Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Deep Learning JP
PPTX, PDF
1,543 views
【DL輪読会】大量API・ツールの扱いに特化したLLM
2023/6/2 Deep Learning JP http://deeplearning.jp/seminar-2/
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 18 times
1
/ 19
2
/ 19
3
/ 19
4
/ 19
5
/ 19
6
/ 19
7
/ 19
8
/ 19
9
/ 19
10
/ 19
11
/ 19
12
/ 19
13
/ 19
14
/ 19
15
/ 19
16
/ 19
17
/ 19
18
/ 19
19
/ 19
More Related Content
PDF
CV分野におけるサーベイ方法
by
Hirokatsu Kataoka
PDF
機械学習モデルのハイパパラメータ最適化
by
gree_tech
PDF
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
PPTX
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
PDF
学振特別研究員になるために~知っておくべき10のTips~[平成28年度申請版]
by
Masahito Ohue
PDF
条件付き確率場の推論と学習
by
Masaki Saito
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
PDF
Data-centricなML開発
by
Takeshi Suzuki
CV分野におけるサーベイ方法
by
Hirokatsu Kataoka
機械学習モデルのハイパパラメータ最適化
by
gree_tech
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
学振特別研究員になるために~知っておくべき10のTips~[平成28年度申請版]
by
Masahito Ohue
条件付き確率場の推論と学習
by
Masaki Saito
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
Data-centricなML開発
by
Takeshi Suzuki
What's hot
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PPTX
優れた研究論文の書き方
by
Masanori Kado
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
PPTX
[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PPTX
【DL輪読会】論文解説:Offline Reinforcement Learning as One Big Sequence Modeling Problem
by
Deep Learning JP
PPTX
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
PDF
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PDF
【DL輪読会】GPT-4Technical Report
by
Deep Learning JP
PDF
ICML 2021 Workshop 深層学習の不確実性について
by
tmtm otm
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PDF
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
PDF
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
PDF
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Yasunori Ozaki
機械学習モデルの判断根拠の説明
by
Satoshi Hara
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
優れた研究論文の書き方
by
Masanori Kado
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】論文解説:Offline Reinforcement Learning as One Big Sequence Modeling Problem
by
Deep Learning JP
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
【DL輪読会】GPT-4Technical Report
by
Deep Learning JP
ICML 2021 Workshop 深層学習の不確実性について
by
tmtm otm
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Yasunori Ozaki
Similar to 【DL輪読会】大量API・ツールの扱いに特化したLLM
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
by
Deep Learning JP
PPTX
MLflowで学ぶMLOpsことはじめ
by
Kenichi Sonoda
PDF
MLflowによる機械学習モデルのライフサイクルの管理
by
Takeshi Yamamuro
PDF
『生成AIによるソフトウェア開発』(鷲崎弘宜, 鵜林尚靖, 中川尊雄, 増田航太, 徳本晋, 近藤将成, 石川冬樹, 竹之内啓太, 小川秀人, スマートエ...
by
Hironori Washizaki
PDF
LLM/生成AI&エージェントによるソフトウェア開発の実践と展望(SES2025チュートリアル)
by
Hironori Washizaki
PPTX
ChatGPT Impact - その社会的/ビジネス価値を考える -
by
Daiyu Hatakeyama
PDF
Building an AI chatbot development environment with Azure + Flowise
by
Jingun Jung
PDF
W&B webinar finetuning_配布用.pdf
by
Yuya Yamamoto
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
by
Deep Learning JP
MLflowで学ぶMLOpsことはじめ
by
Kenichi Sonoda
MLflowによる機械学習モデルのライフサイクルの管理
by
Takeshi Yamamuro
『生成AIによるソフトウェア開発』(鷲崎弘宜, 鵜林尚靖, 中川尊雄, 増田航太, 徳本晋, 近藤将成, 石川冬樹, 竹之内啓太, 小川秀人, スマートエ...
by
Hironori Washizaki
LLM/生成AI&エージェントによるソフトウェア開発の実践と展望(SES2025チュートリアル)
by
Hironori Washizaki
ChatGPT Impact - その社会的/ビジネス価値を考える -
by
Daiyu Hatakeyama
Building an AI chatbot development environment with Azure + Flowise
by
Jingun Jung
W&B webinar finetuning_配布用.pdf
by
Yuya Yamamoto
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PPTX
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
PDF
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
【DL輪読会】大量API・ツールの扱いに特化したLLM
1.
大量API・ツールの扱いに特化したLLM 岡田 領 /
Ryo Okada(@anonymousgraba)
2.
大量API・ツールの扱いに特化したLLM 2023/5/19 Arxiv 2023/5/24
Arxiv • 直近見かけた2本
3.
ToolkenGPT • LLMの外部ツール利用 • プロンプトとしてツールの利用例を与える
(In context learningを活用する) 場合数ショットの デモしか与えることしかできない,かつ大量ツール前提だと安定して動作しない. • Toolformerなど(finetune)では少数のAPIでしか検証されていない,かつ計算コストが大きい • 提案手法:ToolkenGPT • Toolをtokenとして表現(Toolken)する発想 • tooklen埋め込みをLLMヘッドに挿入し,学習(LLMは固定) • LLMは次トークン予測の中でツール利用・選択を判断. • Finetuneより低コストで大量ツールにおいても安定した動作
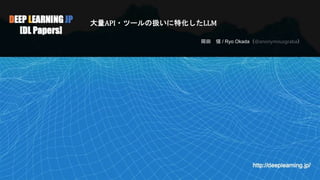
4.
ToolkenGPTの概要 • LLMモデルのヘッドに単語埋め込みにconcatする形でツールの埋め込み(toolken embeddings)を追加 • LLMの次トークンの予測確率: •
LLMに単語トークンだけでなく, ツール実行の必要性を判断して,toolken(ツール実行の トークン)を生成することを期待する. Word embeddings toolken embeddings Last Hidden state t: word token
5.
ToolkenGPTの概要(推論の流れ) • LLMはwordだけでなく,必要に応じてtoolken(tool利用を意味するトークン)を生成.( 推論モード
) • Toolkenが予測されたらtoolモードに移行し,該当するtool実行 • 結果をテキストに合成 • (上記はLLMが生成途中で数学演算子squareを選択.ツールモードで16を引数として生成.ツールを実行し,結果256を返し,推 論モードに戻る例)
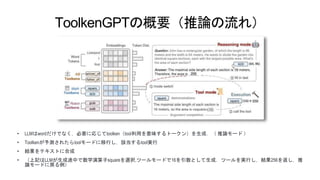
6.
データセット・学習 • LLMの重みは固定でtoolken embeddingsを学習する •
学習データの形式 • Toolkenを予測するタイミング,呼び出すAPI内容を指定.(N/Aは無視の意味合い) • ”the”, “area”, “is”, “2”, “5”, “6”, “square”, “feet”, ... • “the”, “area”, “is”, “ [square]”, “[N/A]”, “[N/A]”, “square”, “feet”, ...) • →”2”の時点でsquareのツールを呼び出す.”2”でツールを呼び出すので,”5”,”6”は無視. • データの作成 • 教師あり学習で利用するためにKBや計算トレースの自然言語文と正解のツールを前処理 • LLMで今回の構文を指定し,生成 • 上記で教師あり学習(LLM本体の重みは固定でtoolken embeddingsのみ更新)
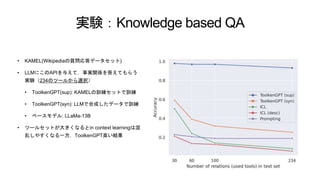
7.
実験:Knowledge based QA •
KAMEL(Wikipediaの質問応答データセット) • LLMにこのAPIを与えて,事実関係を答えてもらう 実験(234のツールから選択) • ToolkenGPT(sup): KAMELの訓練セットで訓練 • ToolkenGPT(syn): LLMで合成したデータで訓練 • ベースモデル: LLaMa-13B • ツールセットが大きくなるとin context learningは混 乱しやすくなる一方,ToolkenGPT高い結果
8.
実験:エージェントシミュレーション • LLMをエージェントのコントローラとして利用する実験 (LLMで次アクションを生成) • 家庭環境シミュレーション環境のVirtual
Homeでの実験 • 58のtoolから選択 • 他のLLMがSit at deskで失敗する中,toolkenGPTはchair に座ることに成功
9.
大量API・ツールの扱いに特化したLLM 2023/5/19 Arxiv 2023/5/24
Arxiv
10.
ゴリラの概要 • LLMで正確にAPIコール行うのは難しい • 大量のAPIから適切なものの選択 •
頻繁に変化するAPI仕様への対応 • APIコール特化したモデル,ゴリラの提案(OSS プロジェクト) • 大量APIデータセットのAPIBenchの公開 • HF, TF, TouchHubのAPIに対する0shotモデルを公開 • API appstore for LLMを謳ったプラットフォームを意識 • Apache2.0商用利用可で7/5リリース予定
11.
ゴリラの能力 • ユーザープロンプトに応じて目的を満たすAPIを選択.API仕様書よりAPIコールするコー ドを生成
13.
APIBench • 3つのML APIハブより収集したAPIコレクションのデータセット •
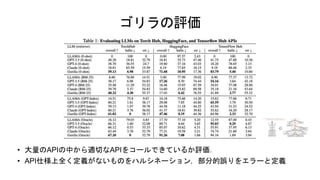
TorchHub: 94API • TensorFlowHub: 646API • HuggingFace: よく使われているモデル925API • 収集内容・方法 • APIドキュメントの収集(retrieverとして活用する) • {domain, framework, functionality, api_name, api-call, api_arguments, environment_requirements, example_code, performance, description} • GPT-4を用い,APIごとに10個のユーザ質問プロンプトを作成
14.
ゴリラの訓練・推論 • 生成したユーザプロンプトとAPIのペアでLLaMa- 7Bを教師ありfinetune(ゴリラ) • Retriever(APIドキュメントから検索させる)あ りとなし(ゼロショット)の2通りで訓練( retrieveを用いることで,単純な性能向上とAPI 仕様変更時の対応を期待) •
Retrieverありの場合プロンプトを加える:”Use this API documentation for reference: “ • 推論の場合もzero shotとretrieveのモードを利用可 能(Retrieverの場合は事前に関連するAPIドキュメ ントを検索した上で与える
15.
LLMに与えるプロンプトの例 ゼロショット Retriever利用
16.
ゴリラの評価 • 大量のAPIの中から適切なAPIをコールできているか評価. • API仕様上全く定義がないものをハルシネーション,部分的誤りをエラーと定義
17.
API仕様変更(Test Time Changs)への適応 •
APIドキュメントに( テスト時に )変更をかけて,対応できるか? • モデルの更新やモデルレジストリーの変更に柔軟に対応
18.
ゴリラとToolkenGPTの比較・まとめ • toolkenGPTは生成の途中で必要に応じてtoolを呼び出すイメージ(Toolformerと同様).Gorillaは自然言語によるAPIの検索システムに近いイ メージ. • ToolkenGPTではAPI選択した後は予め用意したコードでAPI・ツールを実行する想定だが,Gorillaではソースコードを直に生成.API仕様変更 への対応も考慮したパイプライン •
いずれの手法も手法自体の新規性というより,効果的にAPIを利用するためにLLMを調整するための軽微な工夫・パイプラインの提案 実現方法 シナリオ 出力内容 ベースモデル (実験設定) 扱っているAPI 学習データ生成方法 API仕様変更 ToolkenGPT LLMは固定 追加パラメータを学 習 LLMが必要な段階で 必要なAPIを呼び出 す APIコール結果を組 み合わせて文書合成 (API実行部分は別 途用意) LLaMa-13B GSM8K(数値計算 Knowledge basedQA VirtualHome 手動+LLMで生成 考慮なし(手動で対 応が必要) Gorilla LLMをfinetune ユーザの問い合わせ 内容に応じたAPIを 探して自動でコール APIコールするソー スコードを生成し, 実行 LLaMa-7B TorchHub TensorFlow Hub HuggingFace 手動+LLMで生成 APIドキュメント内 容から柔軟に対応
Download




![データセット・学習
• LLMの重みは固定でtoolken embeddingsを学習する
• 学習データの形式
• Toolkenを予測するタイミング,呼び出すAPI内容を指定.(N/Aは無視の意味合い)
• ”the”, “area”, “is”, “2”, “5”, “6”, “square”, “feet”, ...
• “the”, “area”, “is”, “ [square]”, “[N/A]”, “[N/A]”, “square”, “feet”, ...)
• →”2”の時点でsquareのツールを呼び出す.”2”でツールを呼び出すので,”5”,”6”は無視.
• データの作成
• 教師あり学習で利用するためにKBや計算トレースの自然言語文と正解のツールを前処理
• LLMで今回の構文を指定し,生成
• 上記で教師あり学習(LLM本体の重みは固定でtoolken embeddingsのみ更新)](https://image.slidesharecdn.com/202306021-230602054559-7bf893b2/85/DL-API-LLM-6-320.jpg)














![学振特別研究員になるために~知っておくべき10のTips~[平成28年度申請版]](https://cdn.slidesharecdn.com/ss_thumbnails/random-150226210930-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)
































