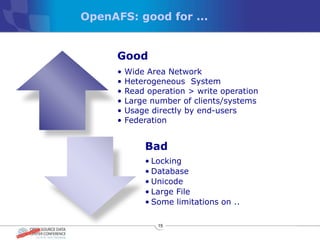
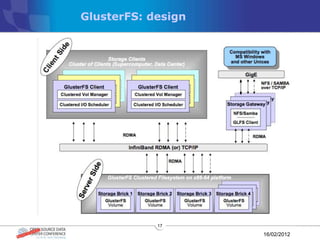
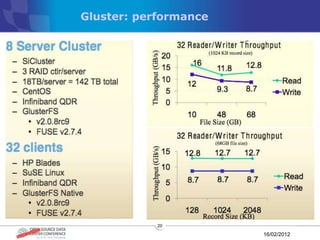
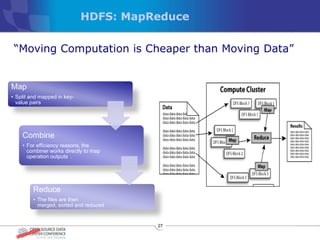
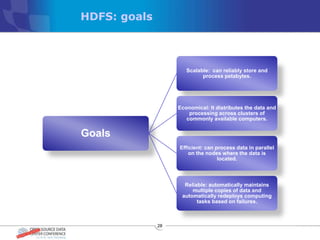
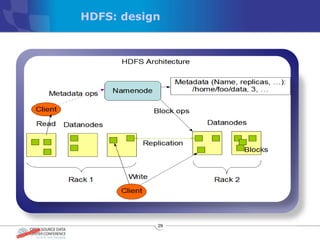
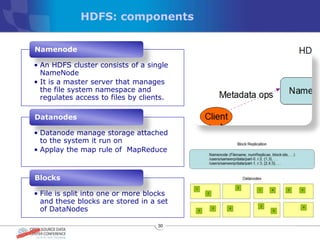
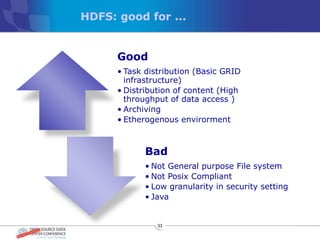
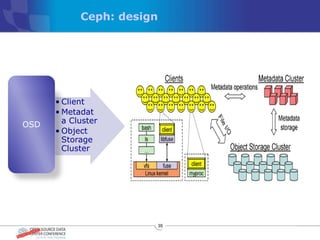
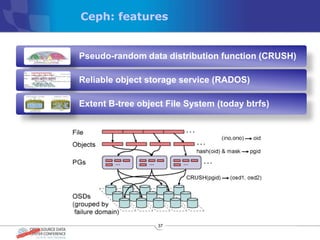
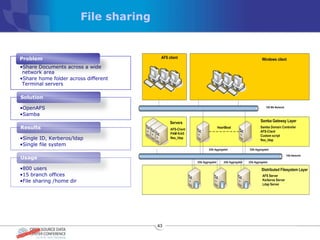
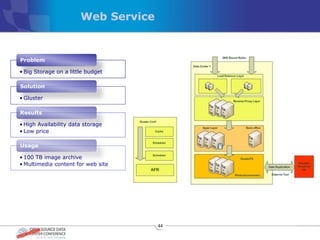
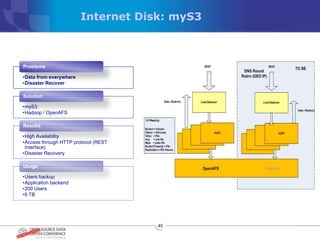
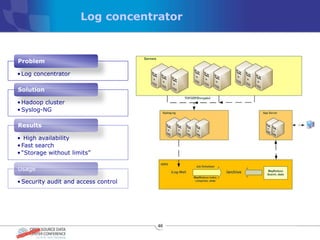
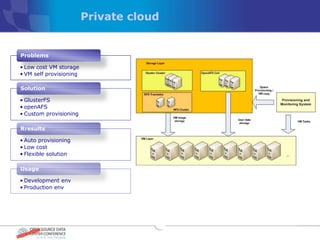
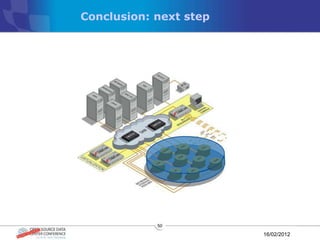
The document discusses various distributed file systems (DFS) such as OpenAFS, GlusterFS, HDFS, and Ceph, detailing their features, use cases, and performance characteristics. It explores the challenges of storage in modern data centers and offers case studies showing implementations of these systems to address specific problems. The conclusion presents insights on factors such as bandwidth, data replication, and requirements for managing large-scale storage systems.