Downloaded 1,673 times









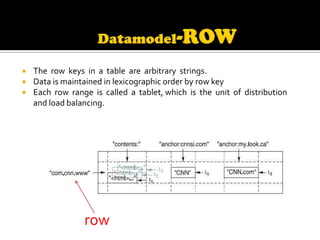
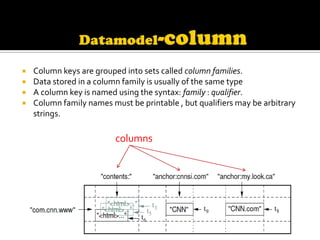
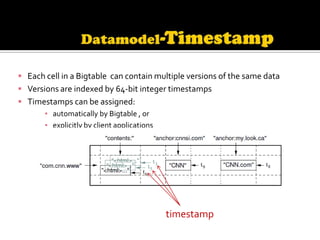

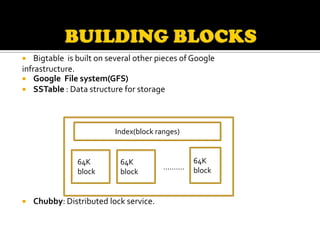






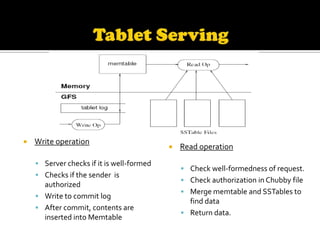



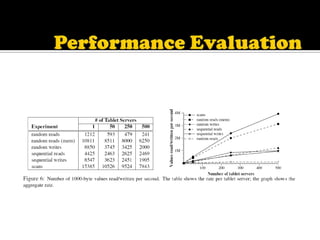
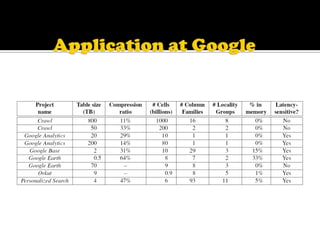





This document describes Bigtable, Google's distributed storage system for managing structured data at large scale. Bigtable stores data in sparse, distributed, sorted maps indexed by row key, column key, and timestamp. It is scalable, self-managing, and used by over 60 Google products and services. Bigtable provides high availability and performance through its use of distributed systems techniques like replication, load balancing, and data locality.



































































