Download as PDF, PPTX






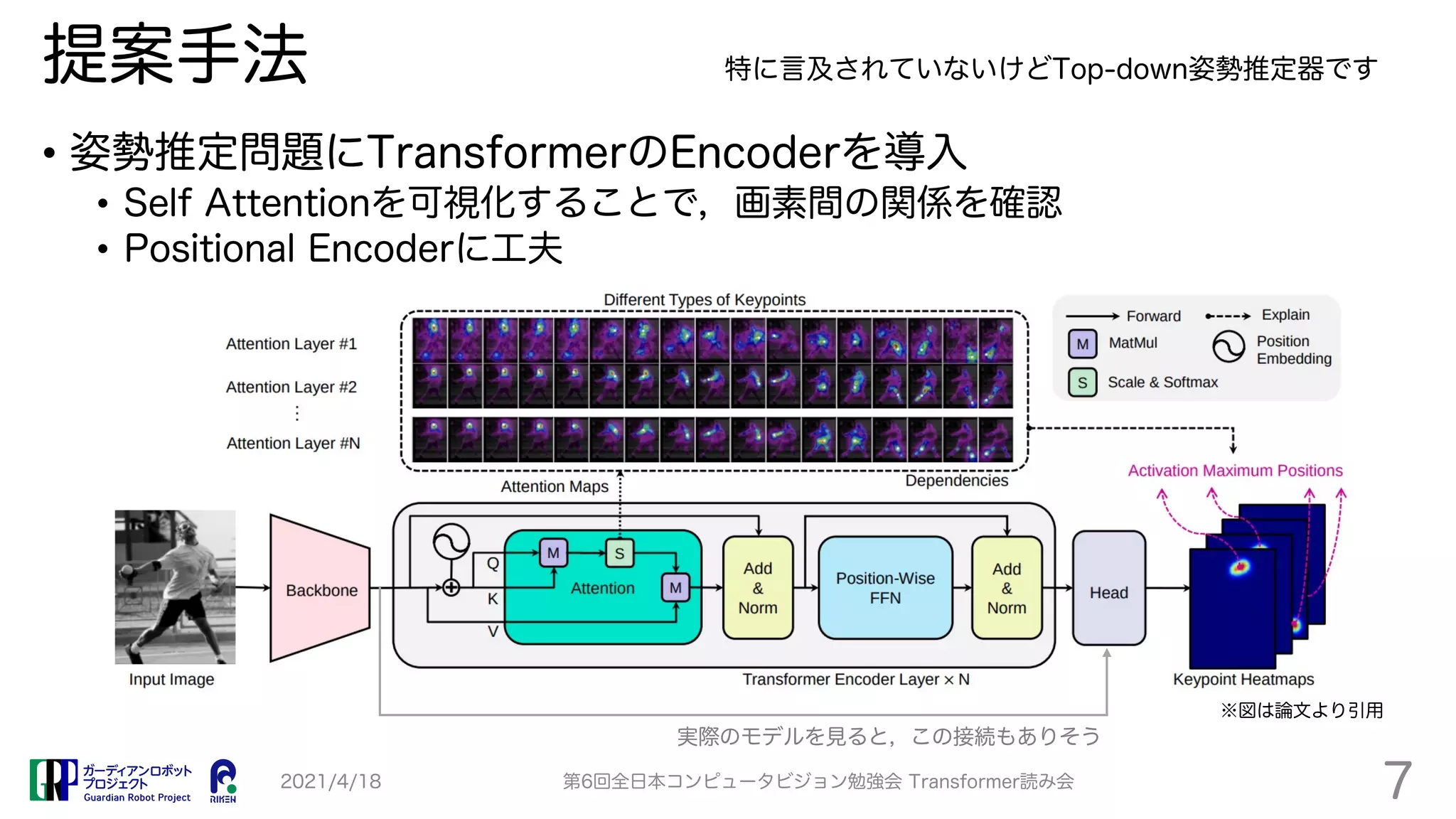

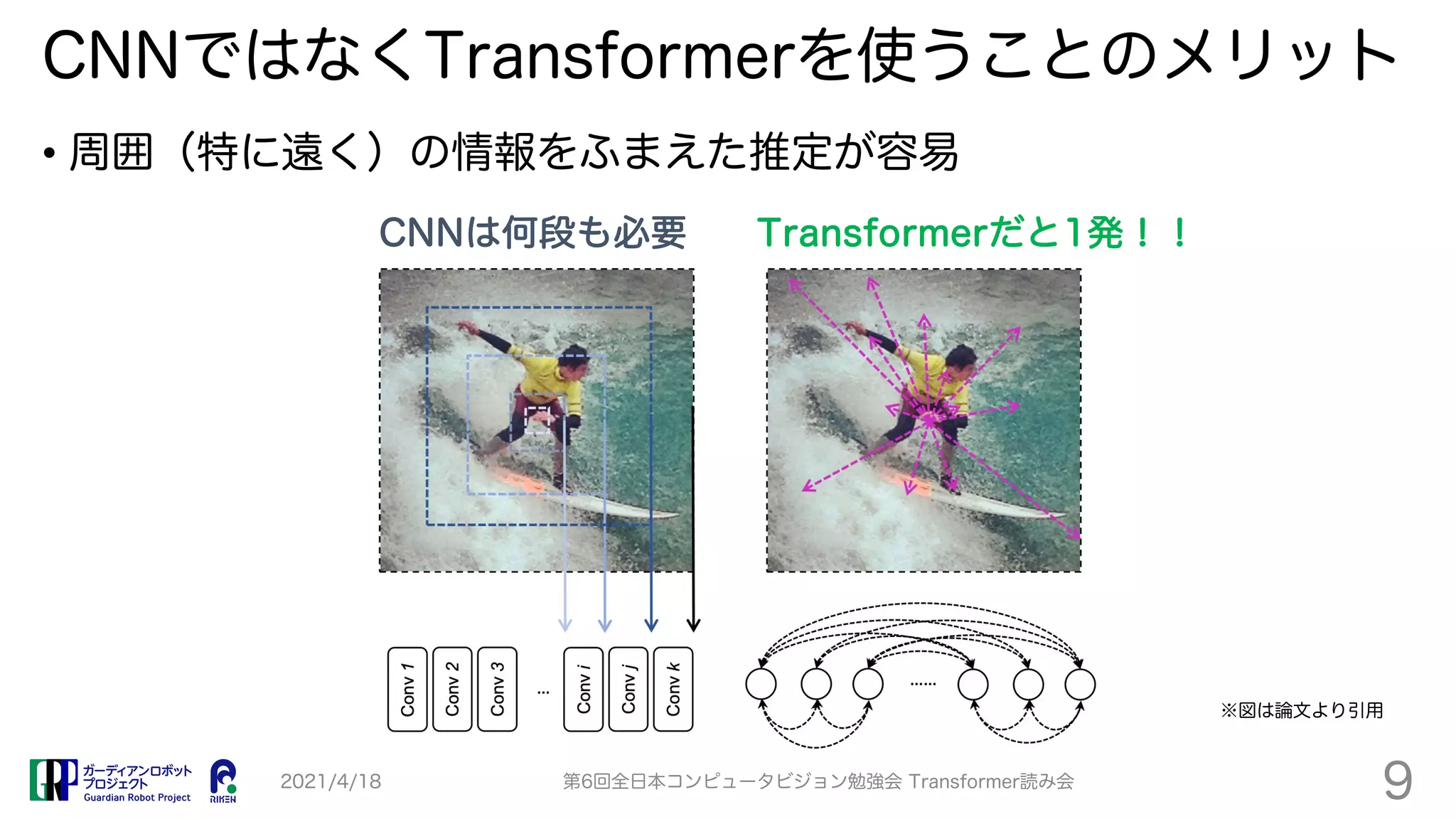
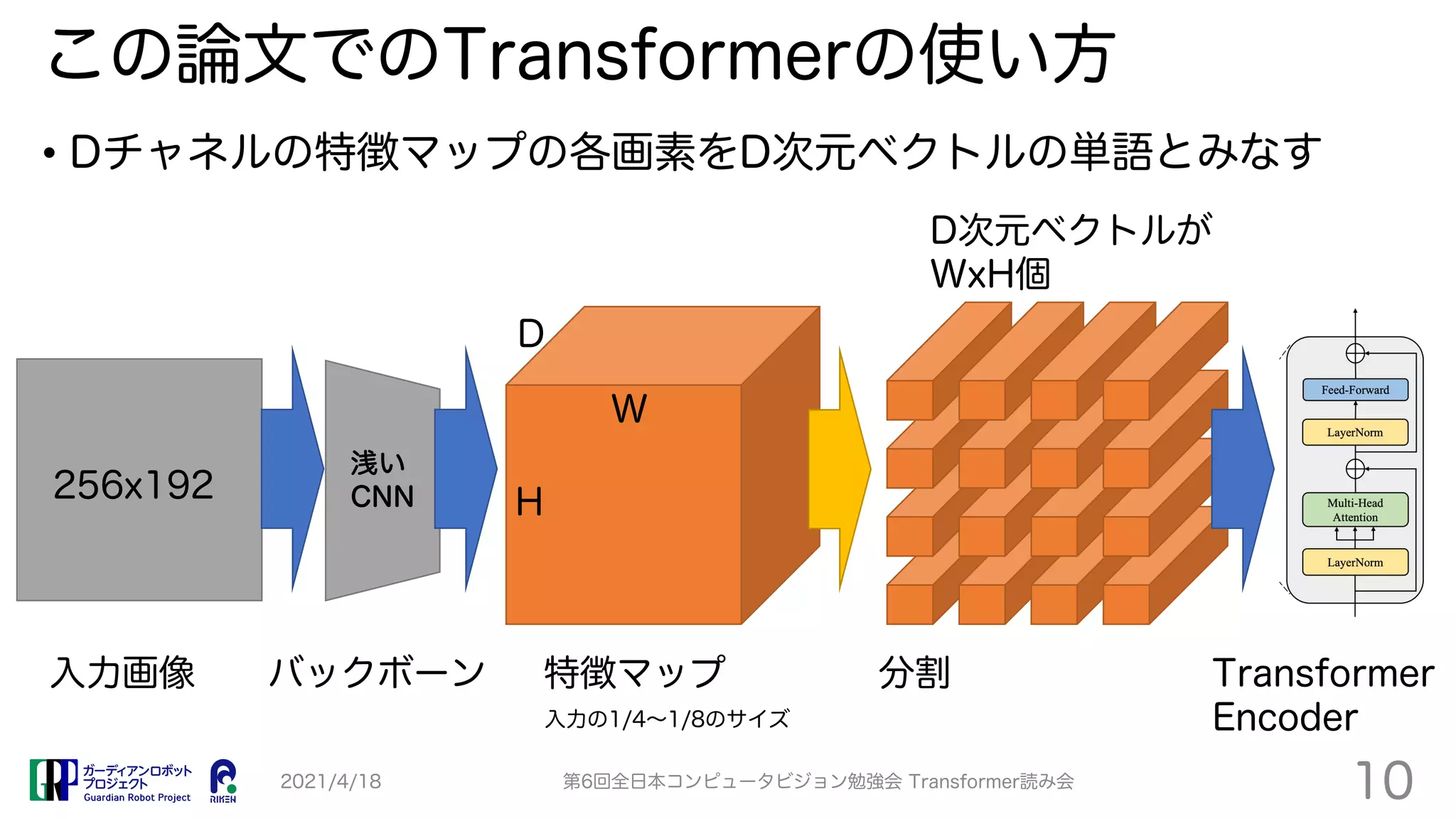
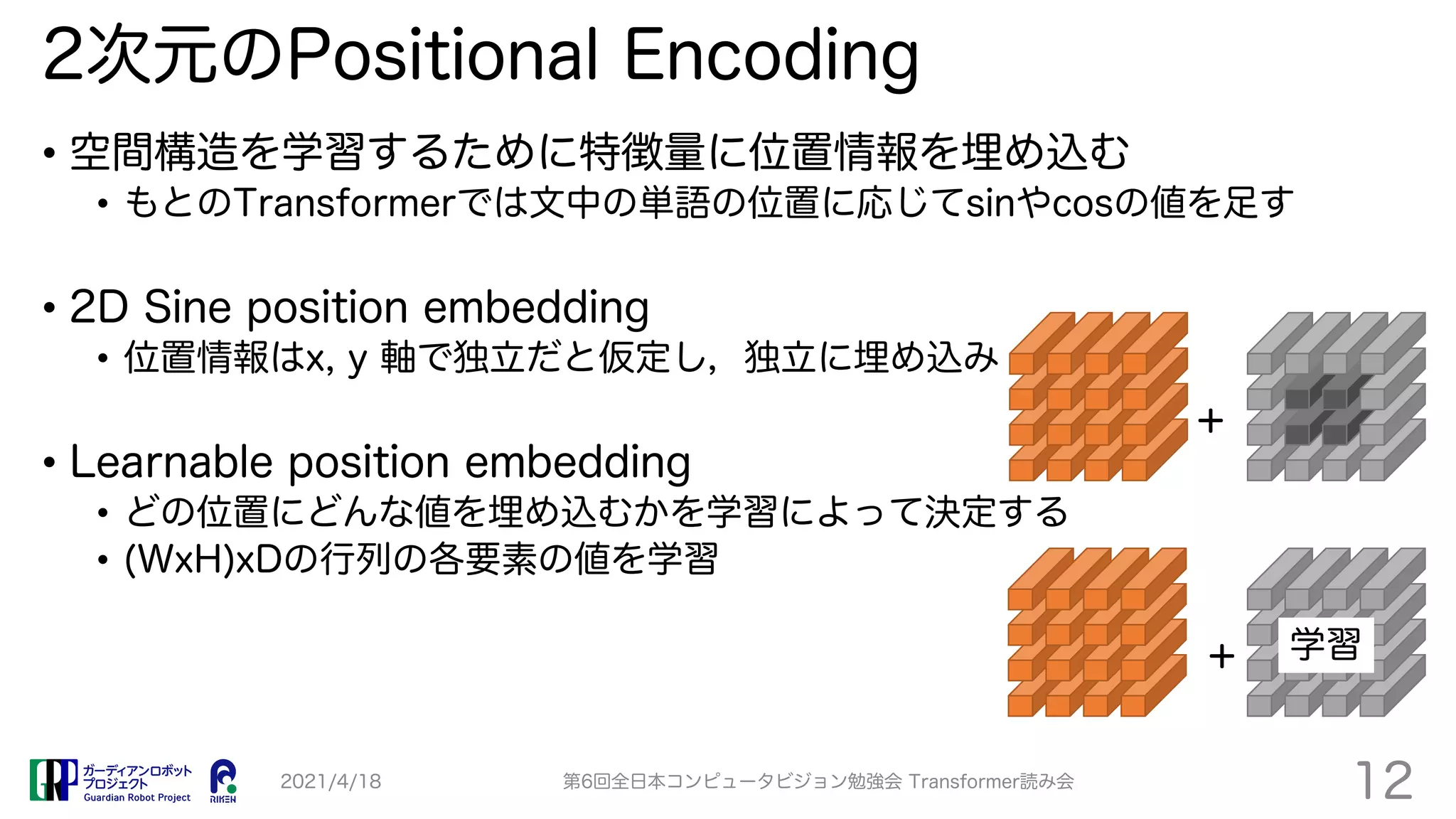
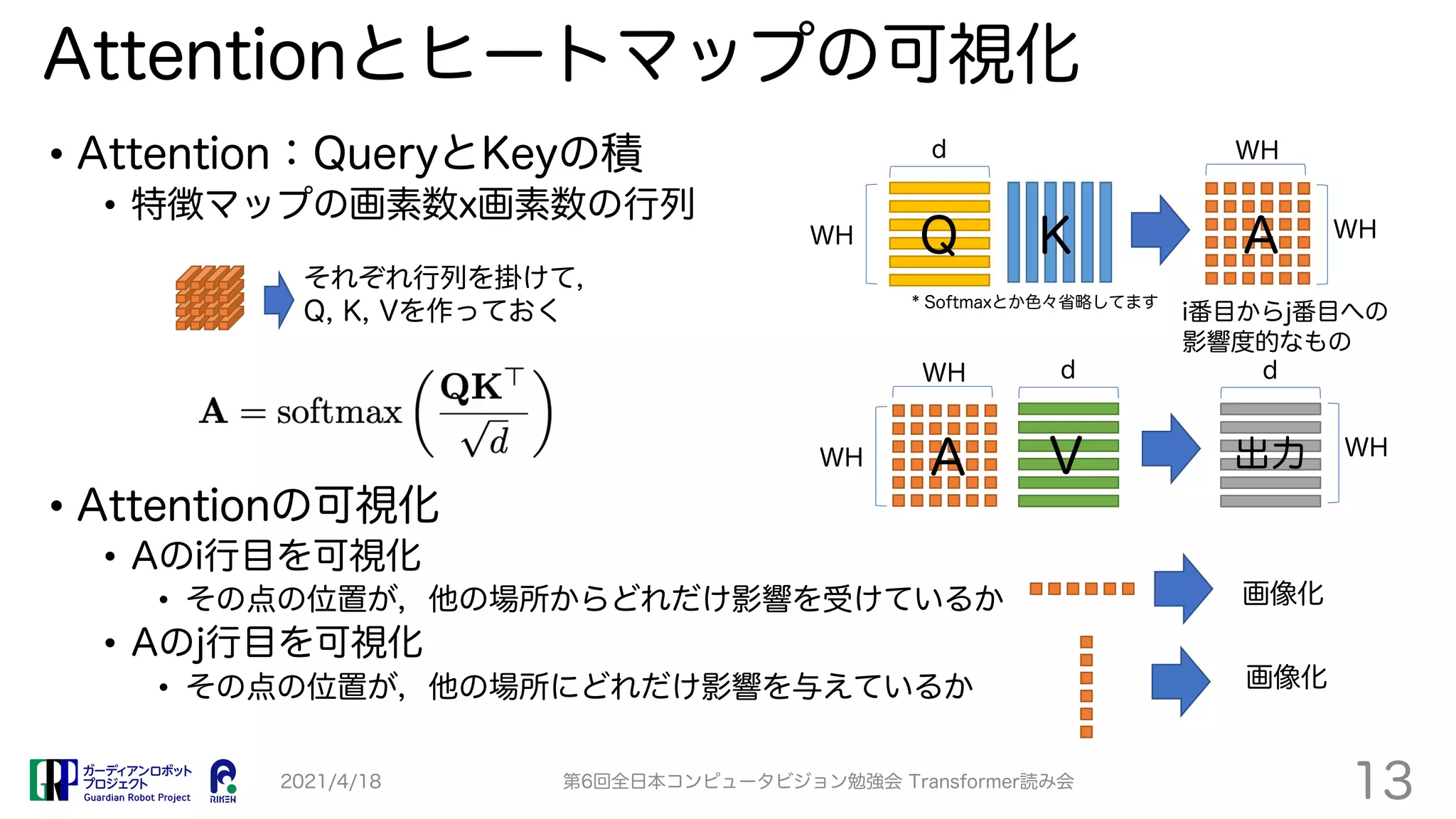


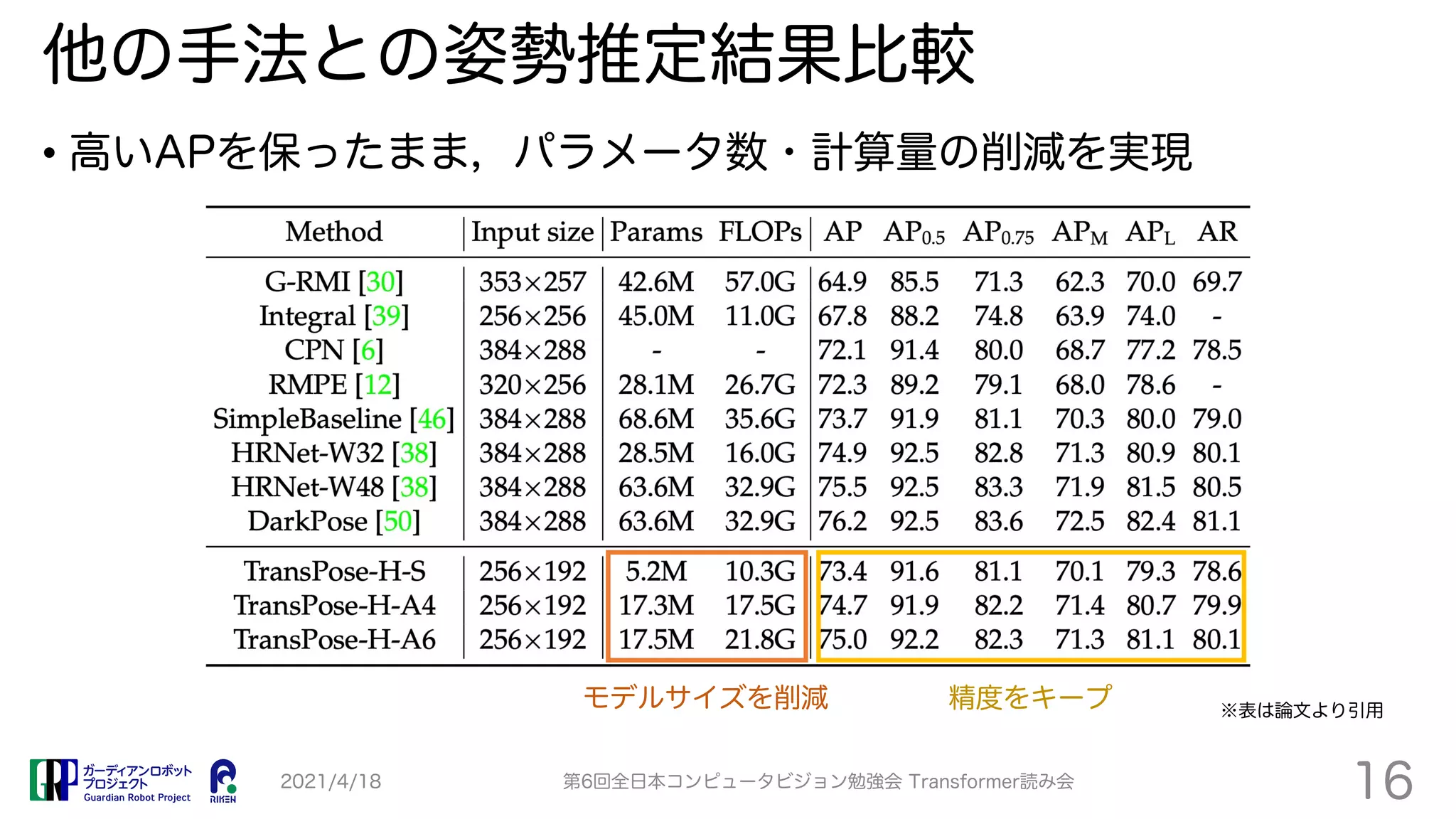
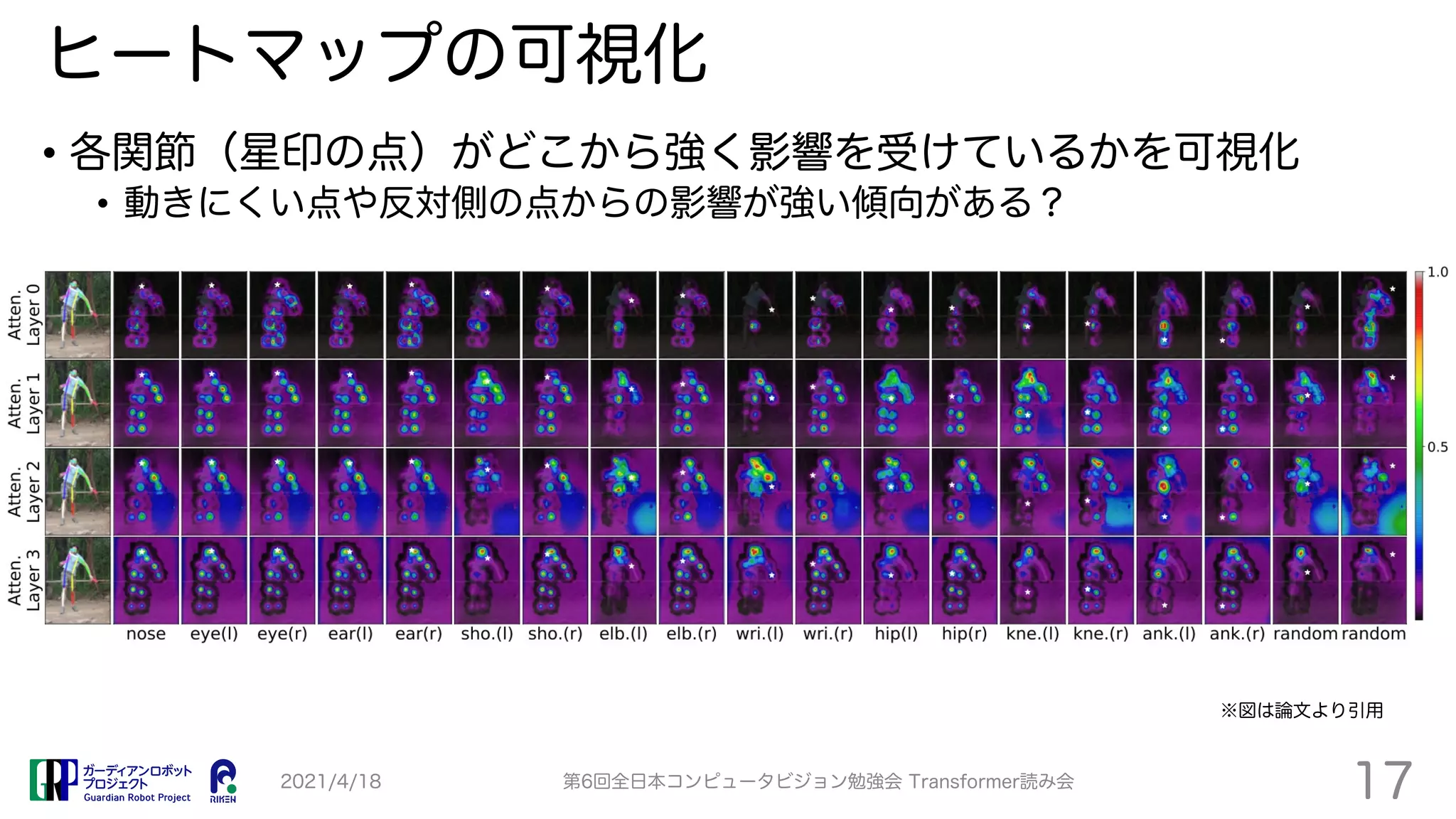

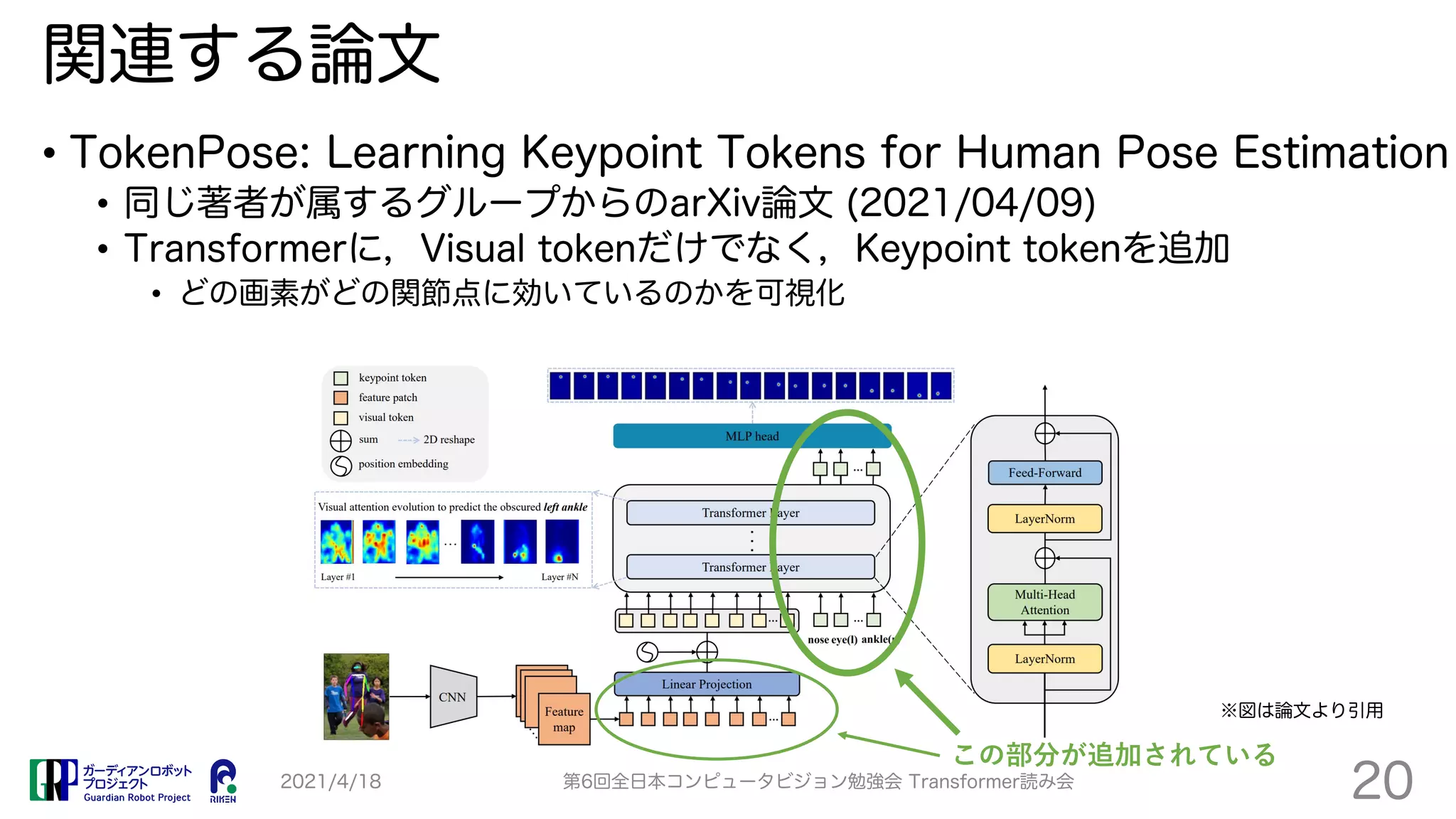

TransPose proposes a Transformer-based model for human pose estimation that aims to improve explainability. It applies a Transformer encoder to feature maps from an image to estimate keypoint heatmaps. Self-attention can visualize relationships between pixels. The model achieves comparable accuracy to CNN models but with 73% fewer parameters and faster speed. Heatmap visualizations show which locations influence each joint the most.

![[DL輪読会]LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking](https://cdn.slidesharecdn.com/ss_thumbnails/200124dlseminar-200124001212-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Deep High-Resolution Representation Learning for Human Pose Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/20190517hrnet-190517005504-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...](https://cdn.slidesharecdn.com/ss_thumbnails/20210729kokiyamane-210730035349-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)







































