Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Deep Learning JP
PPTX, PDF
1,296 views
【DL輪読会】"A Generalist Agent"
2022/06/03 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 22 times
1
/ 17
2
/ 17
3
/ 17
4
/ 17
5
/ 17
6
/ 17
7
/ 17
8
/ 17
9
/ 17
10
/ 17
11
/ 17
12
/ 17
13
/ 17
14
/ 17
15
/ 17
16
/ 17
17
/ 17
More Related Content
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PPTX
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PDF
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
What's hot
PPTX
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
PDF
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
by
SSII
PDF
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
PDF
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
PPTX
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
by
Deep Learning JP
PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
PPTX
[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...
by
Deep Learning JP
PDF
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
PDF
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PPTX
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
Generative Models(メタサーベイ )
by
cvpaper. challenge
PPTX
[DL輪読会]When Does Label Smoothing Help?
by
Deep Learning JP
PPTX
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
by
SSII
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
by
Deep Learning JP
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...
by
Deep Learning JP
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
Transformer メタサーベイ
by
cvpaper. challenge
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
Generative Models(メタサーベイ )
by
cvpaper. challenge
[DL輪読会]When Does Label Smoothing Help?
by
Deep Learning JP
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
Similar to 【DL輪読会】"A Generalist Agent"
PDF
[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...
by
Deep Learning JP
PDF
生成モデルの Deep Learning
by
Seiya Tokui
PPTX
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
PDF
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
PDF
強化学習技術とゲーム AI 〜 今できる事と今後できて欲しい事 〜
by
佑 甲野
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PDF
【参考文献追加】20180115_東大医学部機能生物学セミナー_深層学習の最前線とこれから_岡野原大輔
by
Preferred Networks
PDF
20180115_東大医学部機能生物学セミナー_深層学習の最前線とこれから_岡野原大輔
by
Preferred Networks
PDF
Generative Deep Learning #01
by
逸人 米田
PPTX
[DL輪読会]大規模分散強化学習の難しい問題設定への適用
by
Deep Learning JP
PDF
[DL輪読会]Measuring abstract reasoning in neural networks
by
Deep Learning JP
PDF
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
PDF
AI入門
by
iPride Co., Ltd.
PDF
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
PPTX
[DL輪読会]Grandmaster level in StarCraft II using multi-agent reinforcement lear...
by
Deep Learning JP
PPTX
【DL輪読会】Emergent World Representations: Exploring a Sequence ModelTrained on a...
by
Deep Learning JP
PDF
Learning to Navigate in Complex Environments 輪読
by
Tatsuya Matsushima
PPTX
【DL輪読会】Reward Design with Language Models
by
Deep Learning JP
PPTX
【DL輪読会】Scale Efficiently: Insights from Pre-training and Fine-tuning Transfor...
by
Deep Learning JP
[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...
by
Deep Learning JP
生成モデルの Deep Learning
by
Seiya Tokui
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
強化学習技術とゲーム AI 〜 今できる事と今後できて欲しい事 〜
by
佑 甲野
Deep Learningの基礎と応用
by
Seiya Tokui
【参考文献追加】20180115_東大医学部機能生物学セミナー_深層学習の最前線とこれから_岡野原大輔
by
Preferred Networks
20180115_東大医学部機能生物学セミナー_深層学習の最前線とこれから_岡野原大輔
by
Preferred Networks
Generative Deep Learning #01
by
逸人 米田
[DL輪読会]大規模分散強化学習の難しい問題設定への適用
by
Deep Learning JP
[DL輪読会]Measuring abstract reasoning in neural networks
by
Deep Learning JP
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
AI入門
by
iPride Co., Ltd.
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
[DL輪読会]Grandmaster level in StarCraft II using multi-agent reinforcement lear...
by
Deep Learning JP
【DL輪読会】Emergent World Representations: Exploring a Sequence ModelTrained on a...
by
Deep Learning JP
Learning to Navigate in Complex Environments 輪読
by
Tatsuya Matsushima
【DL輪読会】Reward Design with Language Models
by
Deep Learning JP
【DL輪読会】Scale Efficiently: Insights from Pre-training and Fine-tuning Transfor...
by
Deep Learning JP
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】"A Generalist Agent"
1.
1 DEEP LEARNING JP [DL
Papers] http://deeplearning.jp/ A Generalist Agent Presenter: Manato Yaguchi (Hokkaido university, B3)
2.
書誌情報 • タイトル: A
Generalist Agent • 著者:DeepMind社の研究チーム • 論文: A Generalist Agent (deepmind.com) (05/22) • 概要:言語モデルの範疇にとどまらず、強化学習等のより広い領域で適用可 能な大規模モデルを構築することを行った研究 - 画像のキャプション生成や、対話や、ブロックを積むタスクなど
3.
概要 • GPT-3のような大規模言語モデル を、制御問題やロボティックス領 域のdataも扱えるように拡張 • 異なるモダリティーのデータを1 つのモデルで扱うため、モダリ ティ―毎にtokenizeとembedding を行っている(e.g.
text, 画像)
4.
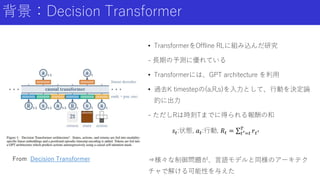
背景:Decision Transformer • TransformerをOffline
RLに組み込んだ研究 - 長期の予測に優れている • Transformerには、GPT architecture を利用 • 過去K timestepの(a,R,s)を入力として、行動を決定論 的に出力 - ただしRは時刻Tまでに得られる報酬の和 𝑠𝑡:状態, 𝑎𝑡:行動, 𝑅𝑡 = 𝑡′=𝑡 𝑇 𝑟𝑡′ ⇒様々な制御問題が、言語モデルと同様のアーキテク チャで解ける可能性を与えた From Decision Transformer
5.
Tokenize 扱うデータによって、tokenizeの方法が異なる • Text:32,000のsubwordをもつSentencePieceによって、[0,32000)の整数 型に変換 • Image:ViTと同様にraster
orderでパッチに分割後、各ピクセルを[-1,1] で正規化し、パッチサイズの平方根で割る • 離散値:row-major order で一列に並べる。各要素は[0,1024)の整数型 • 連続値:row-major order で浮動小数点値を1列に並べる。その後[-1,1]で mu-lawエンコードして、1024のビンで離散化し、+32,000する。 From Vision Transformer
6.
Tokenize・Embedding • 観測情報([y,x,z]): • y:
text token • X: image patch token • Z: 離散値や連続値であらわされる観測情報 • 行動情報(a) を用いて、すべてのtokenは以下のように纏められる。 この一連のデータを各トークンについて、パラメータ化されたembedding関数𝑓(・ ; 𝜃𝑒)に通す。 ※ embedding関数は、各モダリティに応じて異なる振る舞いをする
7.
Tokenize・Embedding • row-major order
で浮動小数点値を1列に並べる。その後[-1,1]でmu-lawエンコードして、 1024のビンで離散化し、32,000を足す.(textの区間[0,32000)と被らないようにする) • mu-law encodeの式(区間[-1,1]に圧縮):
8.
画像データのTokenize・Embedding • ViTと同様にraster orderでパッチ に分割後、各ピクセルを[-1,1]で 正規化し、パッチサイズの平方根 で割る •
各パッチごとにResNetに通し、 Embdddingを行う。この際、学習 可能なPosition Encodingも行う 2010.11929.pdf (arxiv.org)
9.
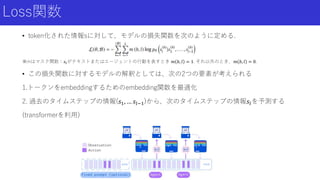
Loss関数 • token化された情報sに対して、モデルの損失関数を次のように定める. ※mはマスク関数:𝑠𝑙がテキストまたはエージェントの行動を表すとき 𝑚
𝑏, 𝑙 = 1. それ以外のとき、𝑚 𝑏, 𝑙 = 0. • この損失関数に対するモデルの解釈としては、次の2つの要素が考えられる 1.トークンをembeddingするためのembedding関数を最適化 2. 過去のタイムステップの情報(𝑠1, … 𝑠𝑙−1)から、次のタイムステップの情報𝑠𝑙を予測する (transformerを利用)
10.
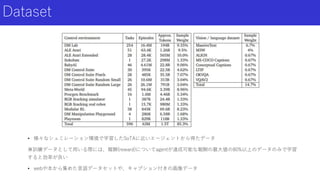
Dataset • 様々なシュミレーション環境で学習したSoTAに近いエージェントから得たデータ ※訓練データとして用いる際には、報酬(reward)についてagentが達成可能な報酬の最大値の80%以上のデータのみで学習 すると効率が良い • webや本から集めた言語データセットや、キャプション付きの画像データ
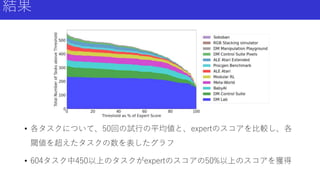
11.
結果 • 各タスクについて、50回の試行の平均値と、expertのスコアを比較し、各 閾値を超えたタスクの数を表したグラフ • 604タスク中450以上のタスクがexpertのスコアの50%以上のスコアを獲得
12.
結果 • ロボットが色のついたブロックを積めるかを試したタスク • このタスクに特化したベースラインモデル(BC-IMP)と同程度の結果
13.
結果 • 画像に対するキャプション生成を行った結果 • 画像や、テキストに対しても一定の結果を残している
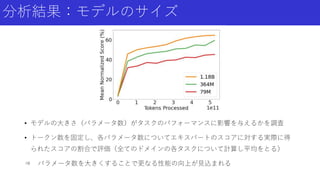
14.
分析結果:モデルのサイズ • モデルの大きさ(パラメータ数)がタスクのパフォーマンスに影響を与えるかを調査 • トークン数を固定し、各パラメータ数についてエキスパートのスコアに対する実際に得 られたスコアの割合で評価(全てのドメインの各タスクについて計算し平均をとる) ⇒
パラメータ数を大きくすることで更なる性能の向上が見込まれる
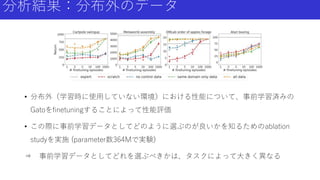
15.
分析結果:分布外のデータ • 分布外(学習時に使用していない環境)における性能について、事前学習済みの Gatoをfinetuningすることによって性能評価 • この際に事前学習データとしてどのように選ぶのが良いかを知るためのablation studyを実施
(parameter数364Mで実験) ⇒ 事前学習データとしてどれを選ぶべきかは、タスクによって大きく異なる
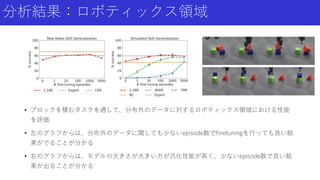
16.
分析結果:ロボティックス領域 • ブロックを積むタスクを通して、分布外のデータに対するロボティックス領域における性能 を評価 • 左のグラフからは、分布外のデータに関しても少ないepisode数でfinetuningを行っても良い結 果がでることが分かる •
右のグラフからは、モデルの大きさが大きい方が汎化性能が高く、少ないepisode数で良い結 果が出ることが分かる
17.
まとめ • Transformerベースのシーケンスモデルが、様々な分野のタスクにおいて 有用であることを示した • few-shot学習による分布外のタスクに対しても一定の性能を残した •
モデルのスケール(パラメータ数)を大きくすることで、更なる性能の向 上が見込まれると主張
Download
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
A Generalist Agent
Presenter: Manato Yaguchi (Hokkaido university, B3)](https://image.slidesharecdn.com/20220603yaguchi-220603032626-b425a170/85/DL-A-Generalist-Agent-1-320.jpg)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
A Generalist Agent
Presenter: Manato Yaguchi (Hokkaido university, B3)](https://image.slidesharecdn.com/20220603yaguchi-220603032626-b425a170/75/DL-A-Generalist-Agent-1-2048.jpg)

![Tokenize
扱うデータによって、tokenizeの方法が異なる
• Text:32,000のsubwordをもつSentencePieceによって、[0,32000)の整数
型に変換
• Image:ViTと同様にraster orderでパッチに分割後、各ピクセルを[-1,1]
で正規化し、パッチサイズの平方根で割る
• 離散値:row-major order で一列に並べる。各要素は[0,1024)の整数型
• 連続値:row-major order で浮動小数点値を1列に並べる。その後[-1,1]で
mu-lawエンコードして、1024のビンで離散化し、+32,000する。 From Vision Transformer](https://image.slidesharecdn.com/20220603yaguchi-220603032626-b425a170/85/DL-A-Generalist-Agent-5-320.jpg)
![Tokenize・Embedding
• 観測情報([y,x,z]):
• y: text token
• X: image patch token
• Z: 離散値や連続値であらわされる観測情報
• 行動情報(a)
を用いて、すべてのtokenは以下のように纏められる。
この一連のデータを各トークンについて、パラメータ化されたembedding関数𝑓(・
; 𝜃𝑒)に通す。
※ embedding関数は、各モダリティに応じて異なる振る舞いをする](https://image.slidesharecdn.com/20220603yaguchi-220603032626-b425a170/85/DL-A-Generalist-Agent-6-320.jpg)
![Tokenize・Embedding
• row-major order で浮動小数点値を1列に並べる。その後[-1,1]でmu-lawエンコードして、
1024のビンで離散化し、32,000を足す.(textの区間[0,32000)と被らないようにする)
• mu-law encodeの式(区間[-1,1]に圧縮):](https://image.slidesharecdn.com/20220603yaguchi-220603032626-b425a170/85/DL-A-Generalist-Agent-7-320.jpg)
![画像データのTokenize・Embedding
• ViTと同様にraster orderでパッチ
に分割後、各ピクセルを[-1,1]で
正規化し、パッチサイズの平方根
で割る
• 各パッチごとにResNetに通し、
Embdddingを行う。この際、学習
可能なPosition Encodingも行う
2010.11929.pdf (arxiv.org)](https://image.slidesharecdn.com/20220603yaguchi-220603032626-b425a170/85/DL-A-Generalist-Agent-8-320.jpg)




![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...](https://cdn.slidesharecdn.com/ss_thumbnails/20210729kokiyamane-210730035349-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksshioya201707281-170728054152-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]大規模分散強化学習の難しい問題設定への適用](https://cdn.slidesharecdn.com/ss_thumbnails/drlapplication-180921001838-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Measuring abstract reasoning in neural networks](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi0727-180727002112-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Grandmaster level in StarCraft II using multi-agent reinforcement lear...](https://cdn.slidesharecdn.com/ss_thumbnails/alphastarfinal-191227002114-thumbnail.jpg?width=640&height=640&fit=bounds)























