Downloaded 96 times





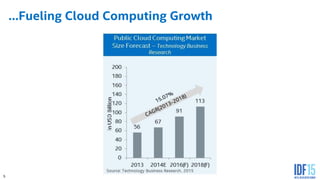
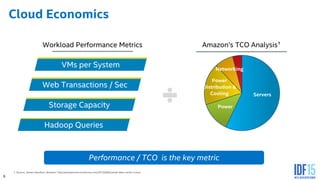


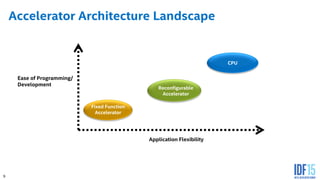




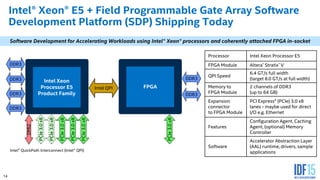
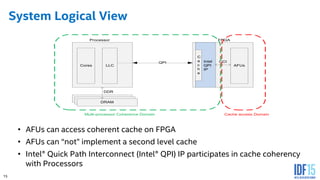
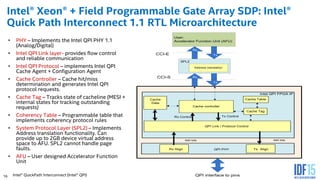

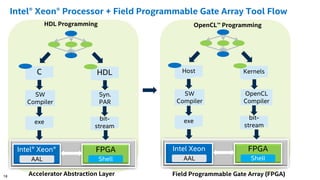
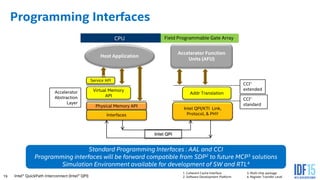
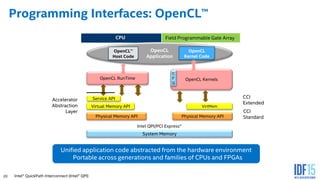

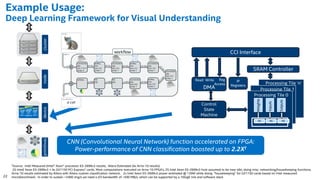
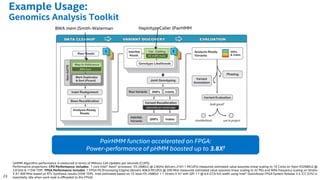
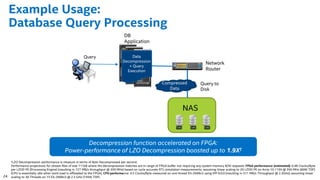

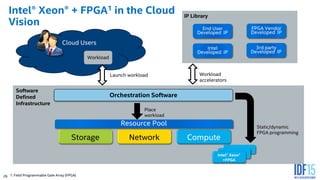




The document discusses the use of Field Programmable Gate Arrays (FPGAs) as performance accelerators in cloud computing and data center environments, highlighting their advantages such as reconfigurability and low development costs. It outlines the Intel Xeon processor and FPGA platform, including programming interfaces and example applications for deep learning and genomics analysis. The document emphasizes Intel's initiatives to support accelerator research and development while providing information on performance metrics and the potential for cost savings.





























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








