Downloaded 436 times















![Tahoe-LAFS setup
➢ mkdir /storage/tahoe
➢ cd /storage/tahoe && tahoe create-introducer .
➢ tahoe start .
➢ cat /storage/tahoe/private/introducer.furl
➢ mkdir /storage/tahoe-storage
➢ cd /storage/tahoe-storage && tahoe create-node .
➢ Add the introducer.furl to tahoe.cfg
➢ Add [sftpd] section to tahoe.cfg](https://image.slidesharecdn.com/marian-marinov-131030074727-phpapp02/85/Performance-comparison-of-Distributed-File-Systems-on-1Gbit-networks-16-320.jpg)


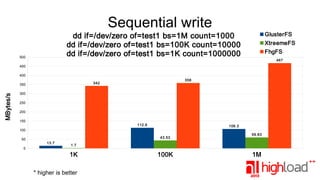
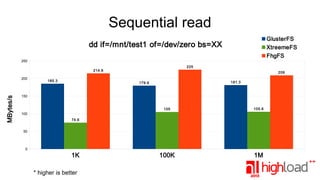
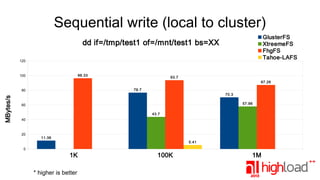
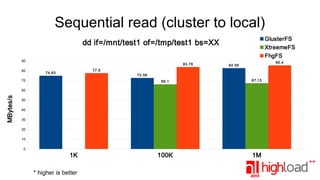
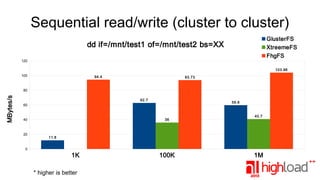
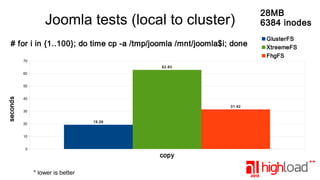
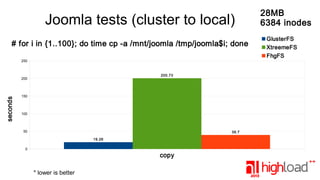
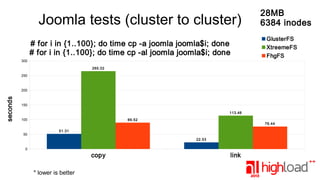



The document presents a performance comparison of distributed file systems including GlusterFS, XtreemFS, FHGFS, Tahoe-LAFS, and PlasmaFS. It evaluates factors such as installation ease, read/write speeds, and file operations across various setups and configurations. The results indicate that FHGFS is optimal for large file storage, while GlusterFS serves as a general-purpose distributed file system.




































![[RakutenTechConf2014] [D-4] The next step of LeoFS and Introducing NewDB Project](https://cdn.slidesharecdn.com/ss_thumbnails/d4rakutentech2014-leofs-newdb-141105023531-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)












































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)












