Downloaded 3,415 times
































































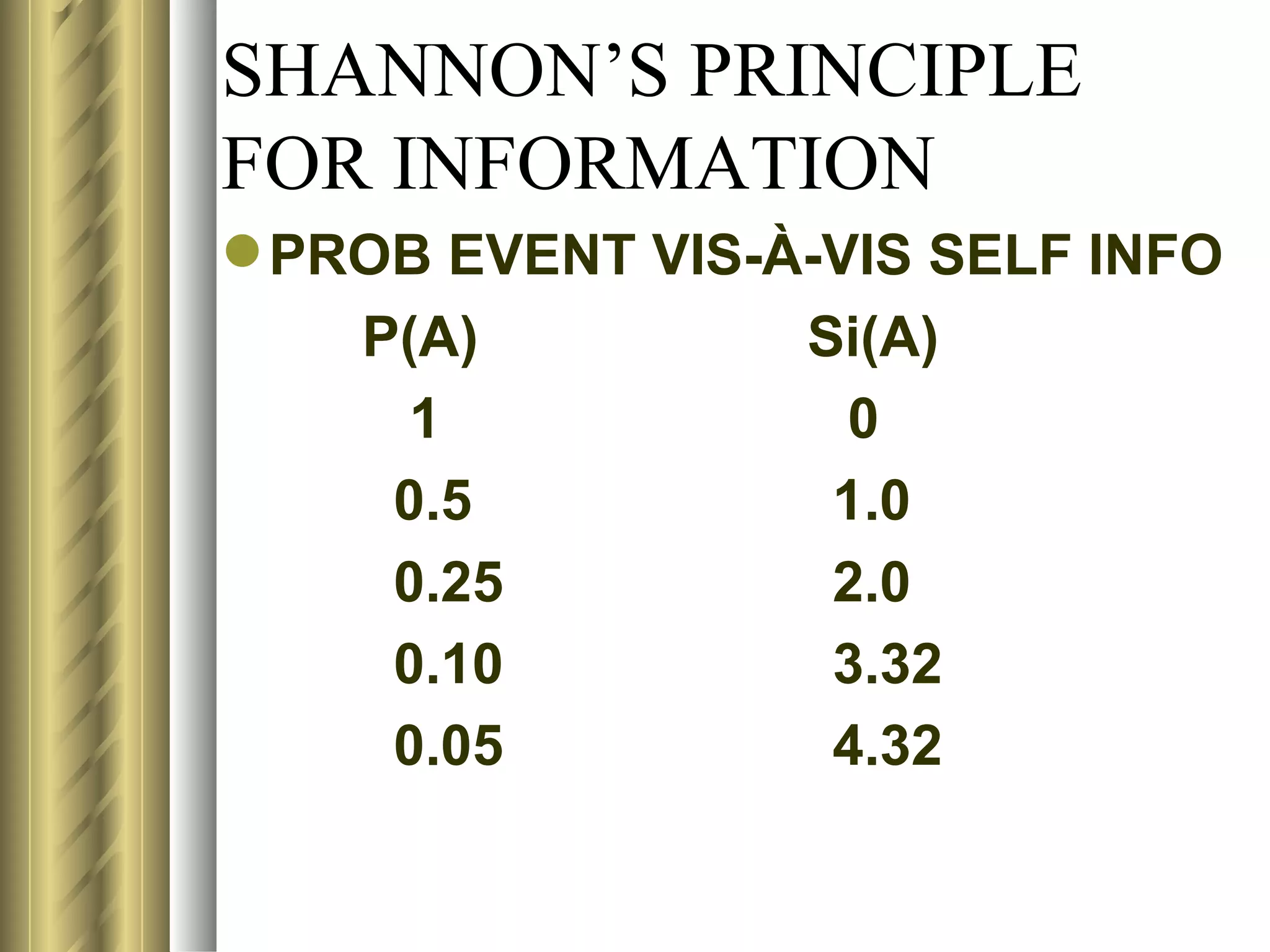
![SHANNON’S PRINCIPLE
FOR INFORMATION
LET P(A) & P(B) BE THE PROB OF
OCCURANCE OF EVENTS A & B
RESPECTIVELY.
ACCORDING TO SHANNON, SELF-INFO
ASSOCIATED WITH EVENT A MAY BE
DEFINED AS
Si(A) = - logmP(A)= logm[1/P(A)]
SIMILARLY, Si(B)= logm[1/P(B)]
WHERE m DEFINES THE UNIT OF INFO](https://image.slidesharecdn.com/compression1-rrt-120502141409-phpapp02/75/Compression-69-2048.jpg)
![SHANNON’S PRINCIPLE
FOR INFORMATION
CONCEPT OF Si MAY ALSO BE USED
TO MAKE INFERENCES BY
ASSOCIATING IT WITH 2 INDEPENDENT
EVENTS
LET A & B BE 2 INDEPENDENT EVENTS,
THEN
P(AB)= P(A)*P(B)
Si(AB)=-log2[P(AB)]
= [-log2P(A)] + [-log2P(B)]
= Si(A) + Si(B)](https://image.slidesharecdn.com/compression1-rrt-120502141409-phpapp02/75/Compression-71-2048.jpg)









![ENTROPY OF INFORMATION
N=15
CHAR NO OF CHARS PROB OF CHAR Si
d 4 4/15 1.90
a 6 6/15 1.32
b 2 2/15 2.90
c 3 3/15 2.32
AV SELF INFO OF MESSAGE= [1/N]*Σ ENTROPY OF ith CHAR
= [1/15]*[E(1) + E(2) + E(3) + ….+ E(15)]
=[1/15]*[E(d)+E(a)+E(d)+E(b)+………+E(c)]
= [1/15] *[1.90+1.32+1.90+2.90+..+2.32] = [1/15]*28.28 = 1.88
ENTROPY OF MESSAGE=-Σ Pi*log2(Pi), i=1 TO 4
= (4/15)*(1/1.90) + (6/15)*(1/1.32) + (2/15)*(1/2.90) + (3/15)(1/2.32)
= 1.88](https://image.slidesharecdn.com/compression1-rrt-120502141409-phpapp02/75/Compression-81-2048.jpg)
















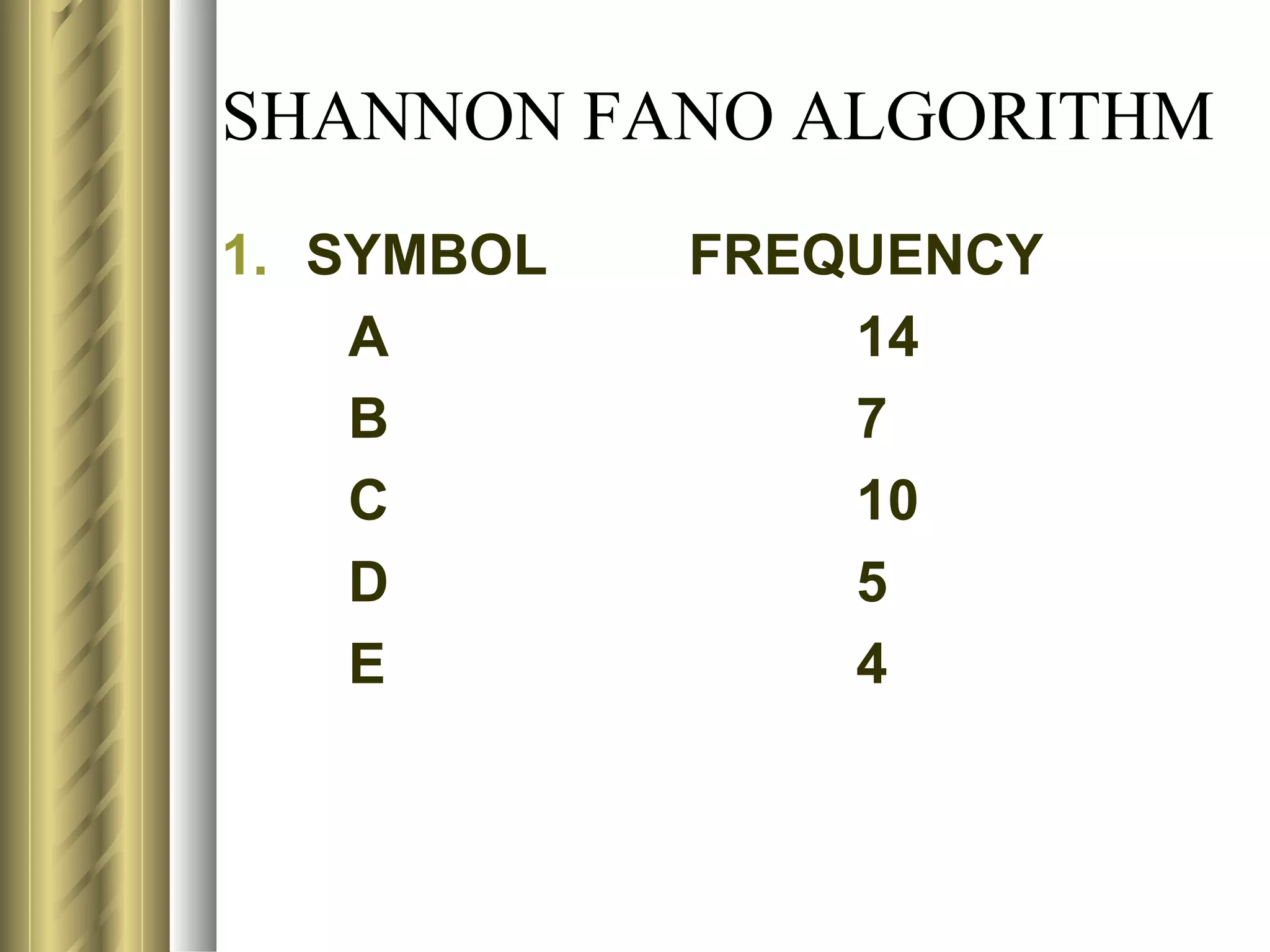
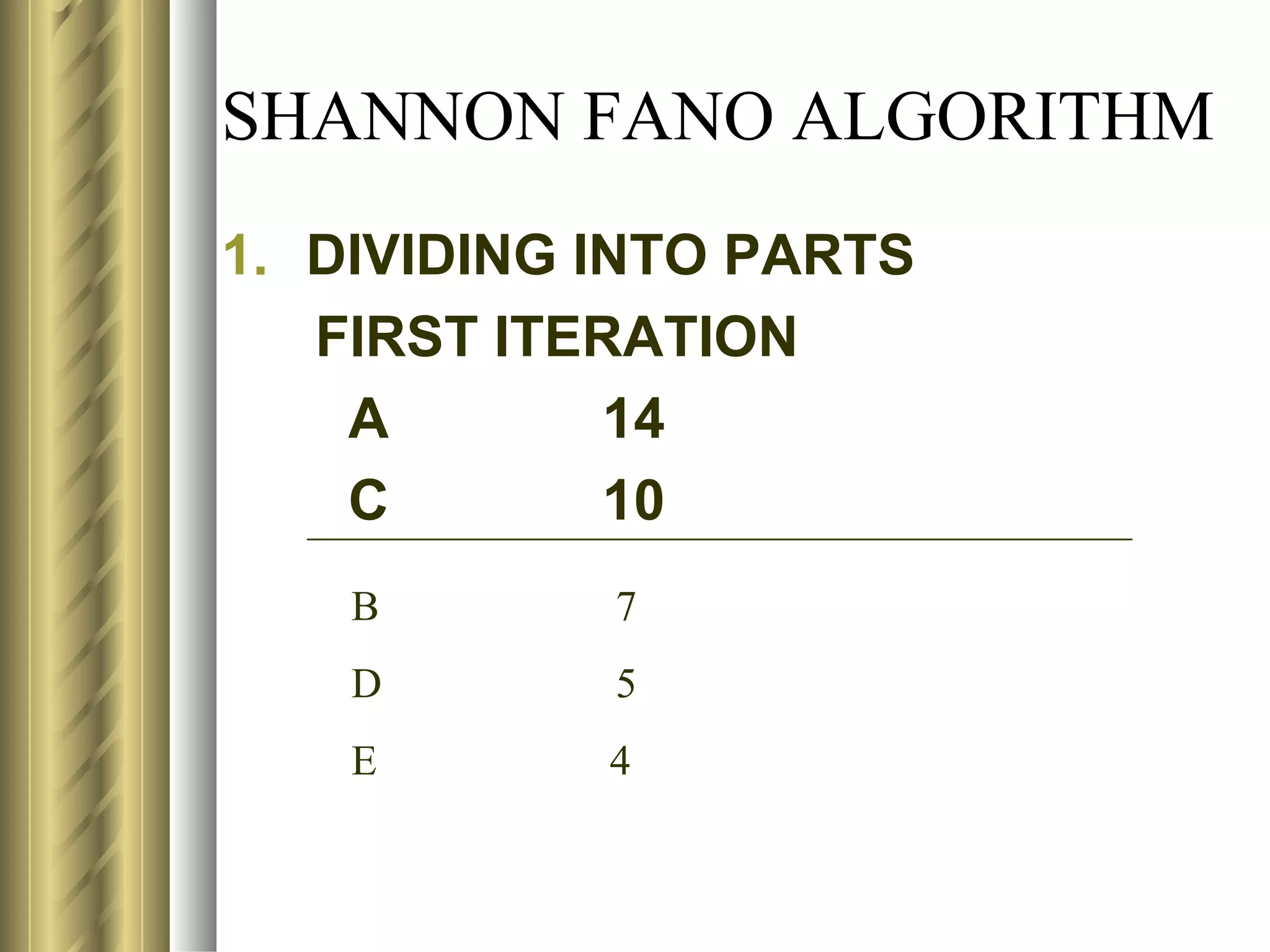
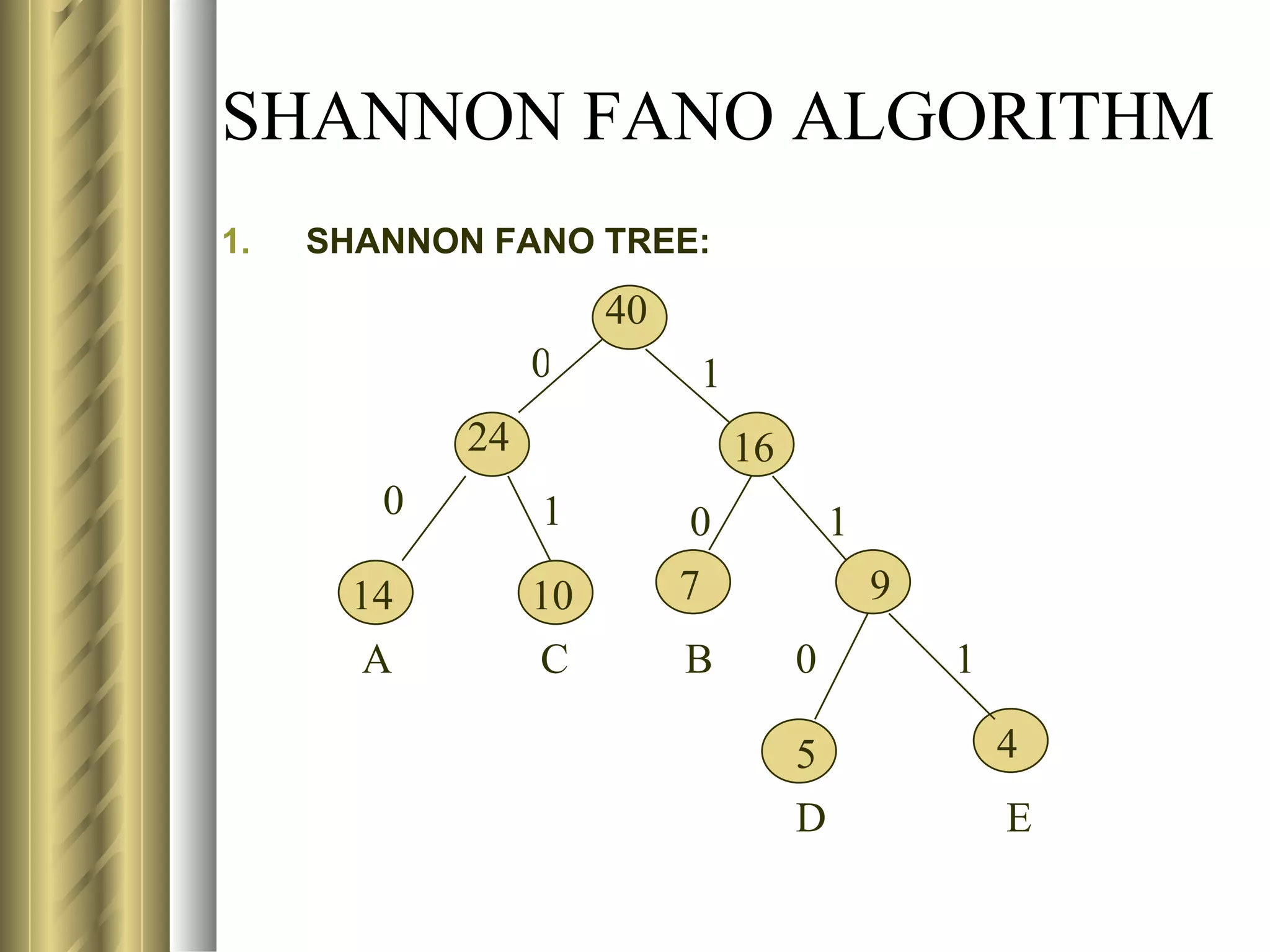
![USE OF ENTROPY IN CODING
M=4; MIN NO OF BITS REQ TO REP A
CHAR=N=log24=2
BY LOOKING INTOTHE TABLE, THE FOLLOWING
CODES CAN BE GENERATED USING DYNAMIC
SCHEME:
CHAR PROB CODE
A 0.70 1
B 0.15 01
C 0.10 001
D 0.05 0001
AV NO OF BITS REQ TO COMM A MESSAGE OF 100
CHARS = [(70*1)+(15*3)+(10*2)+(5*4)]/100
= 150/100 = 1.5](https://image.slidesharecdn.com/compression1-rrt-120502141409-phpapp02/75/Compression-98-2048.jpg)





















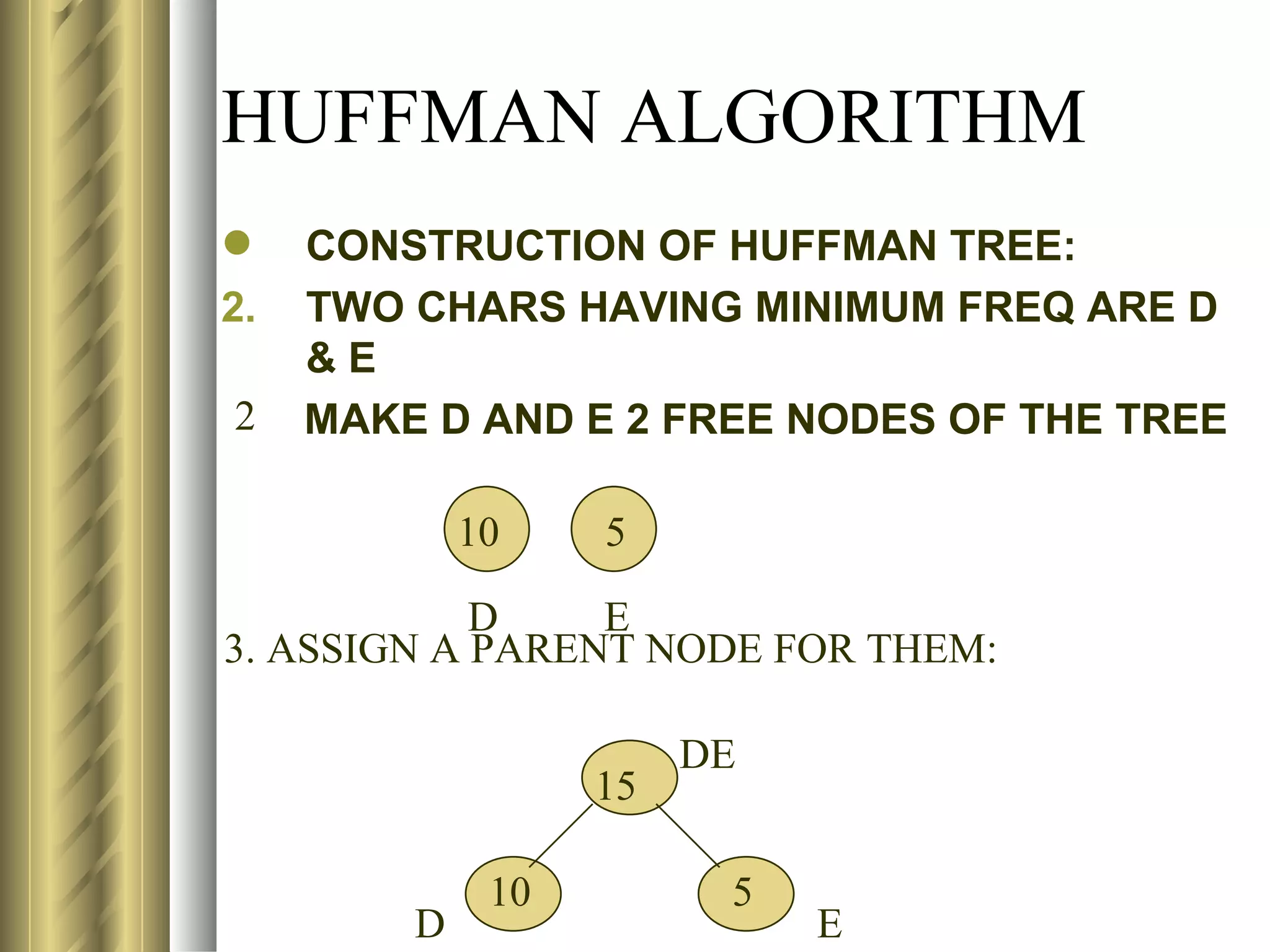

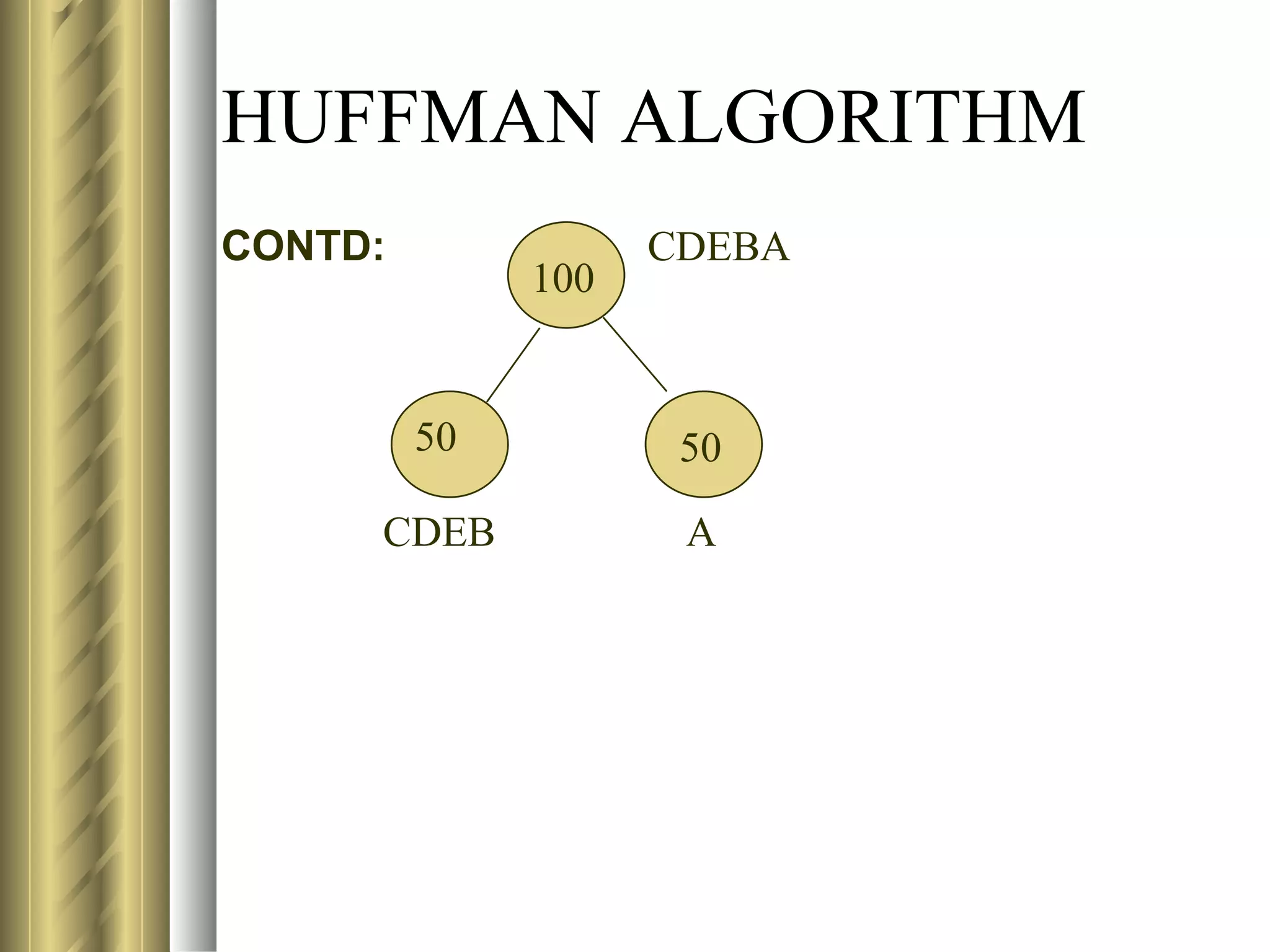
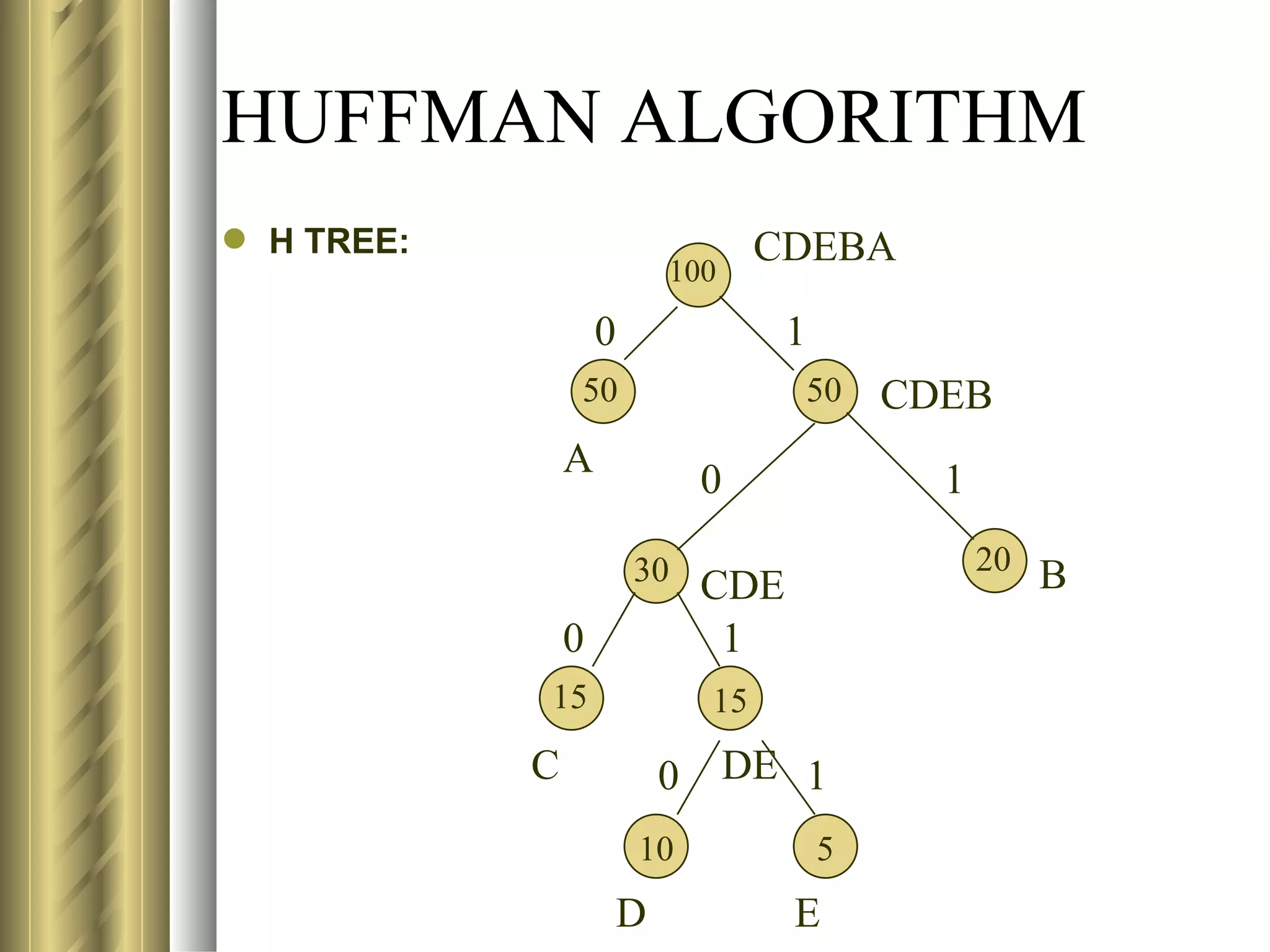


































![LZ78 (LEMPEL-ZIV) ENCODING ALGORITHM
LZ78:
2. START WITH AN EMPTY DICTIONARY WITH AN EMPTY PREFIX P.
3. C= NEXT CHAR IN THE CHARSTREAM
4. IS THE STRING (P+C) PRESENT IN THE DICTIONARY?
IF YES, THEN P= P+C
IF NOT, THEN
OUTPUT THESE 2 OBJECTS, P & C, TO THE
CODESTREAM, [THE CODEWORD
CORRESPONDING TO P AND C IN THE SAME
FORM AS INPUT FROM CHARSTREAM]
ADD THE STRING P+C TO THE DICTIONARY
P= EMPTY
ARE THERE MORE CHARS IN THE CHARSTREAM?
IF YES, RETURN TO STEP 2
IF NOT
IF P IS NOT EMPTY, OUTPUT THE CODE WORD
CORREPONDING TO P
END](https://image.slidesharecdn.com/compression1-rrt-120502141409-phpapp02/75/Compression-161-2048.jpg)





















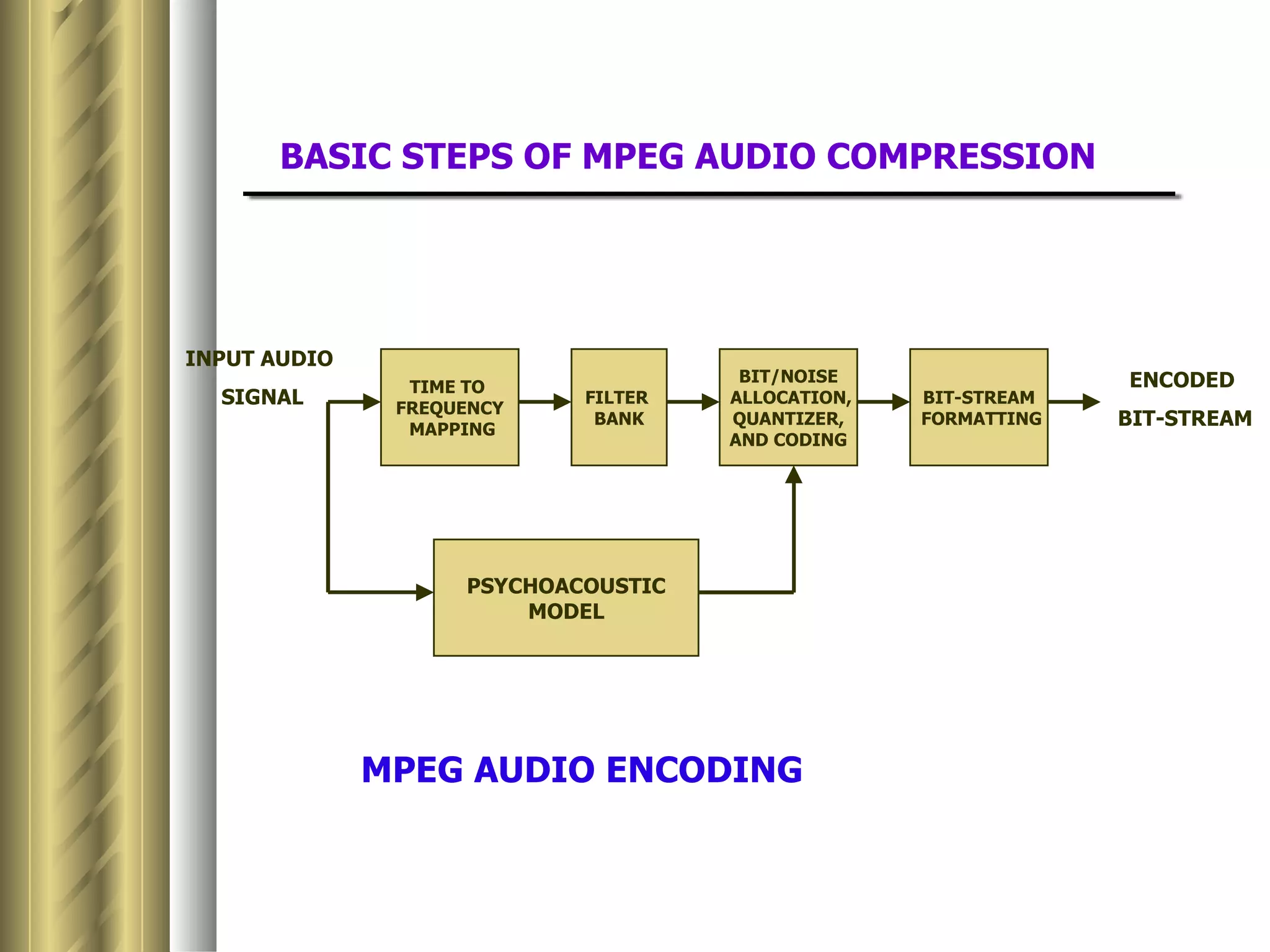
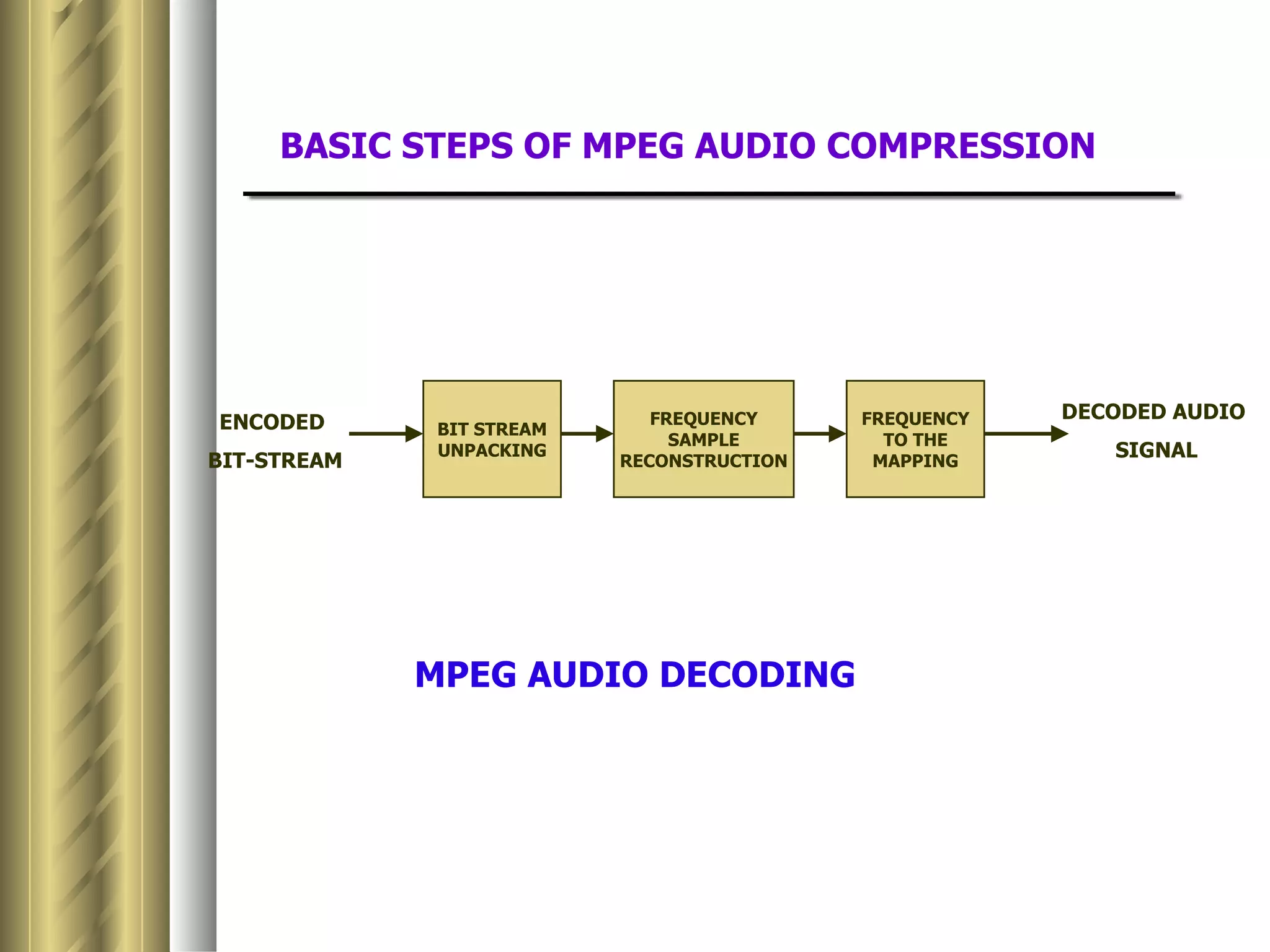
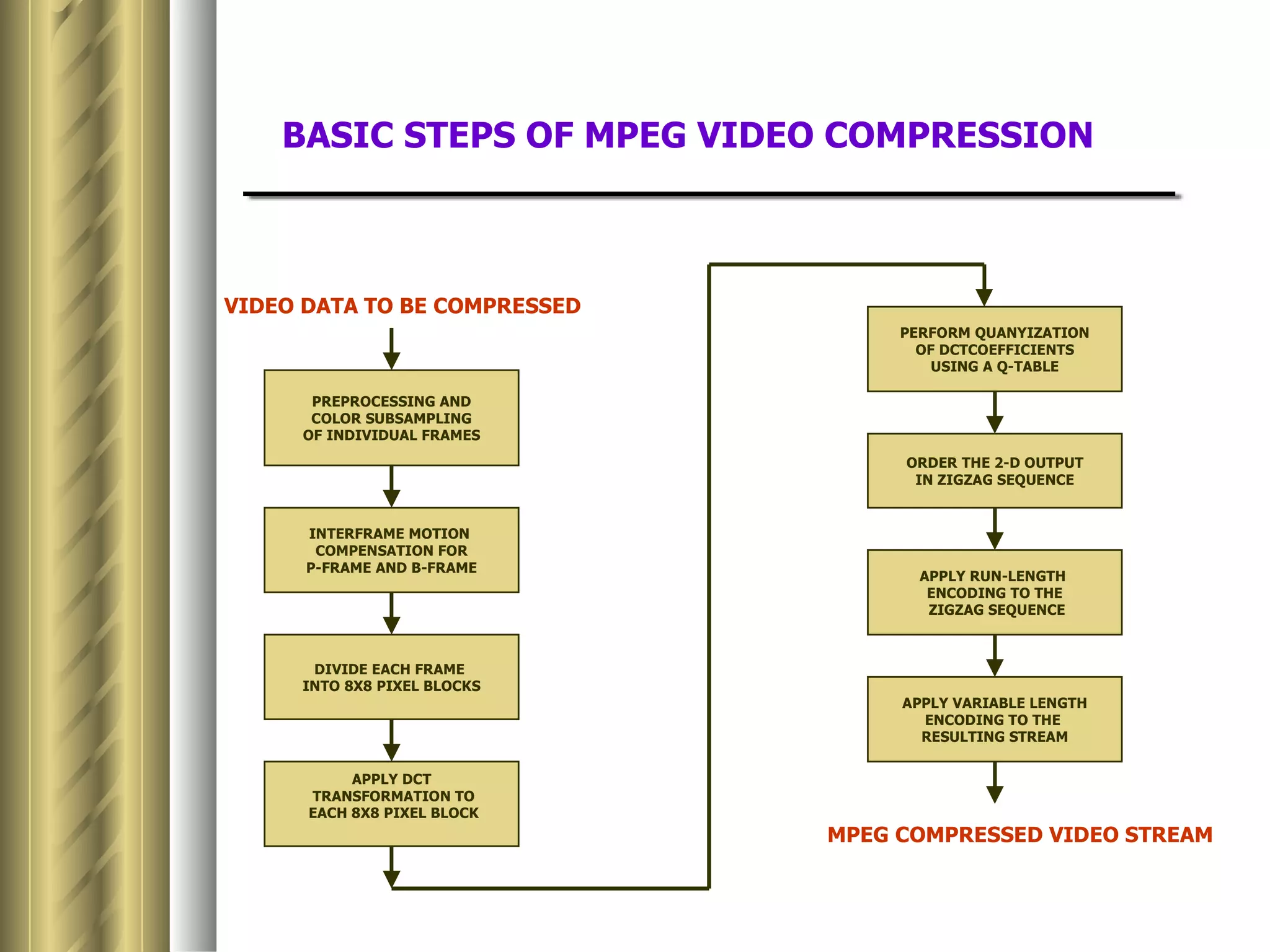
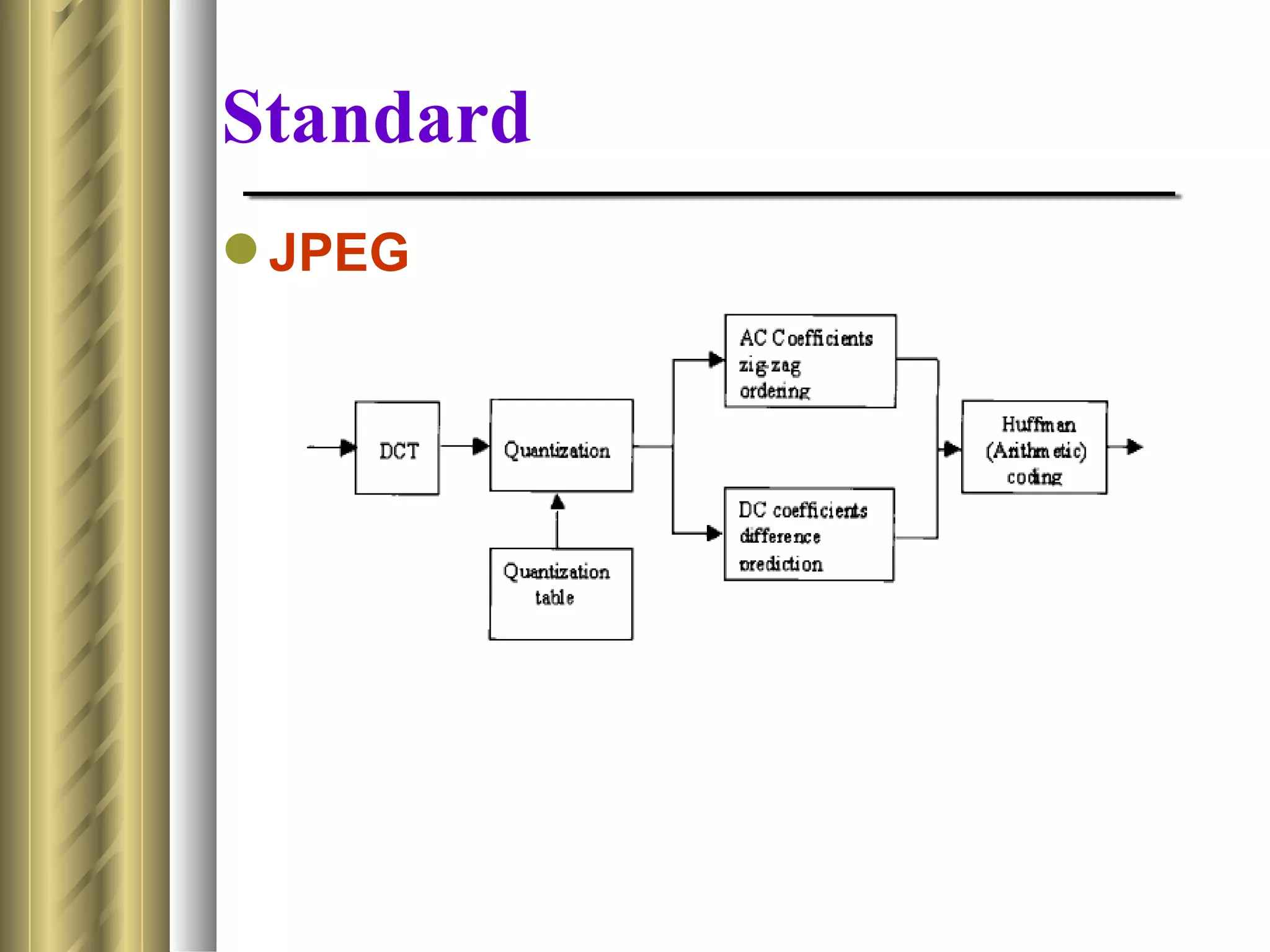
This document discusses various topics related to data compression including compression techniques, audio compression, video compression, and standards like MPEG and JPEG. It covers lossless versus lossy compression, explaining that lossy compression can achieve much higher levels of compression but results in some loss of quality, while lossless compression maintains the original quality. The advantages of data compression include reducing file sizes, saving storage space and bandwidth.








































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














