Download as PDF, PPTX



![Motivation
long-standing challenge of reinforcement learning (RL)
– control with high-dimensional sensory inputs (e.g., vision, speech)
– shift away from reliance on hand-crafted features
utilize breakthroughs in deep learning for RL [M+
13, M+
15]
– extract high-level features from raw sensory data
– learn better representations than handcrafted features with neural
network architectures used in supervised and unsupervised learning
create fast learning algorithm
– train efficiently with stochastic gradient descent (SGD)
– distribute training process to accelerate learning [DCM+
12]
Introduction 3/39](https://image.slidesharecdn.com/dist-deep-qlearn-slides-151023232840-lva1-app6891/85/Distributed-Deep-Q-Learning-3-320.jpg)




![State-action value function
basic idea behind RL is to estimate
Q (s, a) = max
π
E [Rt | st = s, at = a, π] ,
where π maps states to actions (or distributions over actions)
optimal value function obeys Bellman equation
Q (s, a) = E
s ∼E
r + γ max
a
Q (s , a ) | s, a ,
where E is the MDP environment
Reinforcement learning 9/39](https://image.slidesharecdn.com/dist-deep-qlearn-slides-151023232840-lva1-app6891/85/Distributed-Deep-Q-Learning-9-320.jpg)

![Q-network
trained by minimizing a sequence of loss functions
Li (θi) = E
s,a∼ρ(·)
(yi − Q (s, a; θi))
2
,
with
– iteration number i
– target yi = Es ∼E [r + γ maxa Q (s , a ; θi−1) | s, a]
– “behavior distribution” (exploration policy) ρ (s, a)
architecture varies according to application
Reinforcement learning 11/39](https://image.slidesharecdn.com/dist-deep-qlearn-slides-151023232840-lva1-app6891/85/Distributed-Deep-Q-Learning-11-320.jpg)


















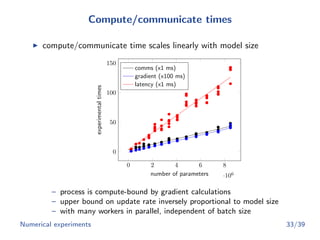
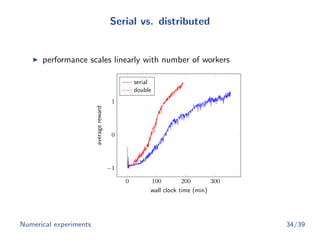


![Summary
deep Q-learning [M+
13, M+
15] scales well via DistBelief [DCM+
12]
asynchronous model updates accelerate training despite lower
update quality (vs. serial)
Conclusion 37/39](https://image.slidesharecdn.com/dist-deep-qlearn-slides-151023232840-lva1-app6891/85/Distributed-Deep-Q-Learning-37-320.jpg)



The document discusses a distributed deep Q-learning algorithm developed to enhance reinforcement learning efficiency by utilizing neural networks for high-dimensional sensory inputs. It outlines serial and distributed algorithms, highlights the importance of experience replay for stability, and presents numerical experiments demonstrating the method's effectiveness. The implementation enables significant scaling through data parallelism, resulting in faster training and improved performance in various gaming environments.






















































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)