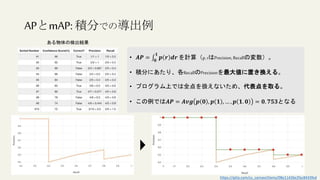
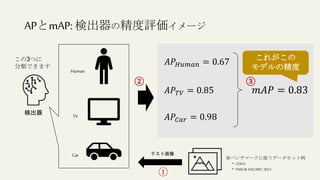
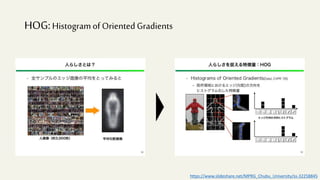
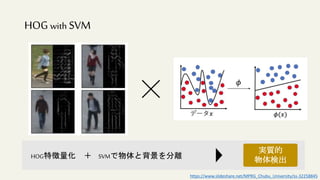
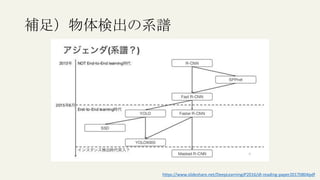
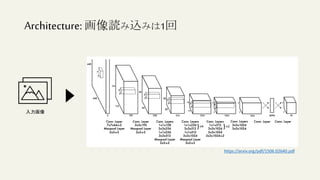
この文書は、物体検出におけるディープラーニングの進化を説明しており、異なるアルゴリズムやモデル(R-CNN、YOLO、SSDなど)の性能評価や実用化について詳述しています。特に、精度評価指標や評価方法、学習プロセスに関連する技術的な詳細が含まれています。最終的には、モデルの高速化や精度向上のための方法論に焦点を当てています。















![問題点:計算資源への高負荷
実行時間の長さ
学習プロセスが多段階かつ複雑
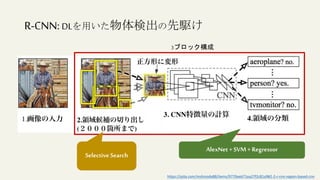
1. ImageNet(1画像1物体)によるCNN
の事前学習
2. VOC(1画像多物体)によるCNNの
転移学習
3. CNN出力からSVMの分類学習
4. 矩形回帰の学習
• 領域候補が2000個
• 認識時間10-45 [sec/image]
@ NvidiaTesla K40
× 2000 ×画像の枚数](https://image.slidesharecdn.com/2-211025021415/85/R-CNN-SSD-YOLO-22-320.jpg)


























![参考文献
• [DL輪読会]YOLO9000:Better, Faster, Stronger https://www.slideshare.net/DeepLearningJP2016/dl-reading-paper20170804pdf
• You Only Look Once: Unified, Real-Time Object Detection https://arxiv.org/abs/1506.02640.pdf
• Introduction toYOLO detection model https://www.slideshare.net/ssuser07aa33/introduction-to-yolo-detection-model
• SSD:Single Shot MultiBox Detector https://arxiv.org/abs/1512.02325.pdf
• 物体検出アルゴリズムSSDを読解するpart2 https://qiita.com/hiroqik/items/2f602913a0363f2c9ee9](https://image.slidesharecdn.com/2-211025021415/85/R-CNN-SSD-YOLO-53-320.jpg)


![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields](https://cdn.slidesharecdn.com/ss_thumbnails/realtimemultipersonposeestimation1-170907054459-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL Hacks]Simple Online Realtime Tracking with a Deep Association Metric](https://cdn.slidesharecdn.com/ss_thumbnails/2019-04-01dlhacksdeepsortsugisaki-190412022858-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/pvrcnn-200311050009-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Libra R-CNN: Towards Balanced Learning for Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/20190712librar-cnn-190719032725-thumbnail.jpg?width=640&height=640&fit=bounds)






![[NS][Lab_Seminar_240611]Graph R-CNN.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240611graphr-cnn-240704112605-f42276be-thumbnail.jpg?width=640&height=640&fit=bounds)

























