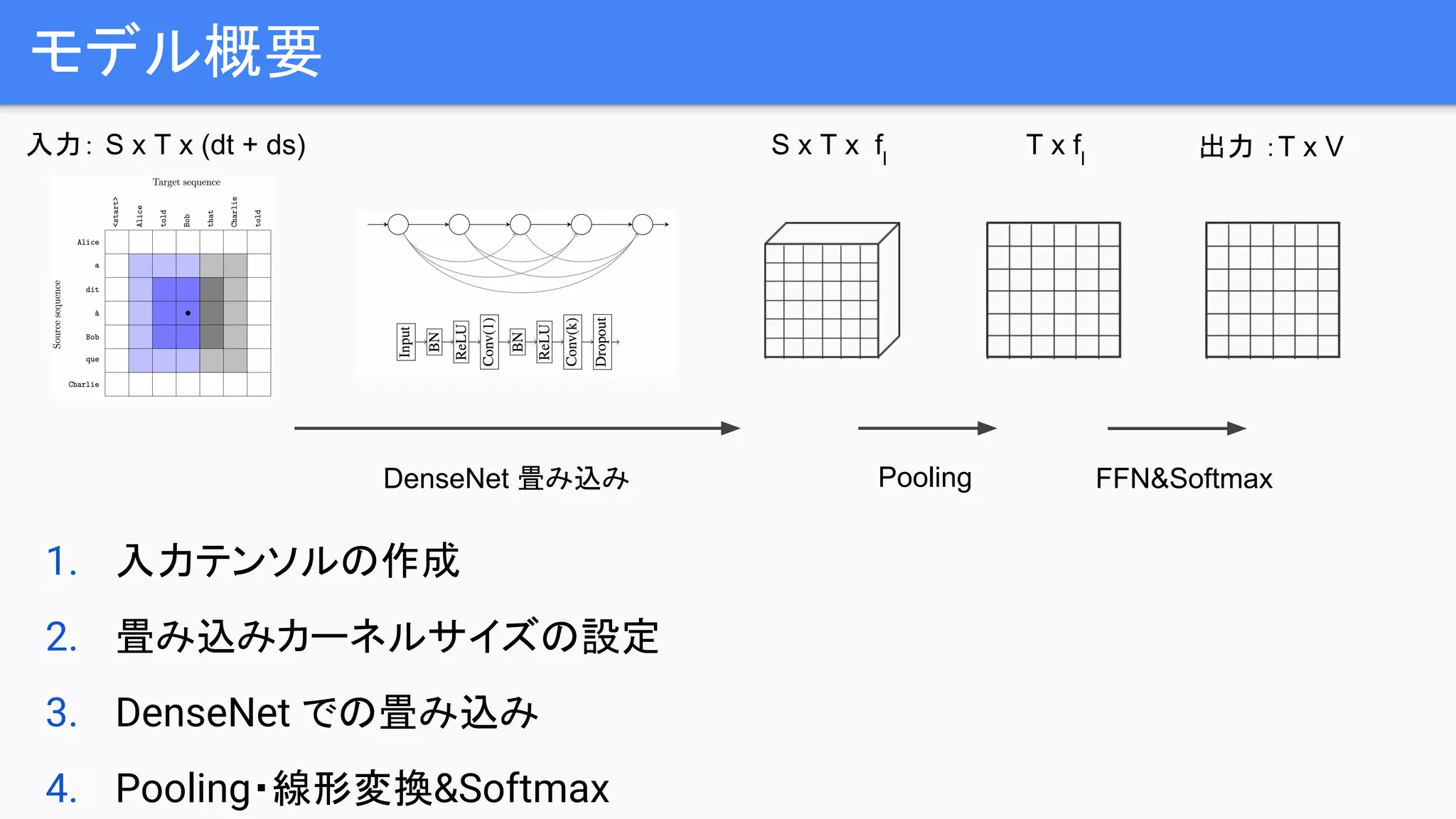
モデル概要
1. 入力テンソルの作成
2. 畳み込みカーネルサイズの設定
3.DenseNet での畳み込み
4. Pooling・線形変換&Softmax
入力: S x T x (dt + ds) S x T x fl
T x fl 出力 :T x V
DenseNet 畳み込み Pooling FFN&Softmax
8.
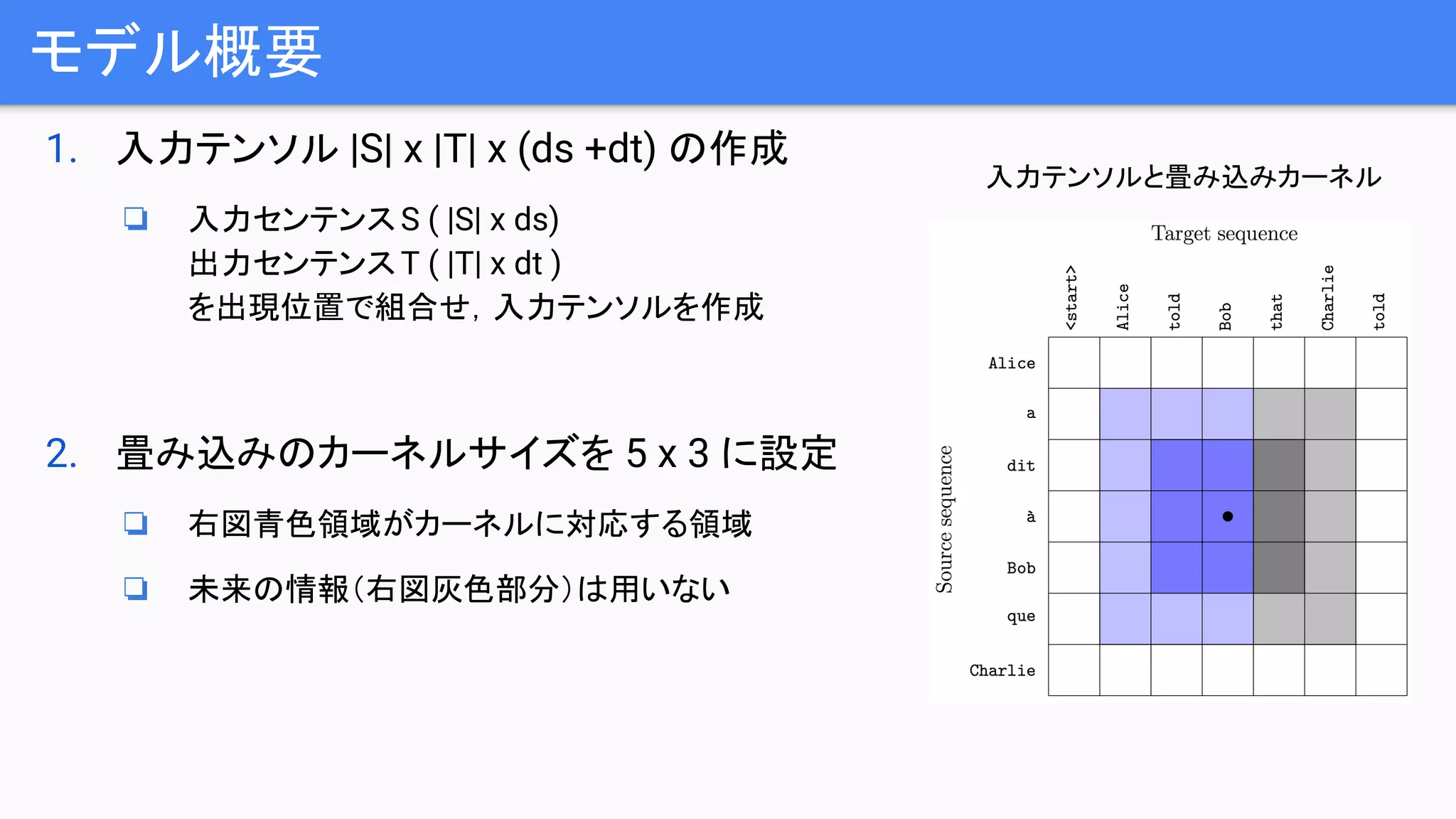
モデル概要
1. 入力テンソル |S|x |T| x (ds +dt) の作成
❏ 入力センテンスS ( |S| x ds)
出力センテンスT ( |T| x dt )
を出現位置で組合せ,入力テンソルを作成
2. 畳み込みのカーネルサイズを 5 x 3 に設定
❏ 右図青色領域がカーネルに対応する領域
❏ 未来の情報(右図灰色部分)は用いない
入力テンソルと畳み込みカーネル
モデル概要
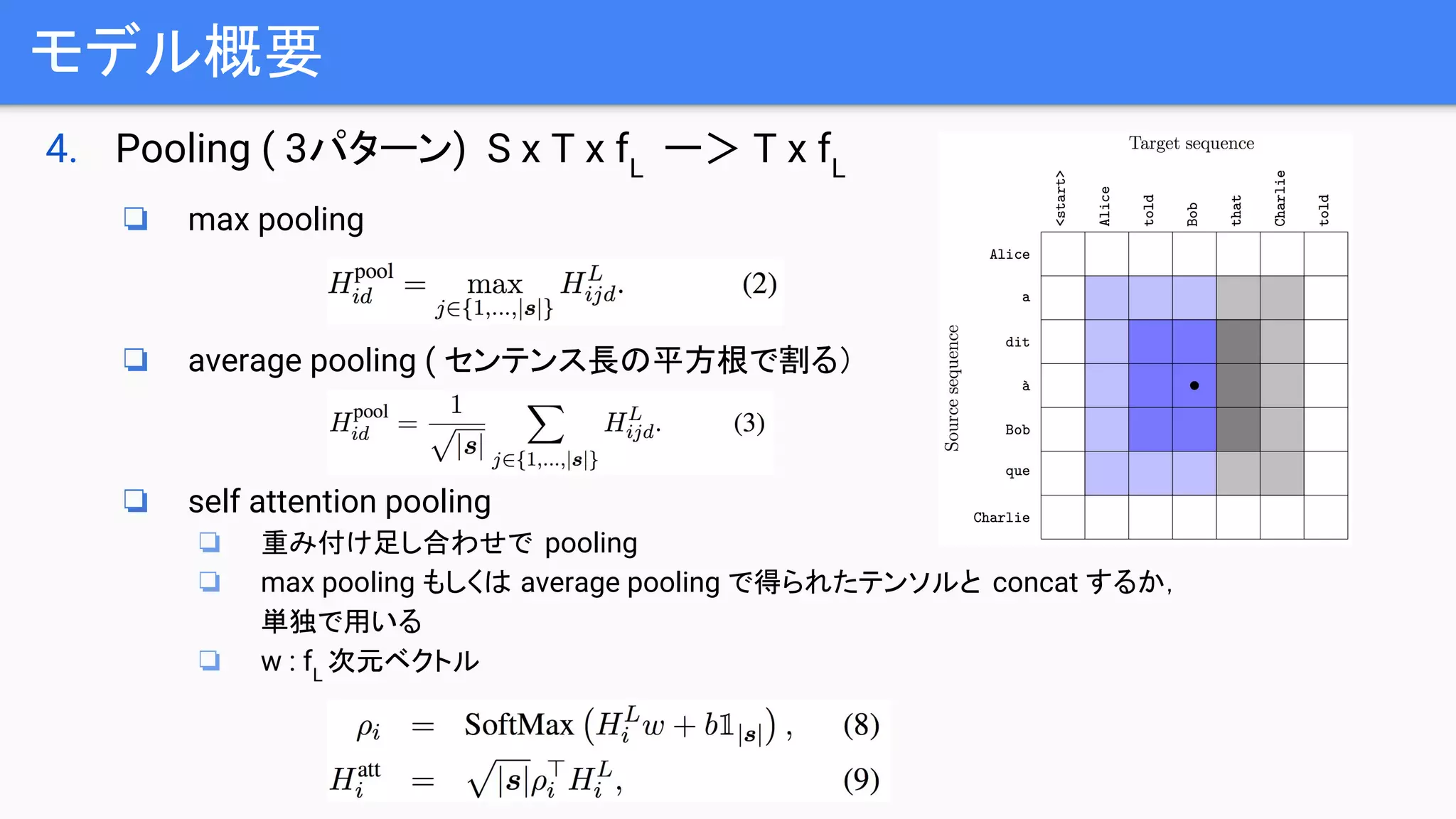
4. Pooling (3パターン) S x T x fL
ー> T x fL
❏ max pooling
❏ average pooling ( センテンス長の平方根で割る)
❏ self attention pooling
❏ 重み付け足し合わせで pooling
❏ max pooling もしくは average pooling で得られたテンソルと concat するか,
単独で用いる
❏ w : fL
次元ベクトル
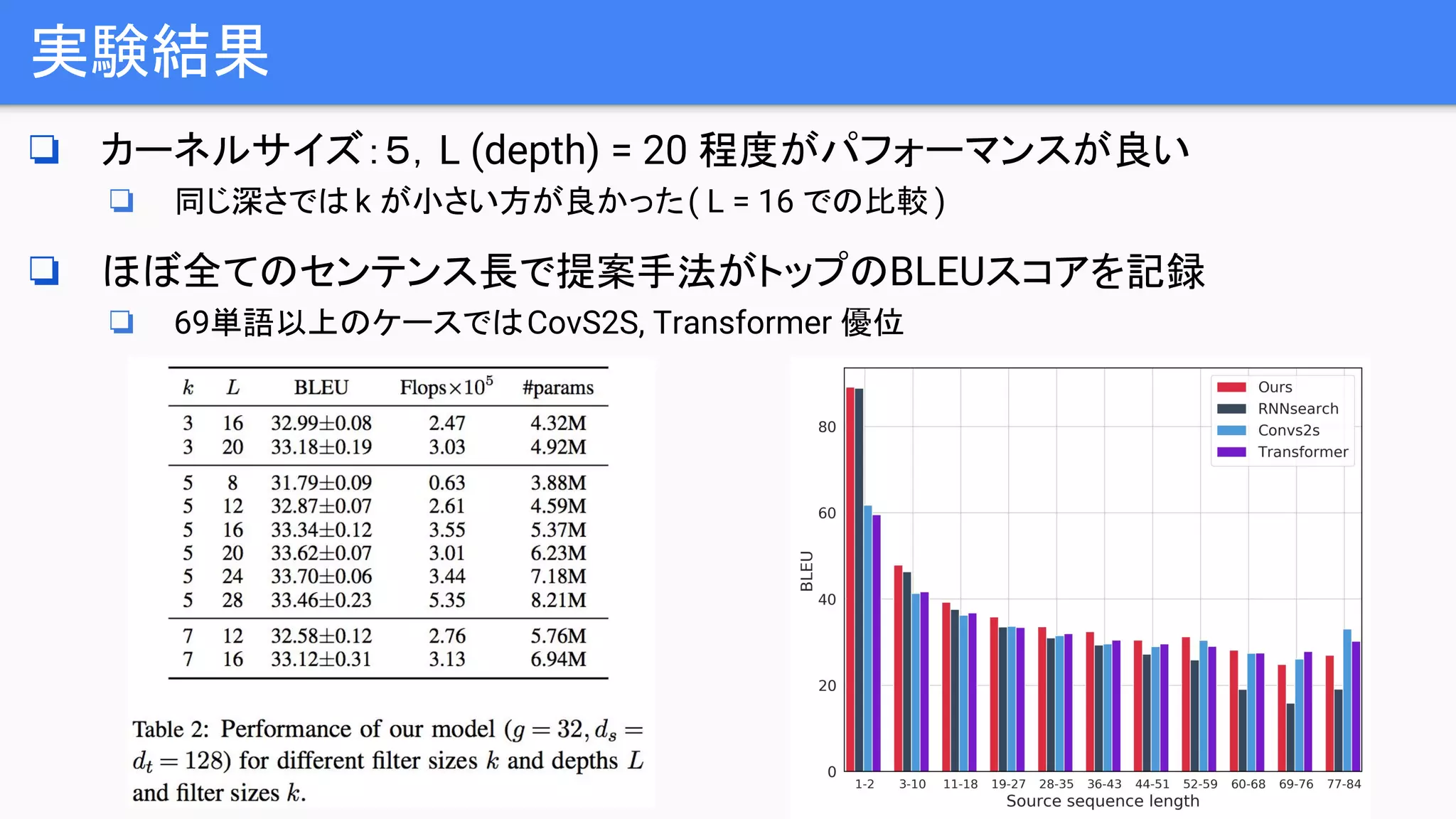
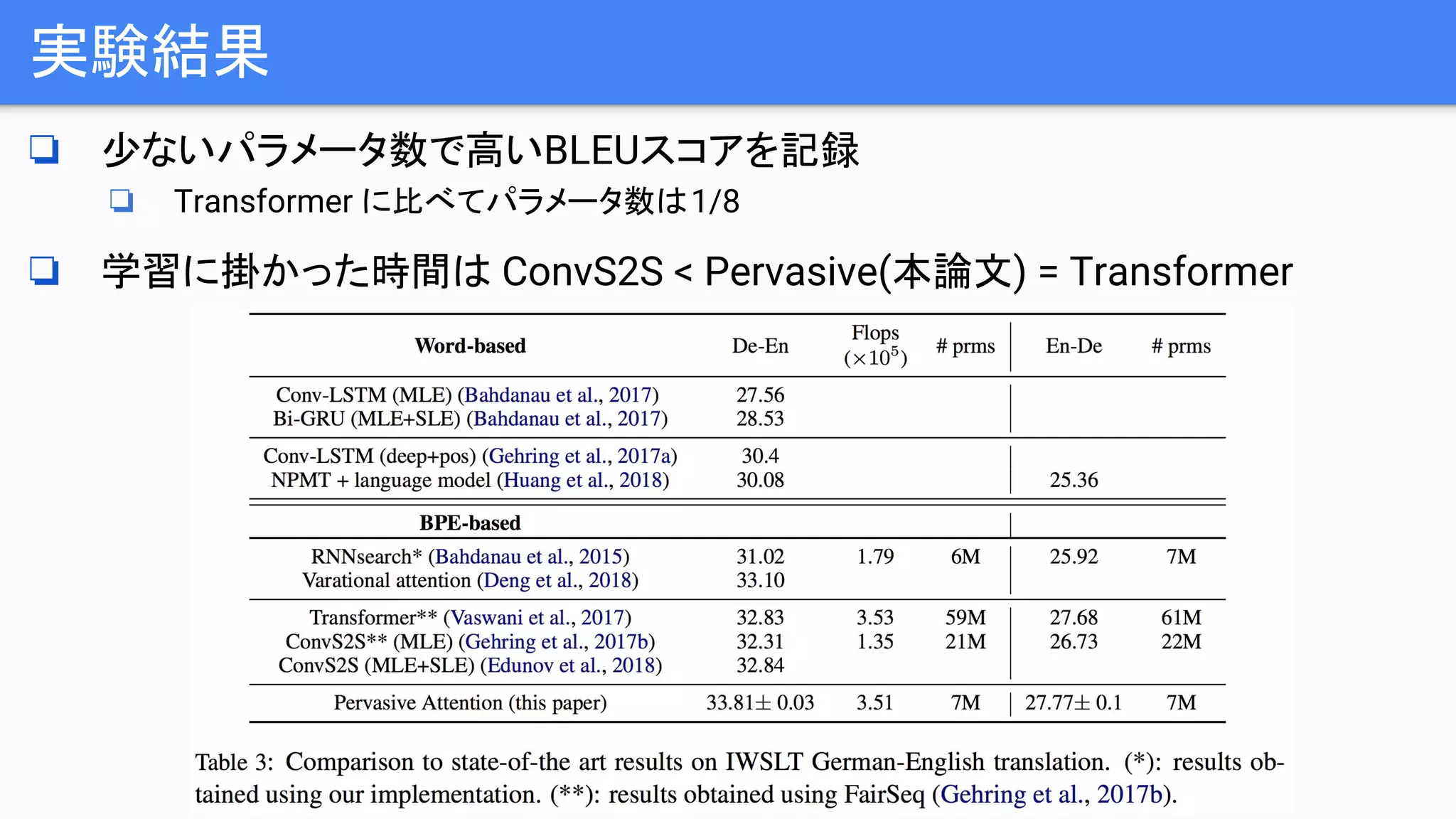
実験結果
❏ Alignment を確認
❏生成したBP w の生成確率へ,どの入力BP i が影響を与えていたか可視化
❏ max pooling オペレーション後に残る特徴量Bij
の内,入力 i の由来のものの,
出力 j (BP w ) に対する入力値αij
を計算
❏ 出力 j (BP w ) に対する αij
の値を確認することで,どの入力 i が BP の生成に効いていたの
かがわかる
![Pervasive Attention: 2D Convolutional Neural
Networks for Sequence-to-Sequence Prediction
DEEP LEARNING JP
[DL Papers]
Atsushi Kayama M3, Inc](https://image.slidesharecdn.com/20180907pervasiveattention2dconvolutionalneuralnetworksforsequence-to-sequenceprediction-180907000649/75/DL-Pervasive-Attention-2D-Convolutional-Neural-Networks-for-Sequence-to-Sequence-Prediction-1-2048.jpg)


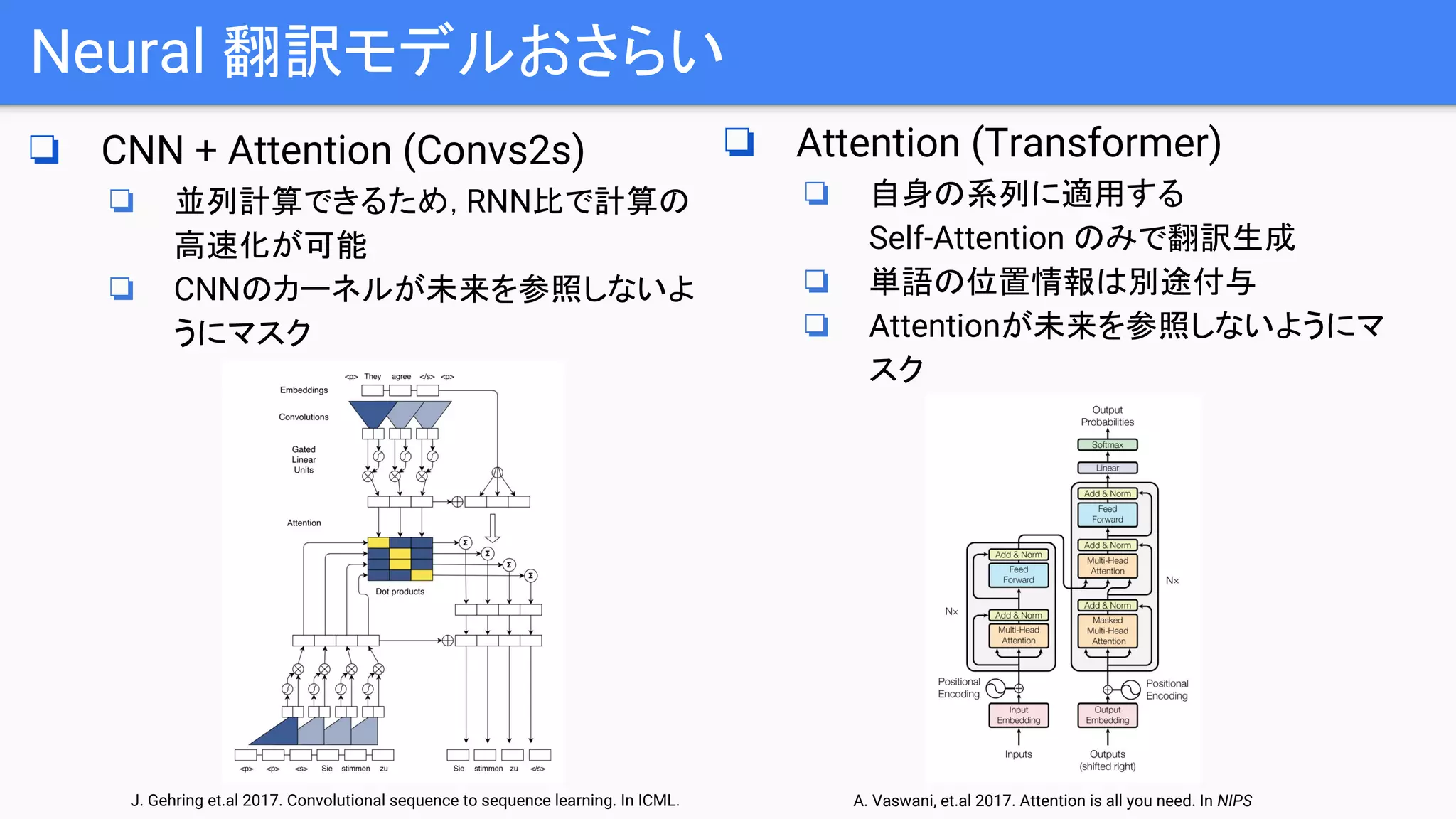
![Neural 翻訳モデルおさらい
❏ RNN (LSTM, GRU) + Attention
❏ encoder各ステップの隠れ状態を重み付き総和(Attention)した context をdecoder 各ス
テップにおいて求め,単語の生成に使用.
❏ Attention の計算・利用方法にはいくつかパターンが存在
❏ 計算パターン
❏ 内積注意 : encoder隠れ状態・decoder隠れ状態 の内積
❏ FFN注意:[encoder隠れ状態;decoder隠れ状態] を入力とする1層FFN
D. Bahdanau et. al 2015. Neural machine translation by jointly learning to align and translate. In ICLR](https://image.slidesharecdn.com/20180907pervasiveattention2dconvolutionalneuralnetworksforsequence-to-sequenceprediction-180907000649/75/DL-Pervasive-Attention-2D-Convolutional-Neural-Networks-for-Sequence-to-Sequence-Prediction-4-2048.jpg)








![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...](https://cdn.slidesharecdn.com/ss_thumbnails/181214dlpointnet-181214053349-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]SOM-VAE: Interpretable Discrete Representation Learning on Time Series](https://cdn.slidesharecdn.com/ss_thumbnails/190118nonakadlhacks-190118005053-thumbnail.jpg?width=640&height=640&fit=bounds)

![[第2版]Python機械学習プログラミング 第15章](https://cdn.slidesharecdn.com/ss_thumbnails/15-190318023254-thumbnail.jpg?width=640&height=640&fit=bounds)

















![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)



















