Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Takeshi Yamamuro
9,908 views
MLflowによる機械学習モデルのライフサイクルの管理
This is a slide for Spark Meetup Tokyo #1 (Spark+AI Summit 2019)
Technology
◦
Read more
10
Save
Share
Embed
Embed presentation
Download
Downloaded 41 times
1
/ 20
2
/ 20
3
/ 20
4
/ 20
5
/ 20
6
/ 20
7
/ 20
8
/ 20
9
/ 20
10
/ 20
11
/ 20
12
/ 20
Most read
13
/ 20
14
/ 20
15
/ 20
16
/ 20
Most read
17
/ 20
18
/ 20
Most read
19
/ 20
20
/ 20
More Related Content
PDF
入門 Kubeflow ~Kubernetesで機械学習をはじめるために~ (NTT Tech Conference #4 講演資料)
by
NTT DATA Technology & Innovation
PDF
ChatGPT 人間のフィードバックから強化学習した対話AI
by
Shota Imai
PPTX
先駆者に学ぶ MLOpsの実際
by
Tetsutaro Watanabe
PPTX
MLflowで学ぶMLOpsことはじめ
by
Kenichi Sonoda
PDF
AWSではじめるMLOps
by
MariOhbuchi
PPTX
MLOpsはバズワード
by
Tetsutaro Watanabe
PDF
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
入門 Kubeflow ~Kubernetesで機械学習をはじめるために~ (NTT Tech Conference #4 講演資料)
by
NTT DATA Technology & Innovation
ChatGPT 人間のフィードバックから強化学習した対話AI
by
Shota Imai
先駆者に学ぶ MLOpsの実際
by
Tetsutaro Watanabe
MLflowで学ぶMLOpsことはじめ
by
Kenichi Sonoda
AWSではじめるMLOps
by
MariOhbuchi
MLOpsはバズワード
by
Tetsutaro Watanabe
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
What's hot
PDF
見やすいプレゼン資料の作り方 - リニューアル増量版
by
MOCKS | Yuta Morishige
PPTX
ラボラトリーオートメーションのためのソフトウェア思想教育(非プログラマ―が知っておくべきプログラミングの本質)
by
Tokoroten Nakayama
PDF
ゼロから始める転移学習
by
Yahoo!デベロッパーネットワーク
PPTX
MLOps入門
by
Hiro Mura
PDF
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PPTX
心理的安全性と、Veinの紹介 Psychological safety and introduction of Vein
by
Tokoroten Nakayama
PDF
Elasticsearch の検索精度のチューニング 〜テストを作って高速かつ安全に〜
by
Takahiko Ito
PDF
シリコンバレーの「何が」凄いのか
by
Atsushi Nakada
PDF
AWS BlackBelt AWS上でのDDoS対策
by
Amazon Web Services Japan
PDF
協調フィルタリング入門
by
hoxo_m
PDF
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
PDF
AbemaTVにおける推薦システム
by
cyberagent
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PPTX
分散システムについて語らせてくれ
by
Kumazaki Hiroki
PPTX
MS COCO Dataset Introduction
by
Shinagawa Seitaro
PDF
tf,tf2完全理解
by
Koji Terada
PPTX
Tensor コアを使った PyTorch の高速化
by
Yusuke Fujimoto
見やすいプレゼン資料の作り方 - リニューアル増量版
by
MOCKS | Yuta Morishige
ラボラトリーオートメーションのためのソフトウェア思想教育(非プログラマ―が知っておくべきプログラミングの本質)
by
Tokoroten Nakayama
ゼロから始める転移学習
by
Yahoo!デベロッパーネットワーク
MLOps入門
by
Hiro Mura
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
Transformer メタサーベイ
by
cvpaper. challenge
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
心理的安全性と、Veinの紹介 Psychological safety and introduction of Vein
by
Tokoroten Nakayama
Elasticsearch の検索精度のチューニング 〜テストを作って高速かつ安全に〜
by
Takahiko Ito
シリコンバレーの「何が」凄いのか
by
Atsushi Nakada
AWS BlackBelt AWS上でのDDoS対策
by
Amazon Web Services Japan
協調フィルタリング入門
by
hoxo_m
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
AbemaTVにおける推薦システム
by
cyberagent
Attentionの基礎からTransformerの入門まで
by
AGIRobots
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
分散システムについて語らせてくれ
by
Kumazaki Hiroki
MS COCO Dataset Introduction
by
Shinagawa Seitaro
tf,tf2完全理解
by
Koji Terada
Tensor コアを使った PyTorch の高速化
by
Yusuke Fujimoto
Similar to MLflowによる機械学習モデルのライフサイクルの管理
PPTX
【DL輪読会】大量API・ツールの扱いに特化したLLM
by
Deep Learning JP
PPTX
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
by
Deep Learning JP
PDF
W&B webinar finetuning_配布用.pdf
by
Yuya Yamamoto
PPTX
MLOps NYC 2019 and Strata Data Conference NY 2019 report nttdata
by
NTT DATA Technology & Innovation
PPTX
Jupyter NotebookとChainerで楽々Deep Learning
by
Jun-ya Norimatsu
PPTX
LF AI & DataでのOSS活動と、それを富士社内で活用する話 - LF AI & Data Japan RUG Kick Off
by
Kosaku Kimura
PDF
Kubeflowで何ができて何ができないのか #DEvFest18
by
Shunya Ueta
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPT
Quick Overview of Upcoming Spark 3.0 + α
by
Takeshi Yamamuro
PDF
Tokyo H2O.ai Meetup#2 by Iida
by
Hidenori Fujioka
PPTX
DataEngConf NYC’18 セッションサマリー #2
by
gree_tech
PDF
Ocha_MLflow_MLOps.pdf
by
Kenichi Sonoda
PDF
「お手軽な機械学習サービス」で、ルーティンワークに立ち向かおう!
by
a know
PPTX
Pythonで入門するApache Spark at PyCon2016
by
Tatsuya Atsumi
PPTX
tfug-kagoshima
by
tak9029
PDF
Kuberflow Kubernetes上の機械学習プラットフォーム
by
Kosuke Kikuchi
PDF
2015-11-17 きちんと知りたいApache Spark ~機械学習とさまざまな機能群
by
Yu Ishikawa
PDF
Azure Machine Learning getting started
by
Masayuki Ota
PPTX
Using Deep Learning for Recommendation
by
Eduardo Gonzalez
PDF
2016-02-08 Spark MLlib Now and Beyond@Spark Conference Japan 2016
by
Yu Ishikawa
【DL輪読会】大量API・ツールの扱いに特化したLLM
by
Deep Learning JP
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
by
Deep Learning JP
W&B webinar finetuning_配布用.pdf
by
Yuya Yamamoto
MLOps NYC 2019 and Strata Data Conference NY 2019 report nttdata
by
NTT DATA Technology & Innovation
Jupyter NotebookとChainerで楽々Deep Learning
by
Jun-ya Norimatsu
LF AI & DataでのOSS活動と、それを富士社内で活用する話 - LF AI & Data Japan RUG Kick Off
by
Kosaku Kimura
Kubeflowで何ができて何ができないのか #DEvFest18
by
Shunya Ueta
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
Quick Overview of Upcoming Spark 3.0 + α
by
Takeshi Yamamuro
Tokyo H2O.ai Meetup#2 by Iida
by
Hidenori Fujioka
DataEngConf NYC’18 セッションサマリー #2
by
gree_tech
Ocha_MLflow_MLOps.pdf
by
Kenichi Sonoda
「お手軽な機械学習サービス」で、ルーティンワークに立ち向かおう!
by
a know
Pythonで入門するApache Spark at PyCon2016
by
Tatsuya Atsumi
tfug-kagoshima
by
tak9029
Kuberflow Kubernetes上の機械学習プラットフォーム
by
Kosuke Kikuchi
2015-11-17 きちんと知りたいApache Spark ~機械学習とさまざまな機能群
by
Yu Ishikawa
Azure Machine Learning getting started
by
Masayuki Ota
Using Deep Learning for Recommendation
by
Eduardo Gonzalez
2016-02-08 Spark MLlib Now and Beyond@Spark Conference Japan 2016
by
Yu Ishikawa
More from Takeshi Yamamuro
PDF
浮動小数点(IEEE754)を圧縮したい@dsirnlp#4
by
Takeshi Yamamuro
PDF
Apache Spark + Arrow
by
Takeshi Yamamuro
PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
by
Takeshi Yamamuro
PDF
An Experimental Study of Bitmap Compression vs. Inverted List Compression
by
Takeshi Yamamuro
PDF
研究動向から考えるx86/x64最適化手法
by
Takeshi Yamamuro
PDF
20160908 hivemall meetup
by
Takeshi Yamamuro
PPTX
LLJVM: LLVM bitcode to JVM bytecode
by
Takeshi Yamamuro
PDF
VLDB’11勉強会 -Session 9-
by
Takeshi Yamamuro
PDF
SIGMOD’12勉強会 -Session 7-
by
Takeshi Yamamuro
PDF
Introduction to Modern Analytical DB
by
Takeshi Yamamuro
PDF
20180417 hivemall meetup#4
by
Takeshi Yamamuro
PDF
VLDB2013 R1 Emerging Hardware
by
Takeshi Yamamuro
PDF
Taming Distributed/Parallel Query Execution Engine of Apache Spark
by
Takeshi Yamamuro
PDF
Sparkのクエリ処理系と周辺の話題
by
Takeshi Yamamuro
PDF
20150513 legobease
by
Takeshi Yamamuro
PDF
LT: Spark 3.1 Feature Expectation
by
Takeshi Yamamuro
PDF
VLDB'10勉強会 -Session 20-
by
Takeshi Yamamuro
PDF
20150516 icde2015 r19-4
by
Takeshi Yamamuro
PDF
VAST-Tree, EDBT'12
by
Takeshi Yamamuro
PDF
A x86-optimized rank&select dictionary for bit sequences
by
Takeshi Yamamuro
浮動小数点(IEEE754)を圧縮したい@dsirnlp#4
by
Takeshi Yamamuro
Apache Spark + Arrow
by
Takeshi Yamamuro
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
by
Takeshi Yamamuro
An Experimental Study of Bitmap Compression vs. Inverted List Compression
by
Takeshi Yamamuro
研究動向から考えるx86/x64最適化手法
by
Takeshi Yamamuro
20160908 hivemall meetup
by
Takeshi Yamamuro
LLJVM: LLVM bitcode to JVM bytecode
by
Takeshi Yamamuro
VLDB’11勉強会 -Session 9-
by
Takeshi Yamamuro
SIGMOD’12勉強会 -Session 7-
by
Takeshi Yamamuro
Introduction to Modern Analytical DB
by
Takeshi Yamamuro
20180417 hivemall meetup#4
by
Takeshi Yamamuro
VLDB2013 R1 Emerging Hardware
by
Takeshi Yamamuro
Taming Distributed/Parallel Query Execution Engine of Apache Spark
by
Takeshi Yamamuro
Sparkのクエリ処理系と周辺の話題
by
Takeshi Yamamuro
20150513 legobease
by
Takeshi Yamamuro
LT: Spark 3.1 Feature Expectation
by
Takeshi Yamamuro
VLDB'10勉強会 -Session 20-
by
Takeshi Yamamuro
20150516 icde2015 r19-4
by
Takeshi Yamamuro
VAST-Tree, EDBT'12
by
Takeshi Yamamuro
A x86-optimized rank&select dictionary for bit sequences
by
Takeshi Yamamuro
MLflowによる機械学習モデルのライフサイクルの管理
1.
Copyright©2019 NTT corp.
All Rights Reserved. MLflowによる機械学習モデルの ライフサイクルの管理 Takeshi Yamamuro, NTT このスライドは以下の発表を参考に作成しています [1] Matei Zaharia, Accelerating Machine Learning Development with MLflow, XLDB2019
2.
2Copyright©2019 NTT corp.
All Rights Reserved. ⾃⼰紹介
3.
3Copyright©2019 NTT corp.
All Rights Reserved. お知らせ - https://bit.ly/30Sh4MU
4.
4Copyright©2019 NTT corp.
All Rights Reserved. MLflow 1.0リリース https://bit.ly/2Iq1j7F aa$ pip install mlflow==1.0.0
5.
5Copyright©2019 NTT corp.
All Rights Reserved. • 企業での機械学習の利⽤は「前処理→モデル学習→デプ ロイ」のライフサイクルで構成されることが多い 機械学習モデルのライフサイクルと特徴 [1]のp4から引用 • データは変化するため,このサ イクルを繰り返す • 複数⼈が似た(もしくは同じ) タスクで学習を⾏う • 実⾏環境や前処理・モデル学習 に⽤いるライブラリは⼈や時代 によって様々
6.
6Copyright©2019 NTT corp.
All Rights Reserved. • MLflowは企業における機械学習モデルの再現性や再利 ⽤性を向上させるための機能を提供 • 先⾏する取り組みにTFX@Google,FBLearner@Facebook, Michelangelo@Uberなど • MLflowは以下3つの機能を提供 • MLflow Tracking: 追跡性と再現性を⾼めるため,学習条件やスコアなど実験 内容を記録するロギングフレームワークを提供 • MLflow Projects: 再利⽤性を⾼めるため,学習スクリプトの実⾏環境の再現 と起動(パラメータの与え⽅など)を⽀援 • MLflow Models: 学習モデルのフォーマットを定め,デプロイを⽀援 MLflowは何をしてくれるの?
7.
7Copyright©2019 NTT corp.
All Rights Reserved. • ライブラリ⾮依存性(Library-Agnostic) • MLflow⾃体に前処理や学習を⾏う機能があるわけではなく, あくまで既存のライブラリ(pandas,scikit-learn, XGBoost/LightGBM,PyTorch,Spark,TensorFlowなど) を⽀援する位置づけ MLflowは何をしてくれるの?
8.
8Copyright©2019 NTT corp.
All Rights Reserved. • ログ記録のためのAPIsと,記録されたログを確認・⽐ 較するためのViewを提供 MLflow Tracking MLflow Web UIs ([1]のp10から引用) # 学習条件の記録 mlflow.log_param(‘training_data’, data) mlflow.log_param(‘n’, n) mlflow.log_param(‘learning_rate’, lr) # スコアの記録 mlflow.log_metric(‘score’, rmse) # 学習したモデルの記録 mlflow.sklearn.log_model(clf)
9.
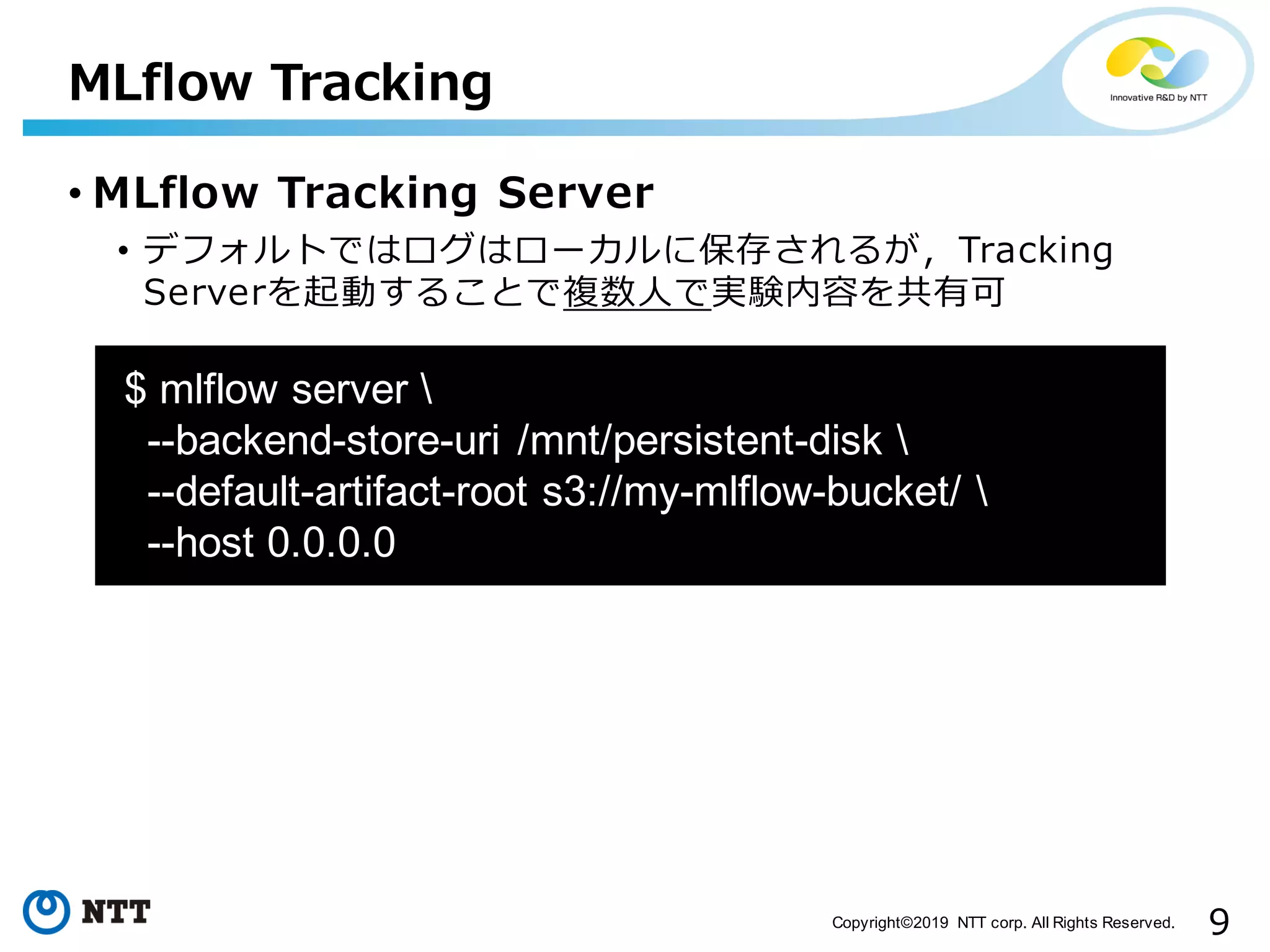
9Copyright©2019 NTT corp.
All Rights Reserved. • MLflow Tracking Server • デフォルトではログはローカルに保存されるが,Tracking Serverを起動することで複数⼈で実験内容を共有可 MLflow Tracking $ mlflow server --backend-store-uri /mnt/persistent-disk --default-artifact-root s3://my-mlflow-bucket/ --host 0.0.0.0
10.
10Copyright©2019 NTT corp.
All Rights Reserved. MLflow Projects • 簡潔なパッケージフォーマットを提供 • conda(もしくはdocker)を使った学習スクリプトの依存関係 の解決,学習スクリプトの実⾏を⾃動化 MLProjectの内容(Makefile的なもの)
11.
11Copyright©2019 NTT corp.
All Rights Reserved. MLflow Projects • 実⾏は「mlflow run <project path>」 • Makefileのmake的なもの • <project path>にはgitのURI(git://...)も⼊⼒可能
12.
12Copyright©2019 NTT corp.
All Rights Reserved. MLflow Models [1]のp18から引用
13.
13Copyright©2019 NTT corp.
All Rights Reserved. • 公式ドキュメント • https://www.mlflow.org/docs/latest/index.html • 公式のexamples • https://github.com/mlflow/mlflow/tree/master/examples • ⽤途ごとに例があるのでテンプレートとして使いやすいかも • Spark+AI Summit 2019でのチュートリアル • Managing the Complete Machine Learning Lifecycle with MLflow • https://github.com/amesar/mlflow-spark-summit-2019 MLflowを始めるうえで参考になりそうな情報
14.
14Copyright©2019 NTT corp.
All Rights Reserved. • 1.0リリースに関して@Keynote • Accelerating the Machine Learning Lifecycle with MLflow 1.0 • ハイパーパラメータチューニングの⽅法論とMLflowによる実践 • Best Practices for Hyperparameter Tuning with MLflow • Advanced Hyperparameter Optimization for Deep Learning with MLflow • 前処理・学習をMLflowで管理し,Kubeflow環境にデプロイ • How to Utilize MLflow and Kubernetes to Build an Enterprise ML Platform その他のSummitでの関連発表
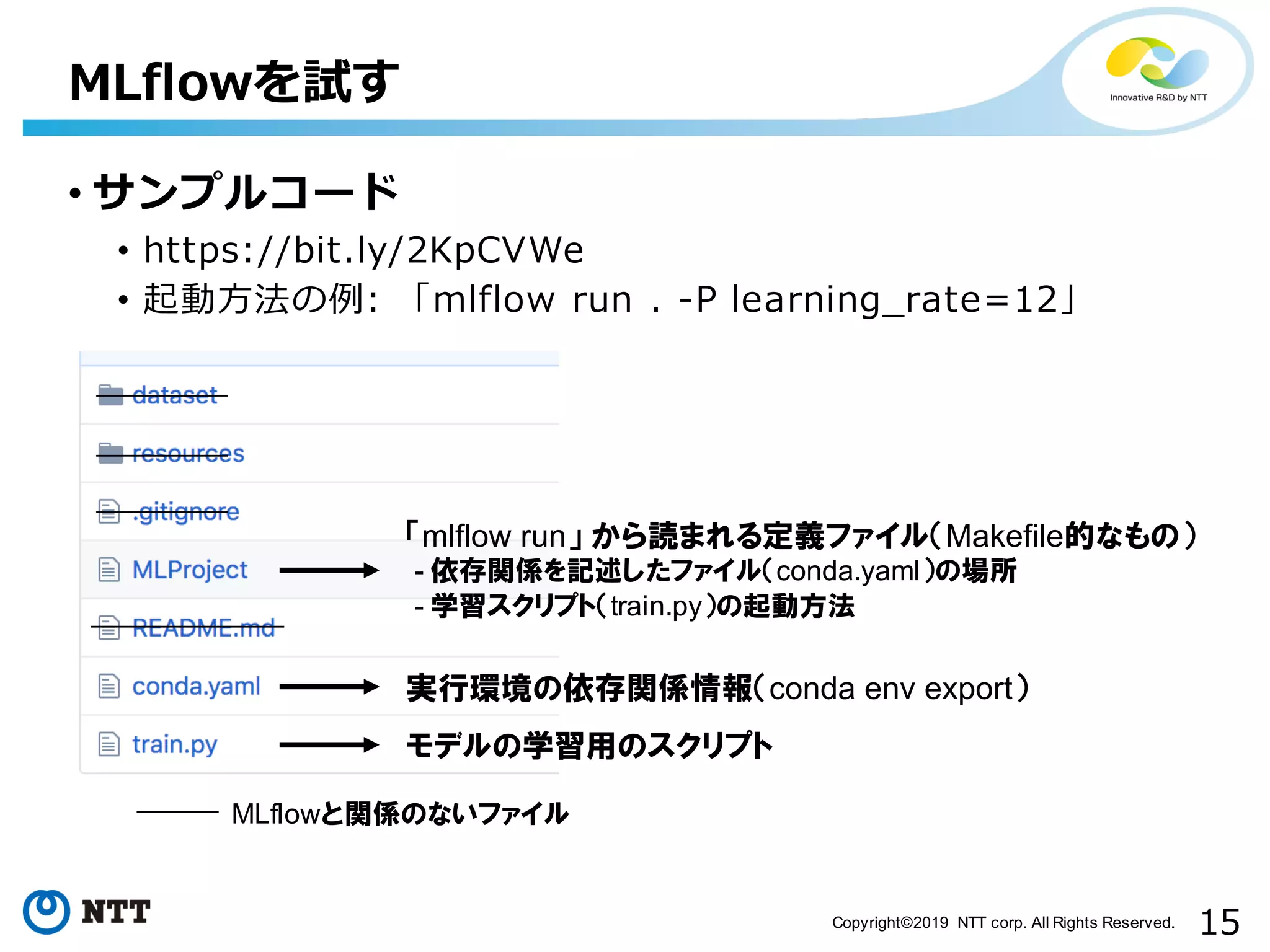
15.
15Copyright©2019 NTT corp.
All Rights Reserved. • サンプルコード • https://bit.ly/2KpCVWe • 起動⽅法の例: 「mlflow run . -P learning_rate=12」 MLflowを試す モデルの学習用のスクリプト 実行環境の依存関係情報(conda env export) 「mlflow run」 から読まれる定義ファイル(Makefile的なもの) - 依存関係を記述したファイル(conda.yaml)の場所 - 学習スクリプト(train.py)の起動方法 MLflowと関係のないファイル
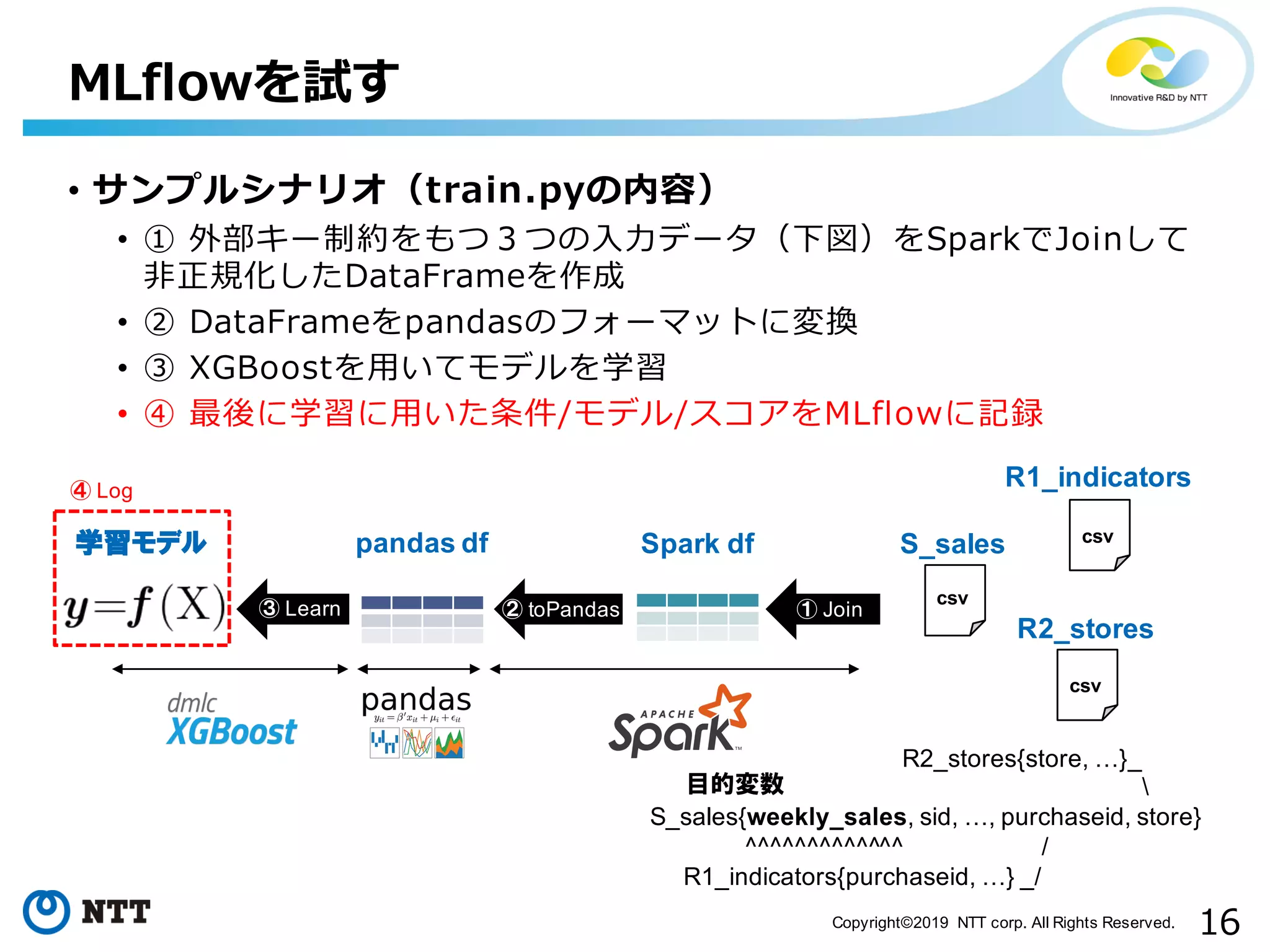
16.
16Copyright©2019 NTT corp.
All Rights Reserved. • サンプルシナリオ(train.pyの内容) • ① 外部キー制約をもつ3つの⼊⼒データ(下図)をSparkでJoinして ⾮正規化したDataFrameを作成 • ② DataFrameをpandasのフォーマットに変換 • ③ XGBoostを⽤いてモデルを学習 • ④ 最後に学習に⽤いた条件/モデル/スコアをMLflowに記録 MLflowを試す S_sales R1_indicators R2_stores csv csv csv Spark dfpandas df学習モデル ② toPandas ① Join③ Learn R2_stores{store, …}_ S_sales{weekly_sales, sid, …, purchaseid, store} ^^^^^^^^^^^^^ / R1_indicators{purchaseid, …} _/ 目的変数 ④ Log
17.
17Copyright©2019 NTT corp.
All Rights Reserved. • Web UIs上でモデル学習のログを確認 MLflowを試す スコアが最も良い条件
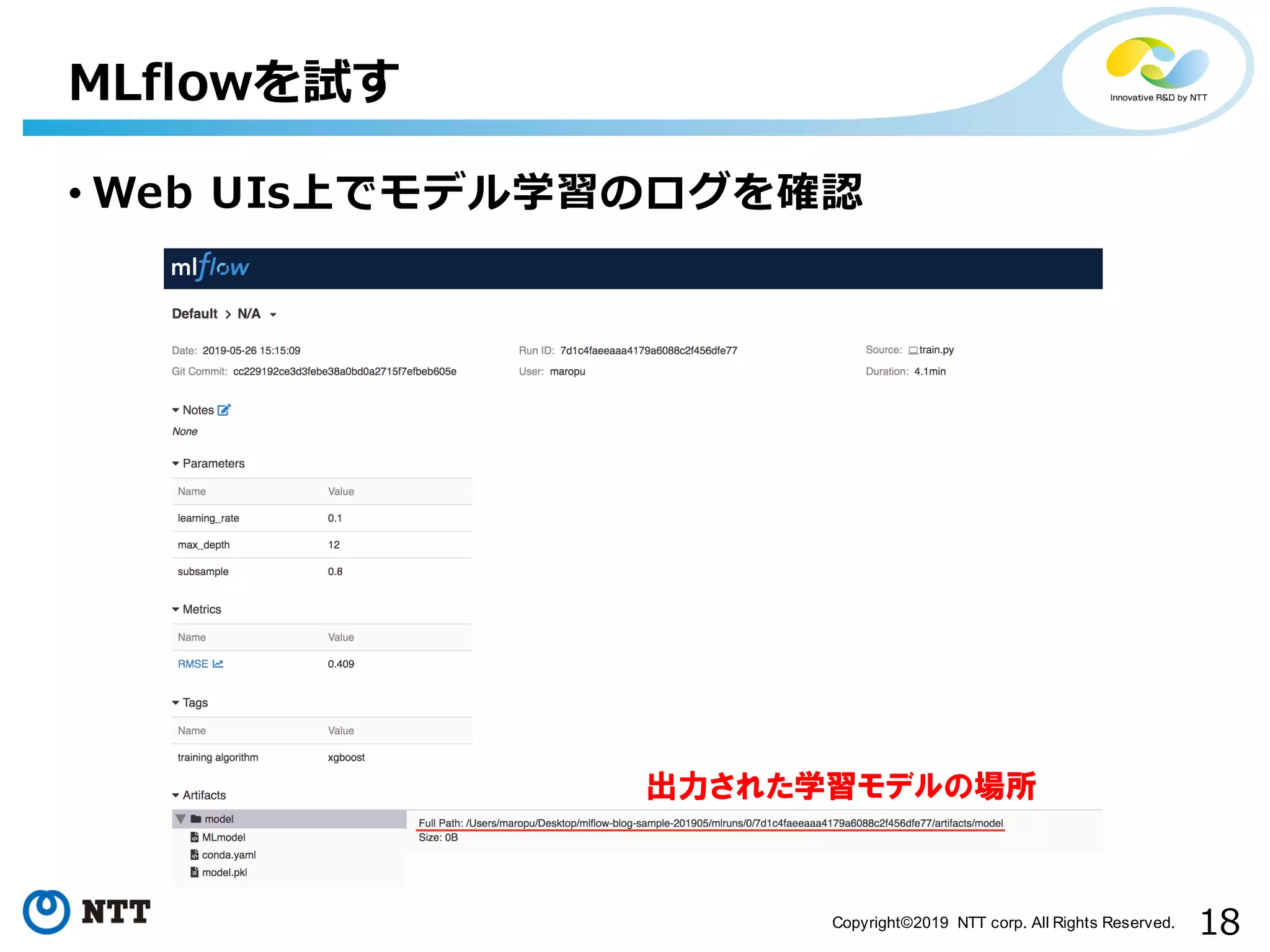
18.
18Copyright©2019 NTT corp.
All Rights Reserved. • Web UIs上でモデル学習のログを確認 MLflowを試す 出力された学習モデルの場所
19.
19Copyright©2019 NTT corp.
All Rights Reserved. • 学習したモデルをデプロイ MLflowを試す aa // 「mlflow pyfunc」でRESTサーバにデプロイ $ mlflow pyfunc serve -p 4321 -m <学習モデルの場所> • Running on http://127.0.0.1:4321/ (Press CTRL+C to quit) aa $ curl -X POST -H “Content-Type:application/json;format=pandas-split” --data ‘<特徴量ベクトル>’ http://127.0.0.1:4321/invocations [4]
20.
20Copyright©2019 NTT corp.
All Rights Reserved. • 覚えることが少なく,⾮常にシンプルな設計 • この⼿のツールは覚えなければいけない”お約束”が多く導⼊コ ストが⾼い印象があるが,その⼼配は少ない • モデル構築に使⽤したスクリプトが既にあるのであれば, importして学習に⽤いた条件/モデル/スコアを記録するように 数⾏エントリを追加するだけでも⼤丈夫そう • プラガブルな設計による⾼い拡張性 • 独⾃の学習アルゴリズム実装を使っていても簡単に対応可能 • また今後流⾏る学習ライブラリが出てきた場合にでもコミュニ ティとして容易に追従可能 MLflowに関する所感
Download
![Copyright©2019 NTT corp. All Rights Reserved.
MLflowによる機械学習モデルの
ライフサイクルの管理
Takeshi Yamamuro, NTT
このスライドは以下の発表を参考に作成しています
[1] Matei Zaharia, Accelerating Machine Learning Development
with MLflow, XLDB2019](https://image.slidesharecdn.com/20190612sparktokyomeetup-190612063102/75/MLflow-1-2048.jpg)



![5Copyright©2019 NTT corp. All Rights Reserved.
• 企業での機械学習の利⽤は「前処理→モデル学習→デプ
ロイ」のライフサイクルで構成されることが多い
機械学習モデルのライフサイクルと特徴
[1]のp4から引用
• データは変化するため,このサ
イクルを繰り返す
• 複数⼈が似た(もしくは同じ)
タスクで学習を⾏う
• 実⾏環境や前処理・モデル学習
に⽤いるライブラリは⼈や時代
によって様々](https://image.slidesharecdn.com/20190612sparktokyomeetup-190612063102/75/MLflow-5-2048.jpg)


![8Copyright©2019 NTT corp. All Rights Reserved.
• ログ記録のためのAPIsと,記録されたログを確認・⽐
較するためのViewを提供
MLflow Tracking
MLflow Web UIs ([1]のp10から引用)
# 学習条件の記録
mlflow.log_param(‘training_data’, data)
mlflow.log_param(‘n’, n)
mlflow.log_param(‘learning_rate’, lr)
# スコアの記録
mlflow.log_metric(‘score’, rmse)
# 学習したモデルの記録
mlflow.sklearn.log_model(clf)](https://image.slidesharecdn.com/20190612sparktokyomeetup-190612063102/75/MLflow-8-2048.jpg)


![12Copyright©2019 NTT corp. All Rights Reserved.
MLflow Models
[1]のp18から引用](https://image.slidesharecdn.com/20190612sparktokyomeetup-190612063102/75/MLflow-12-2048.jpg)



![19Copyright©2019 NTT corp. All Rights Reserved.
• 学習したモデルをデプロイ
MLflowを試す
aa
// 「mlflow pyfunc」でRESTサーバにデプロイ
$ mlflow pyfunc serve -p 4321 -m <学習モデルの場所>
• Running on http://127.0.0.1:4321/ (Press CTRL+C to quit)
aa
$ curl -X POST -H “Content-Type:application/json;format=pandas-split”
--data ‘<特徴量ベクトル>’ http://127.0.0.1:4321/invocations
[4]](https://image.slidesharecdn.com/20190612sparktokyomeetup-190612063102/75/MLflow-19-2048.jpg)





































































