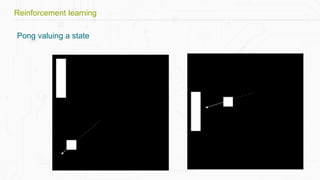
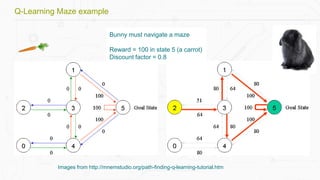
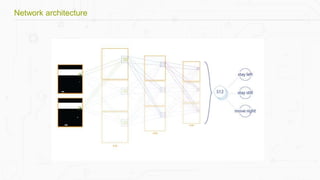
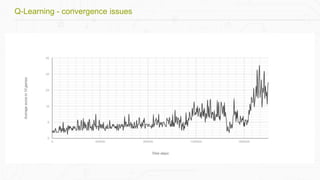
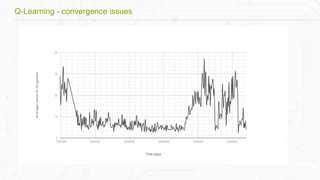
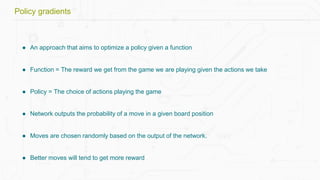
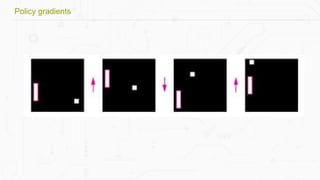
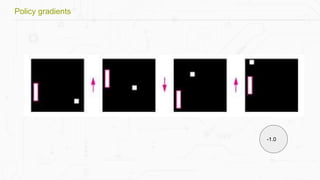
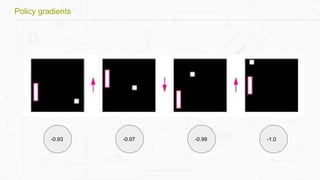
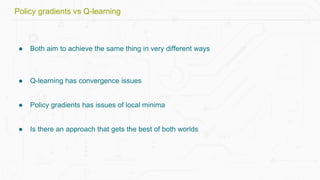
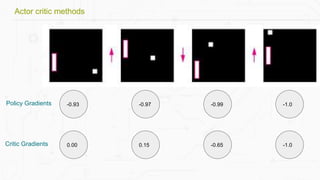
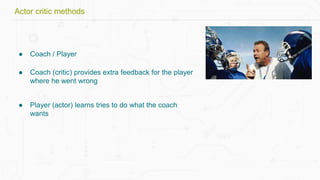
This document discusses building a deep learning AI project focused on reinforcement learning and how to apply it to games, using examples like Pong and Space Invaders. It outlines key concepts such as value learning, policy learning, and model-based learning, along with various techniques including Q-learning and actor-critic methods. The document also provides links to relevant tools and resources for implementing these AI techniques in gaming environments.



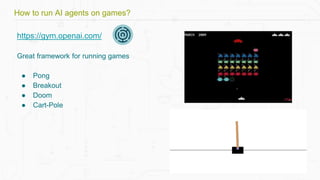
![https://gym.openai.com/
Example:
Pip install -e '.[atari]'
import gym
env = gym.make('SpaceInvaders-v0')
obs = env.reset()
env.render()
ob, reward, done, _ = env.step(action)
How to run AI agents on games?](https://image.slidesharecdn.com/buildingadeeplearningai-170614091256/85/Building-a-deep-learning-ai-pptx-5-320.jpg)