KFS aka Kosmos FS is a distributed file system written in C++ that is modeled after HDFS. It was originally developed by Kosmix, which was later acquired by Walmart. Some key points:
- KFS uses a master/chunkserver architecture where the metadata is stored on a master node and file data is stored in chunks on chunkservers.
- It supports features like replication, data integrity checks, and rebalancing of chunks.
- While still in early stages, it provides alternatives to the Hadoop ecosystem through its C++ implementation and bindings for other languages like Java and Python.
- The documentation provides instructions for building, deploying, and accessing KFS, though some functionality





![What were we talking about ?
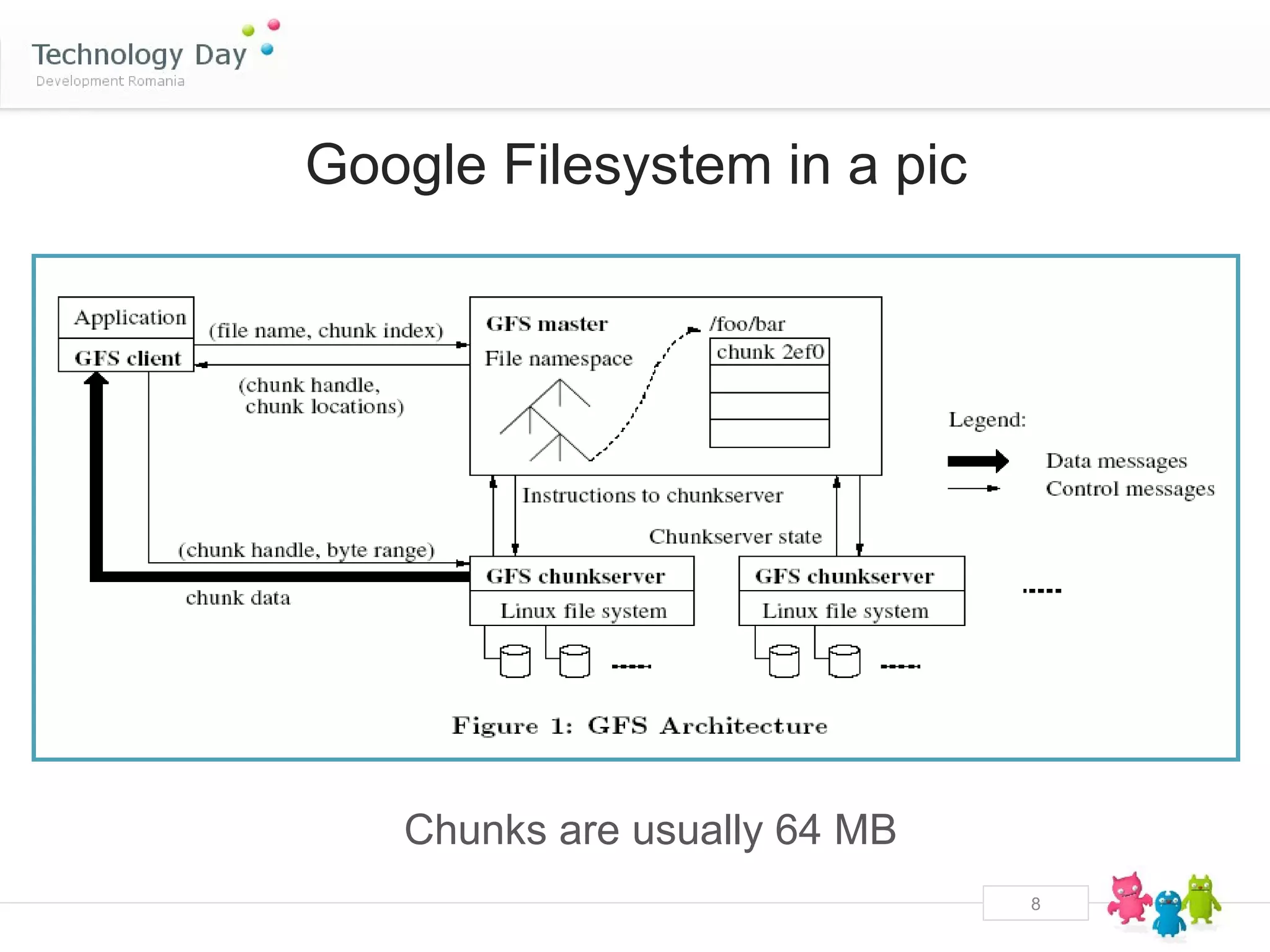
• Modelled after GFS
KFS
• MetaServer, ChunkServer, client library
• ChunkServer stores chunks as files
• To protect agains corruptions, checksums are used on each 64KB block and saved in the
chunk metadata
• On reads, checksum verification is done using the saved data
• Each chunk file is named: [file-id].[chunk-id].version
• Each chunk has a 16K header that contains the chunk checksum information, updated during
writes
The ChunkServer is only aware of its own chunks.
Upon restart, the metaserver validates the blocks and notifies the chunkserver of any stale
blocks (not ownred by any file in the system) resulting in the deletion of those chunks
10](https://image.slidesharecdn.com/kfspresentation-111214103253-phpapp02/75/Kfs-presentation-10-2048.jpg)



![Example config file
[metaserver]
node: machine1
clusterkey: kfs-test-cluster
rundir: /mnt/kfs/meta
baseport: 20000
loglevel: INFO
numservers: 2
[chunkserver_defaults]
rundir: /mnt/kfs/chunk
chunkDir: /mnt/kfs/chunk/bin/kfschunk
baseport: 30000
space: 3400 G
loglevel: INFO
18](https://image.slidesharecdn.com/kfspresentation-111214103253-phpapp02/75/Kfs-presentation-18-2048.jpg)





















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













