Downloaded 607 times


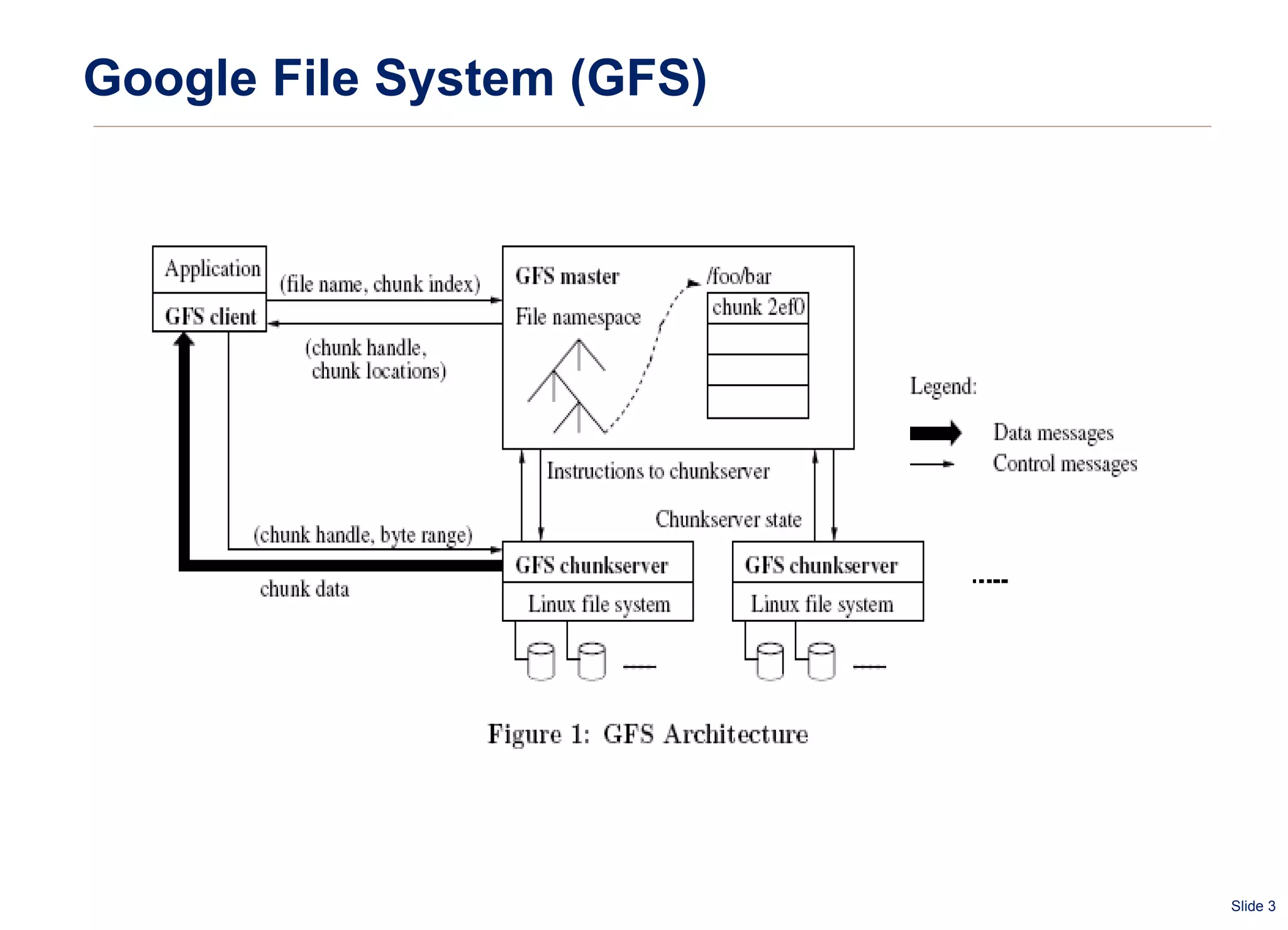





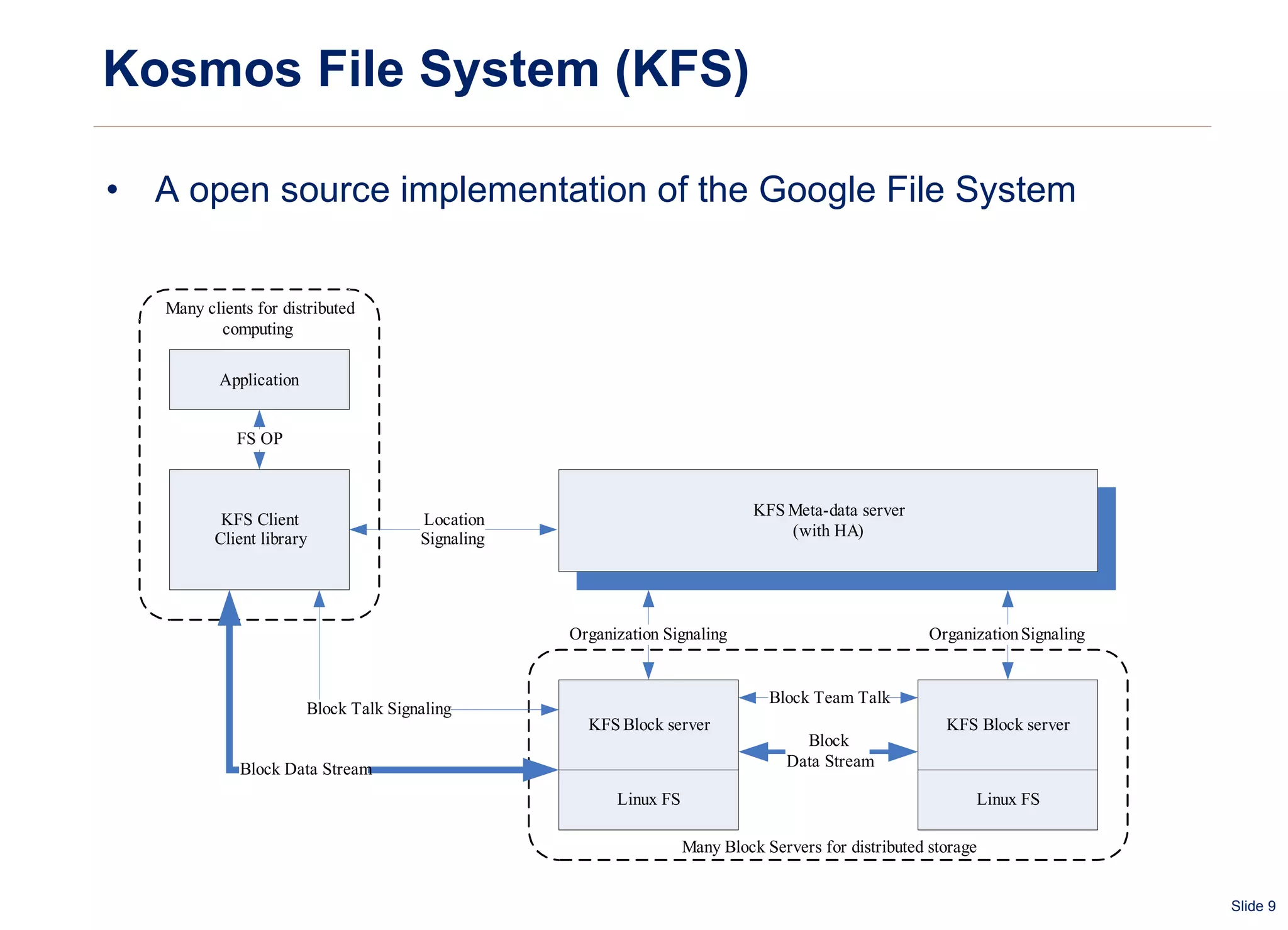


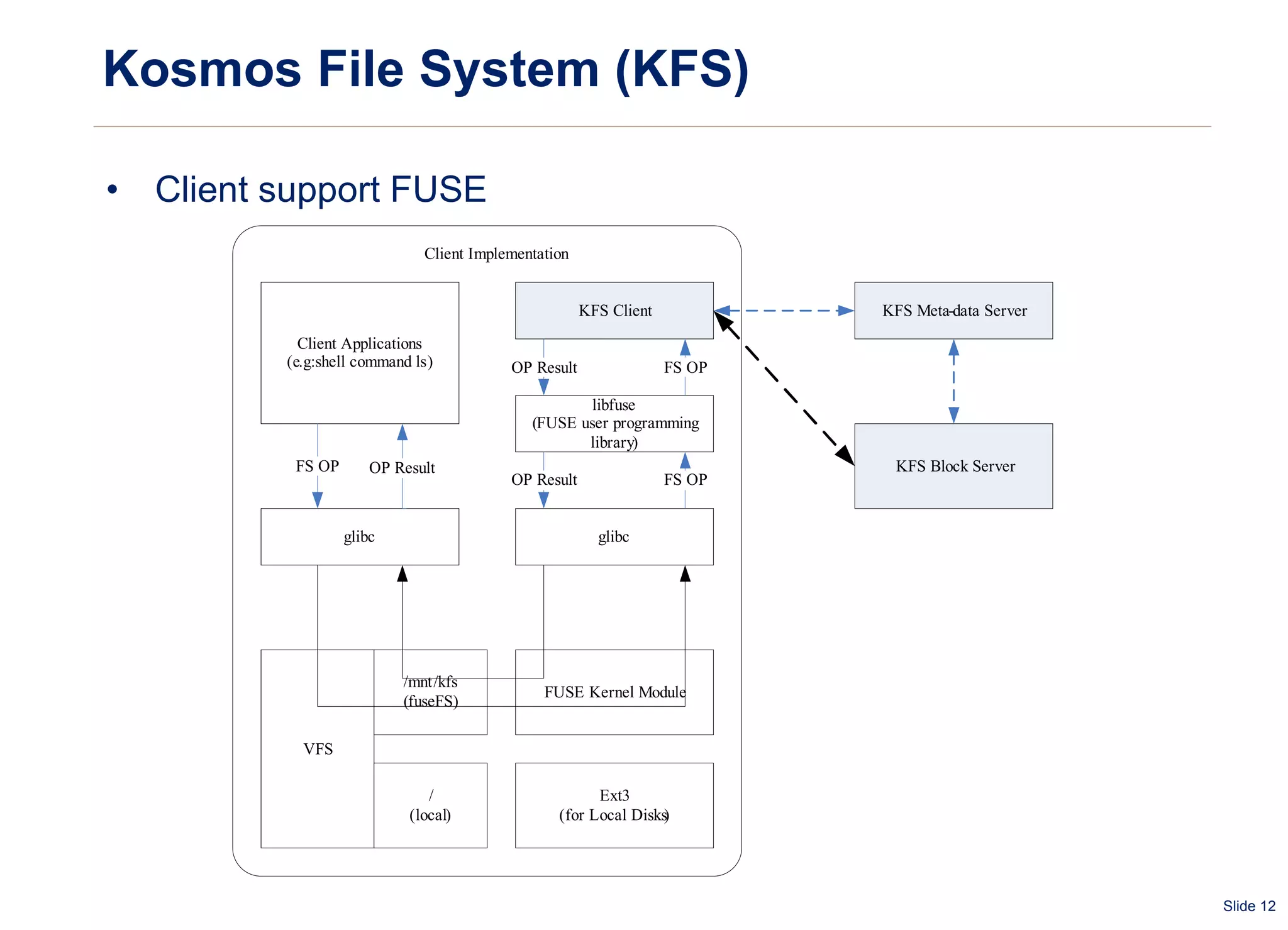

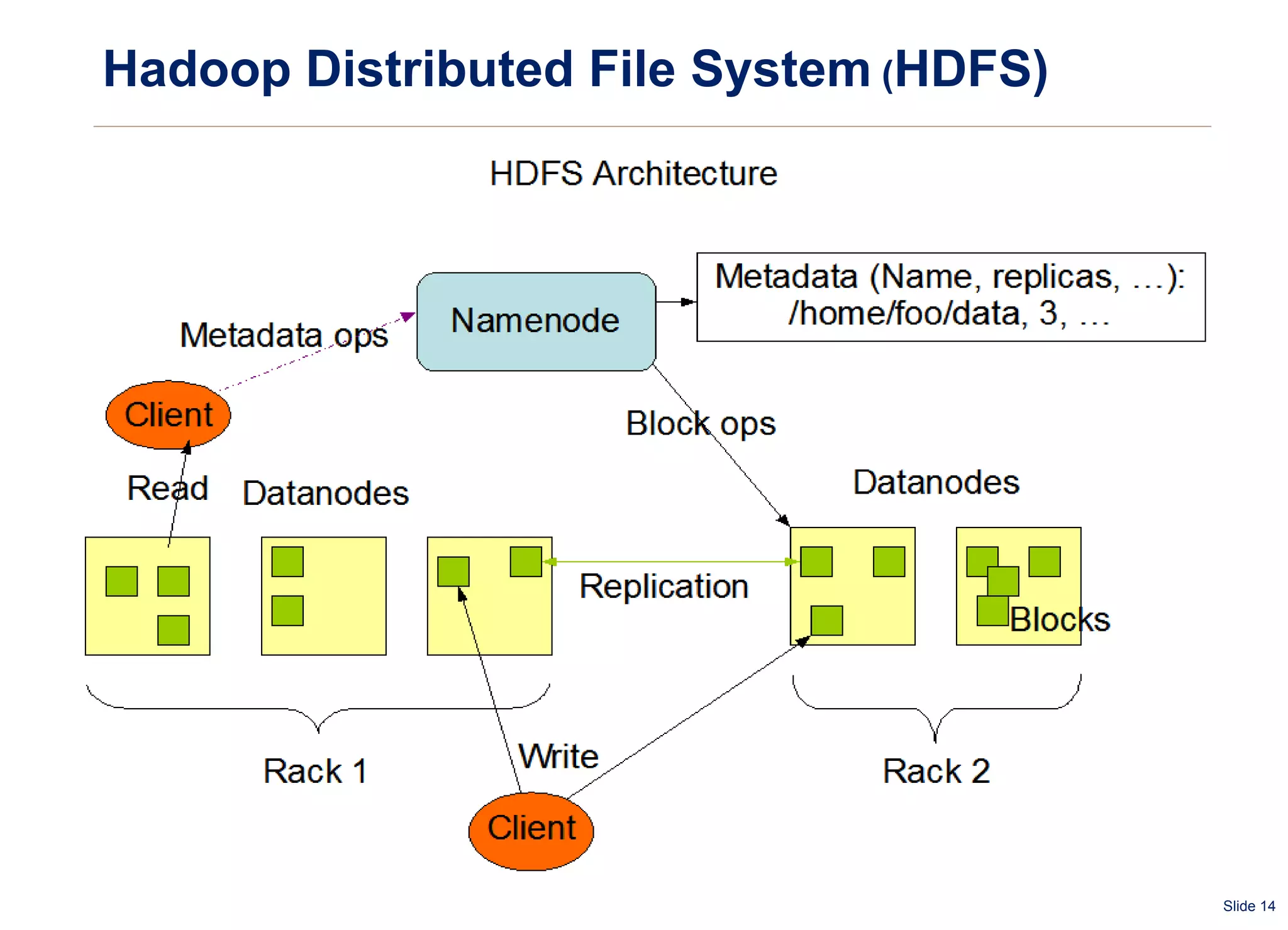


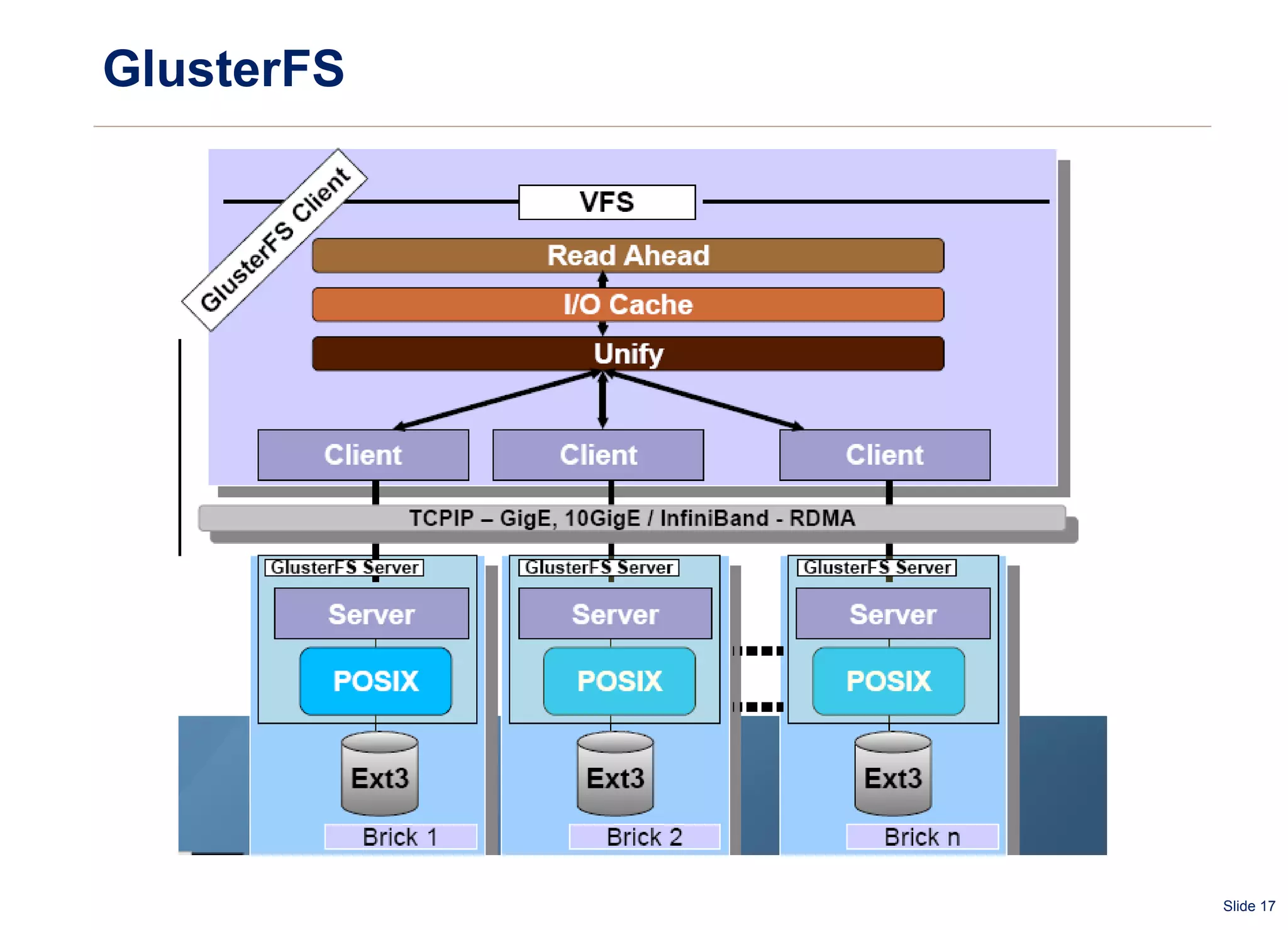
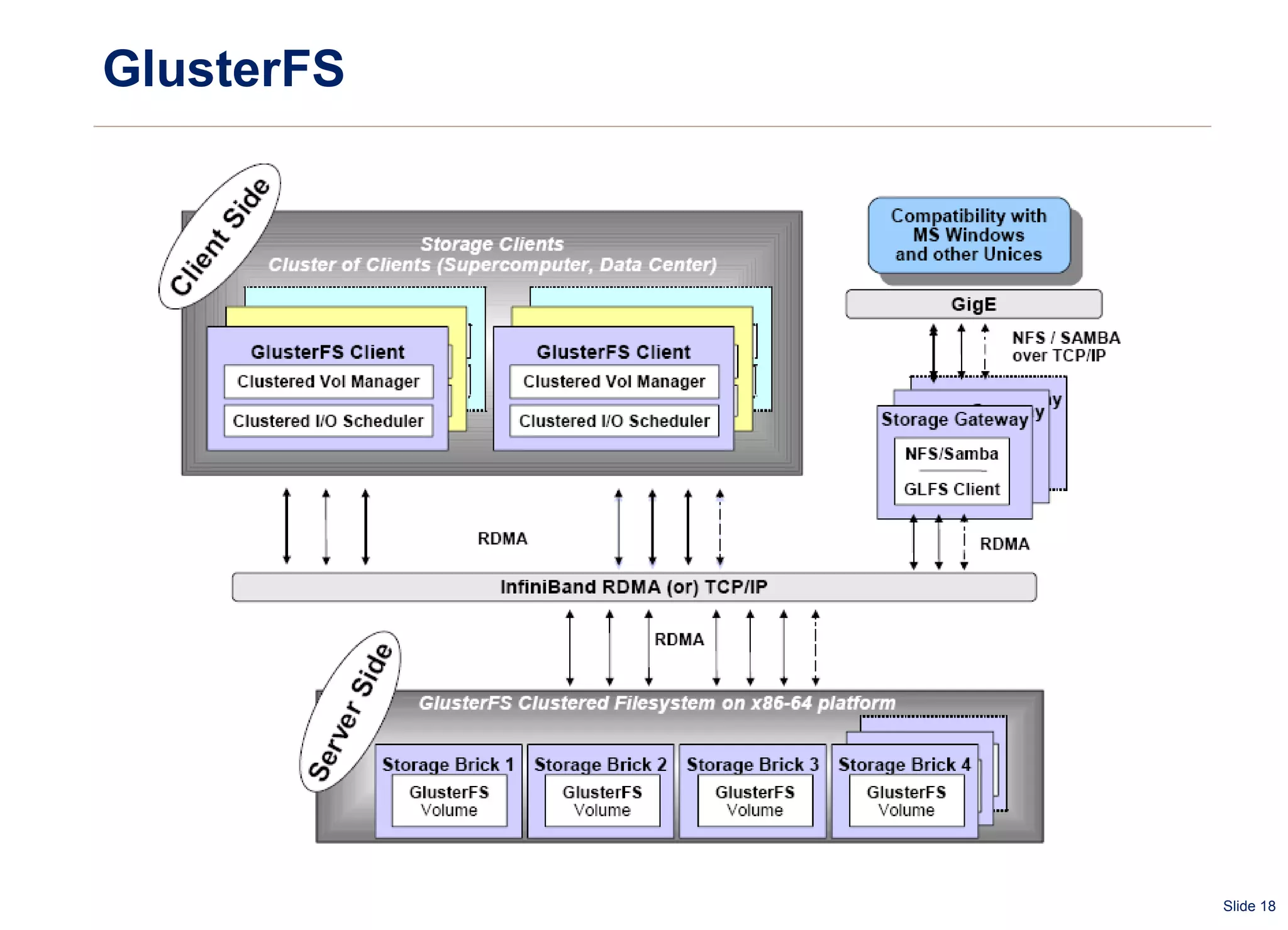
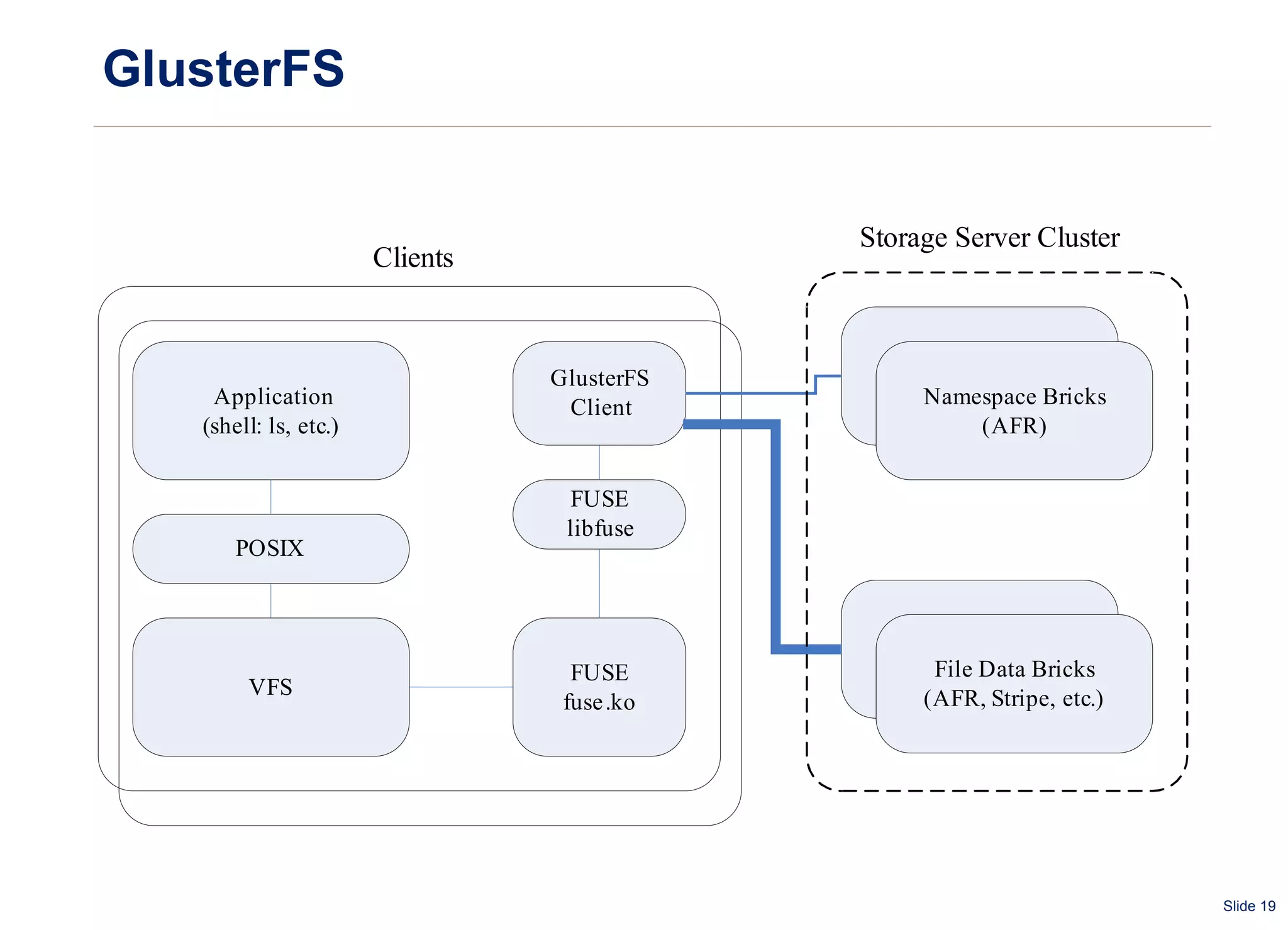



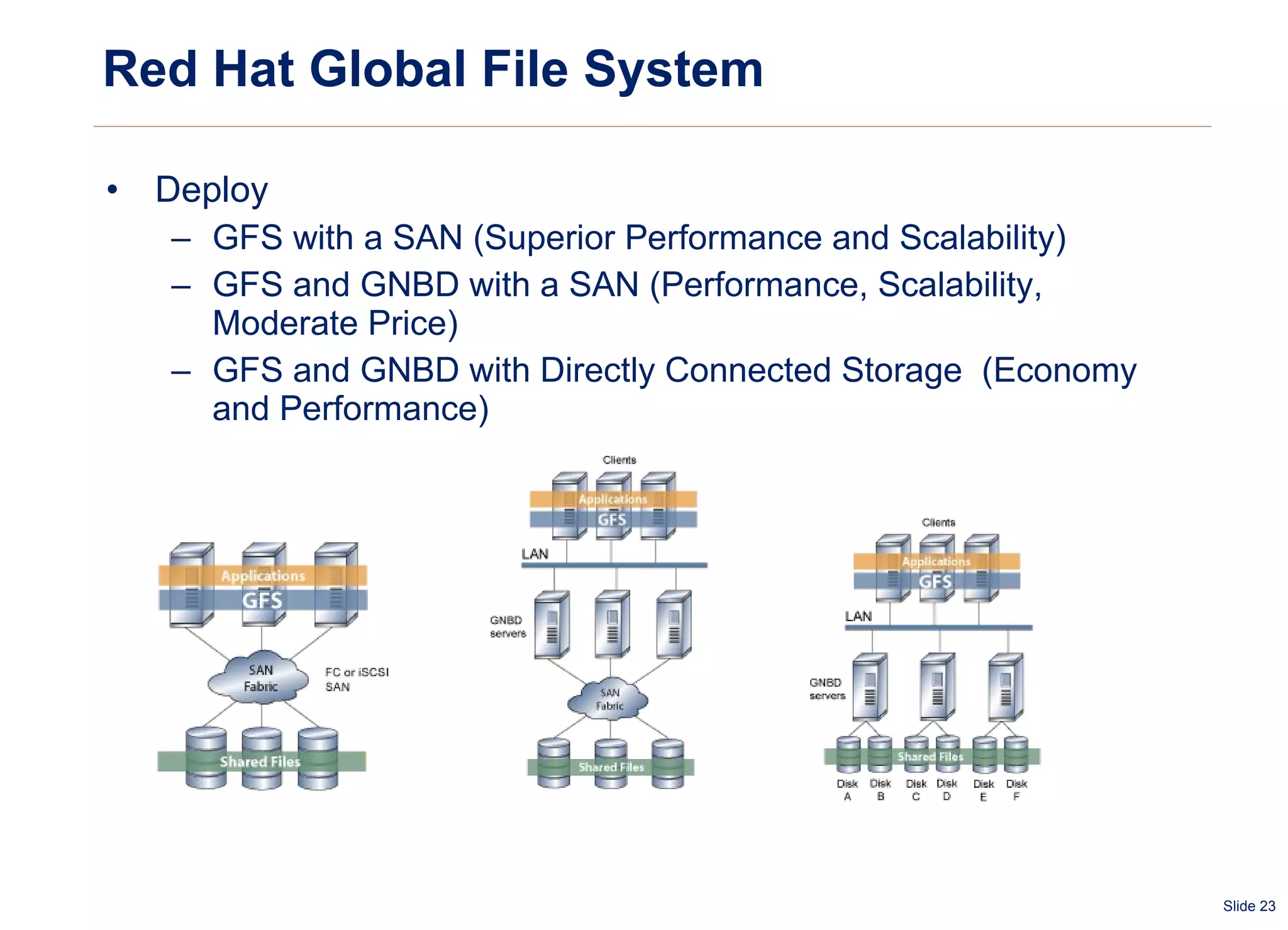



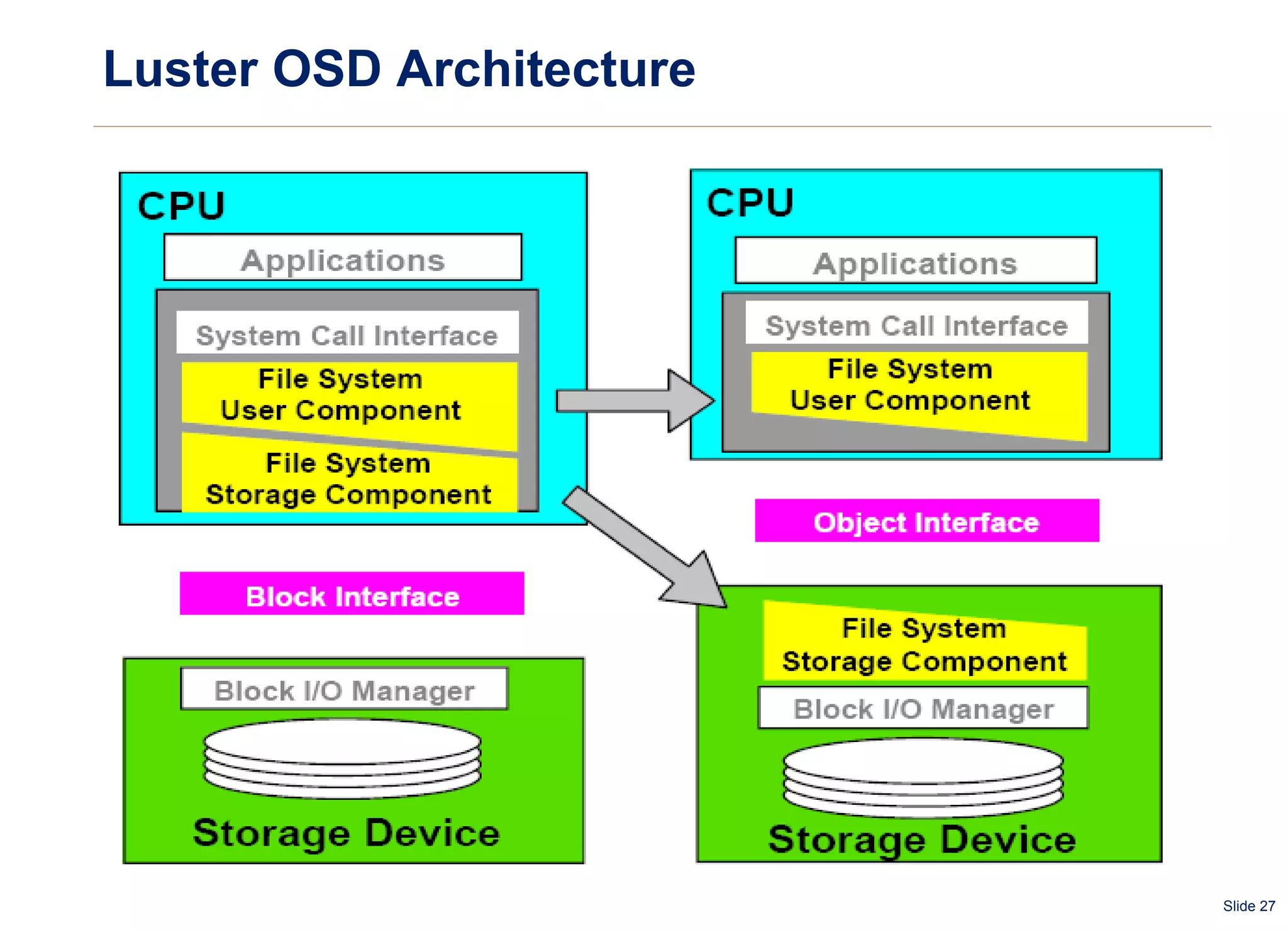



The document summarizes and compares several distributed file systems, including Google File System (GFS), Kosmos File System (KFS), Hadoop Distributed File System (HDFS), GlusterFS, and Red Hat Global File System (GFS). GFS, KFS and HDFS are based on the GFS architecture of a single metadata server and multiple chunkservers. GlusterFS uses a decentralized architecture without a metadata server. Red Hat GFS requires a SAN for high performance and scalability. Each system has advantages and limitations for different use cases.








































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)