Download to read offline















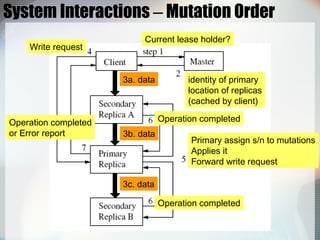
















The Google File System (GFS) is a scalable distributed file system designed by Google to provide reliable, scalable storage and high performance for large datasets and workloads. It uses low-cost commodity hardware and is optimized for large files, streaming reads and writes, and high throughput. The key aspects of GFS include using a single master node to manage metadata, chunking files into 64MB chunks distributed across multiple chunk servers, replicating chunks for reliability, and optimizing for large sequential reads and appends. GFS provides high availability, fault tolerance, and data integrity through replication, fast recovery, and checksum verification.



































































