Downloaded 22 times








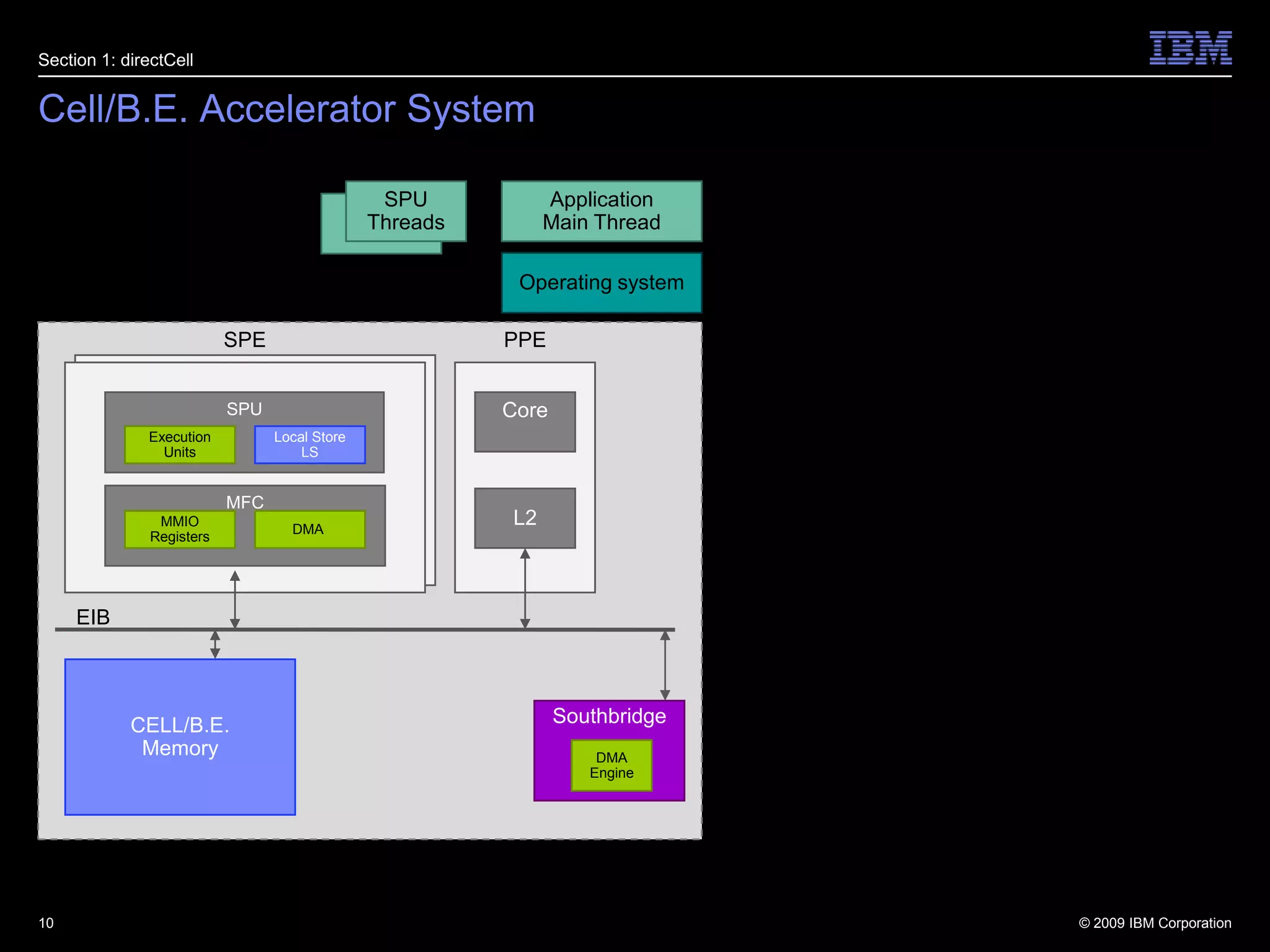
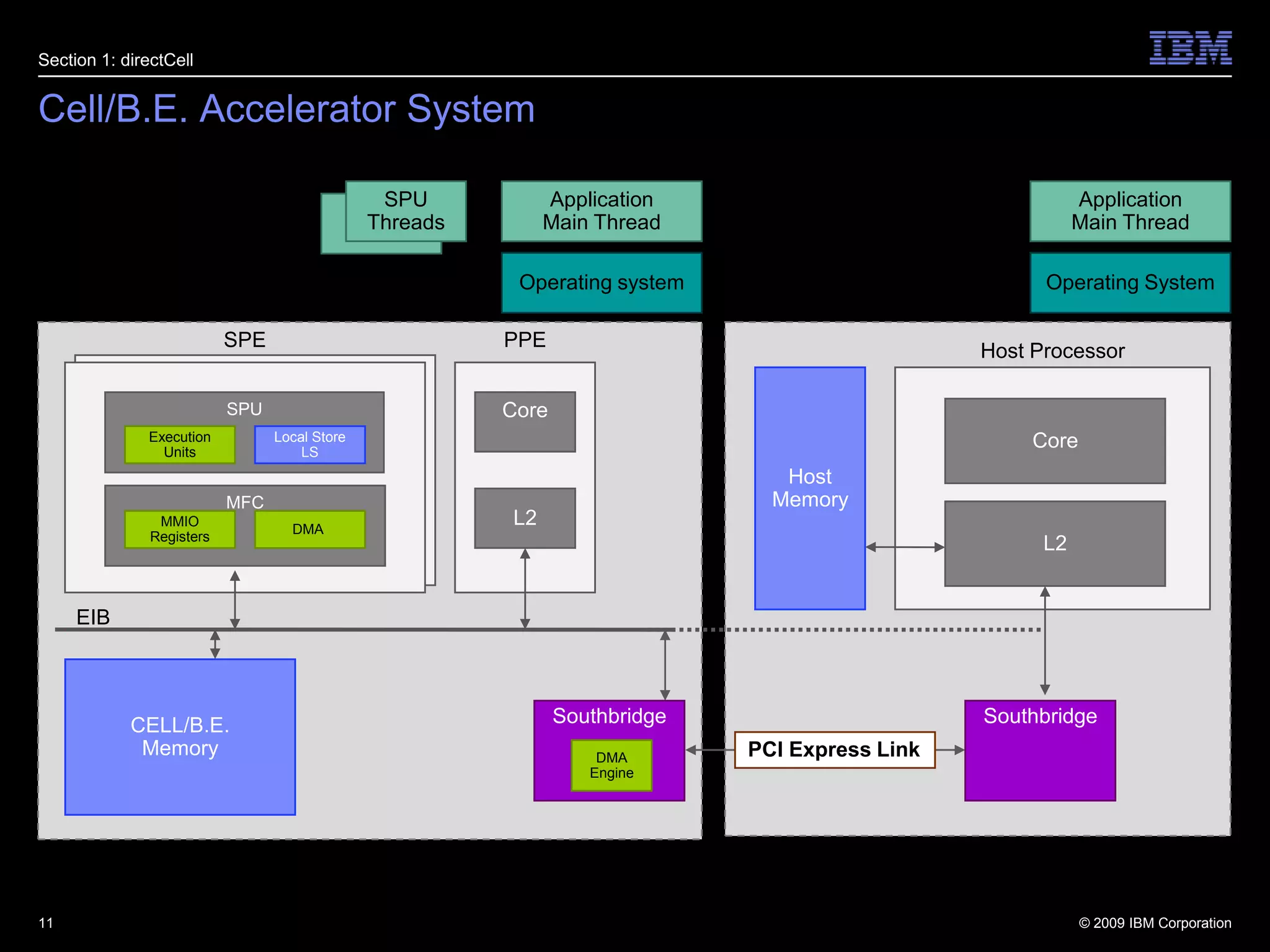

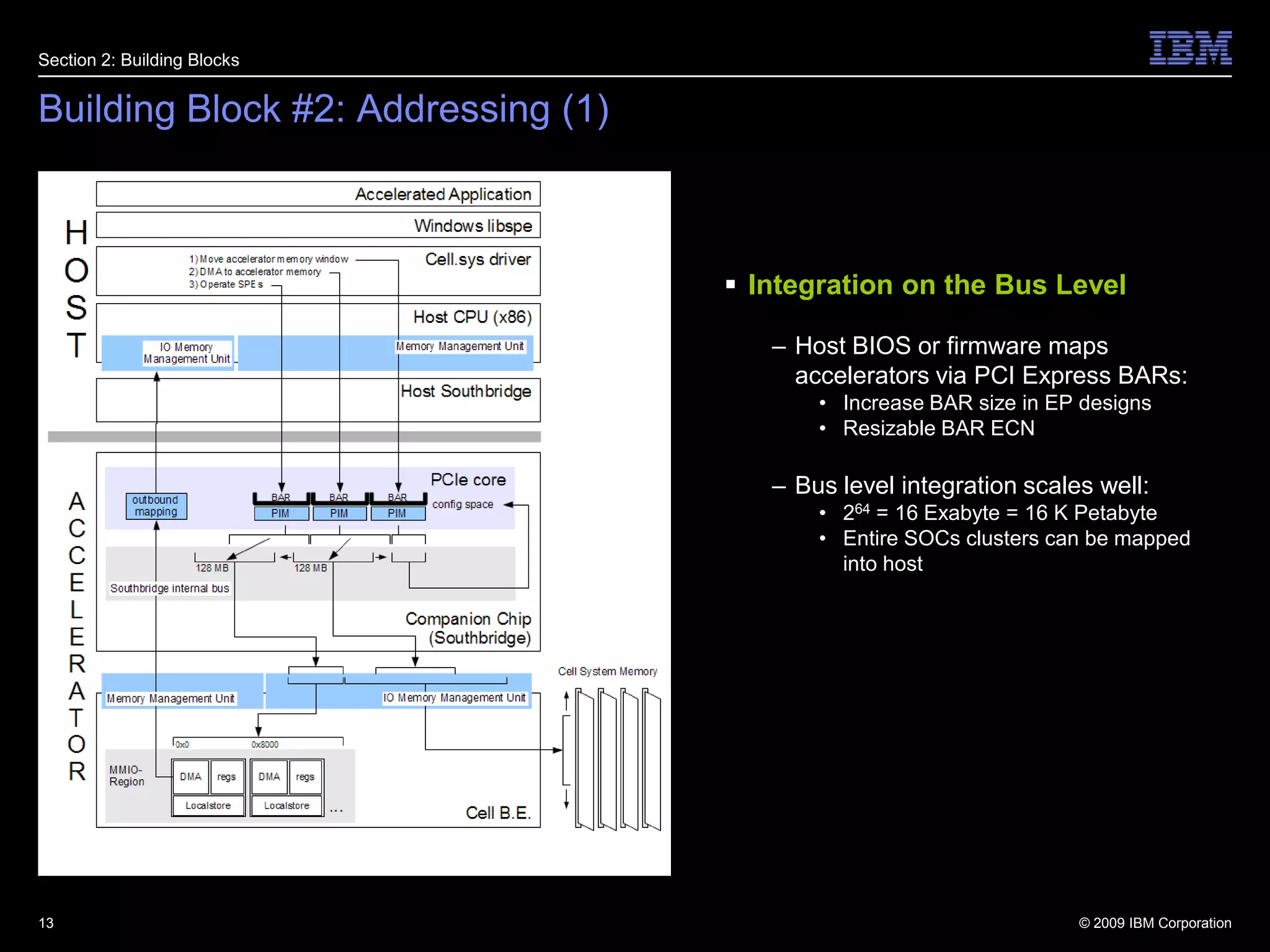
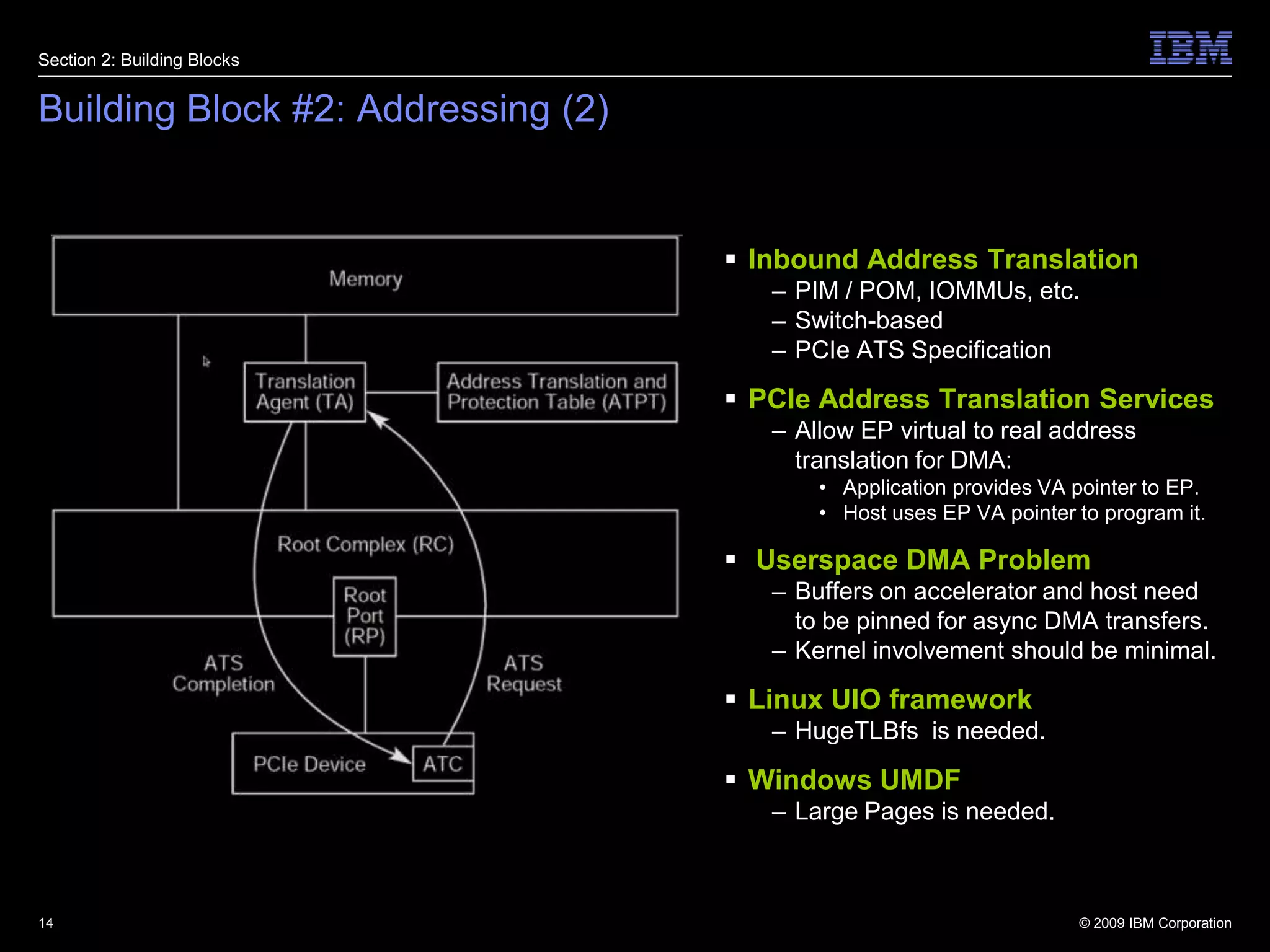

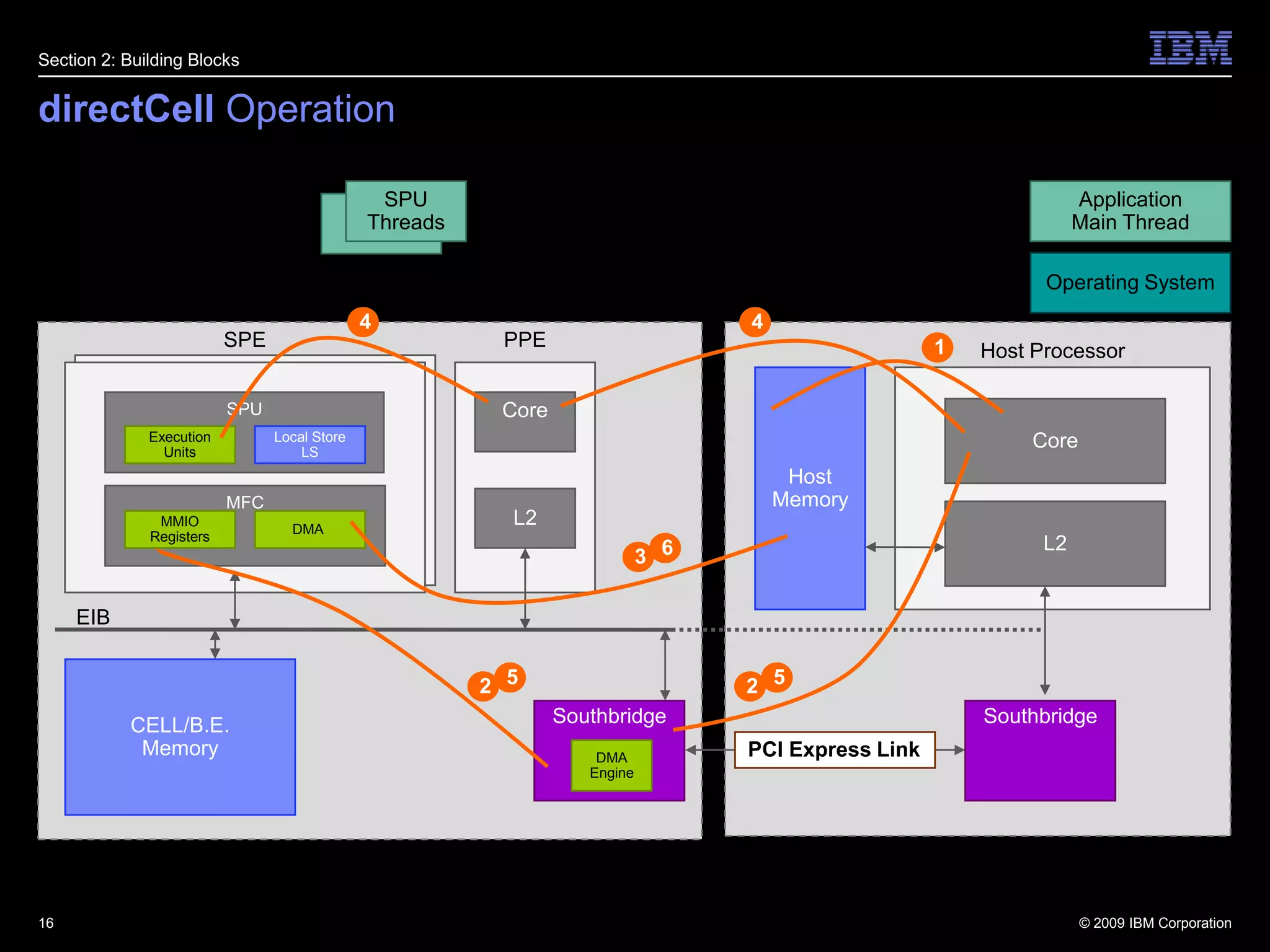


















This document summarizes new features in PCI Express Gen 3, including Atomic Operations, TLP Processing Hints, TLP Prefix, Resizable BAR, and others. It describes how each feature enhances PCI Express functionality, such as enabling atomic operations to facilitate migration of SMP applications to PCIe accelerators, and TLP Prefix allowing expansion of header sizes to carry additional information.


















































































