Downloaded 10 times





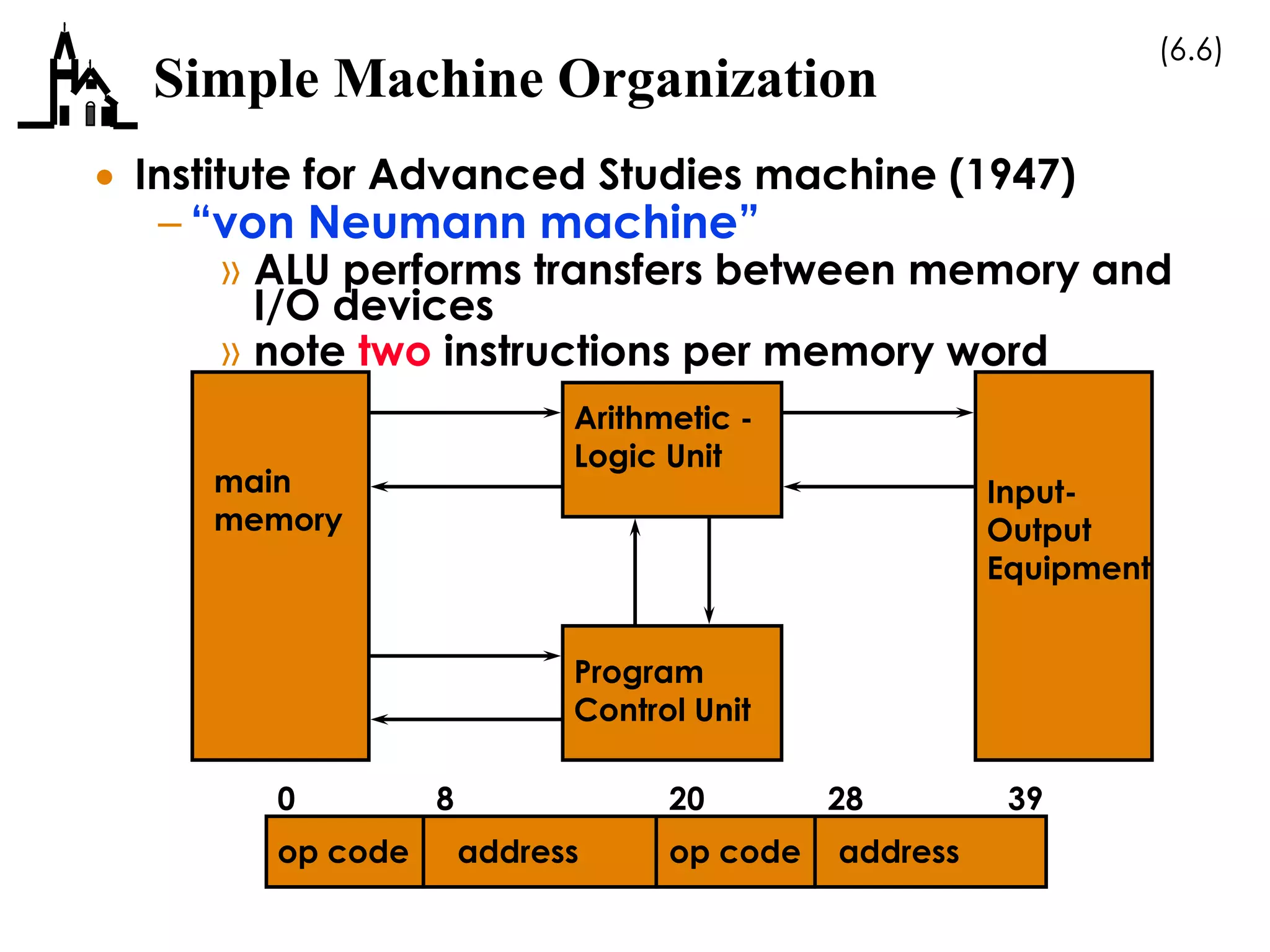
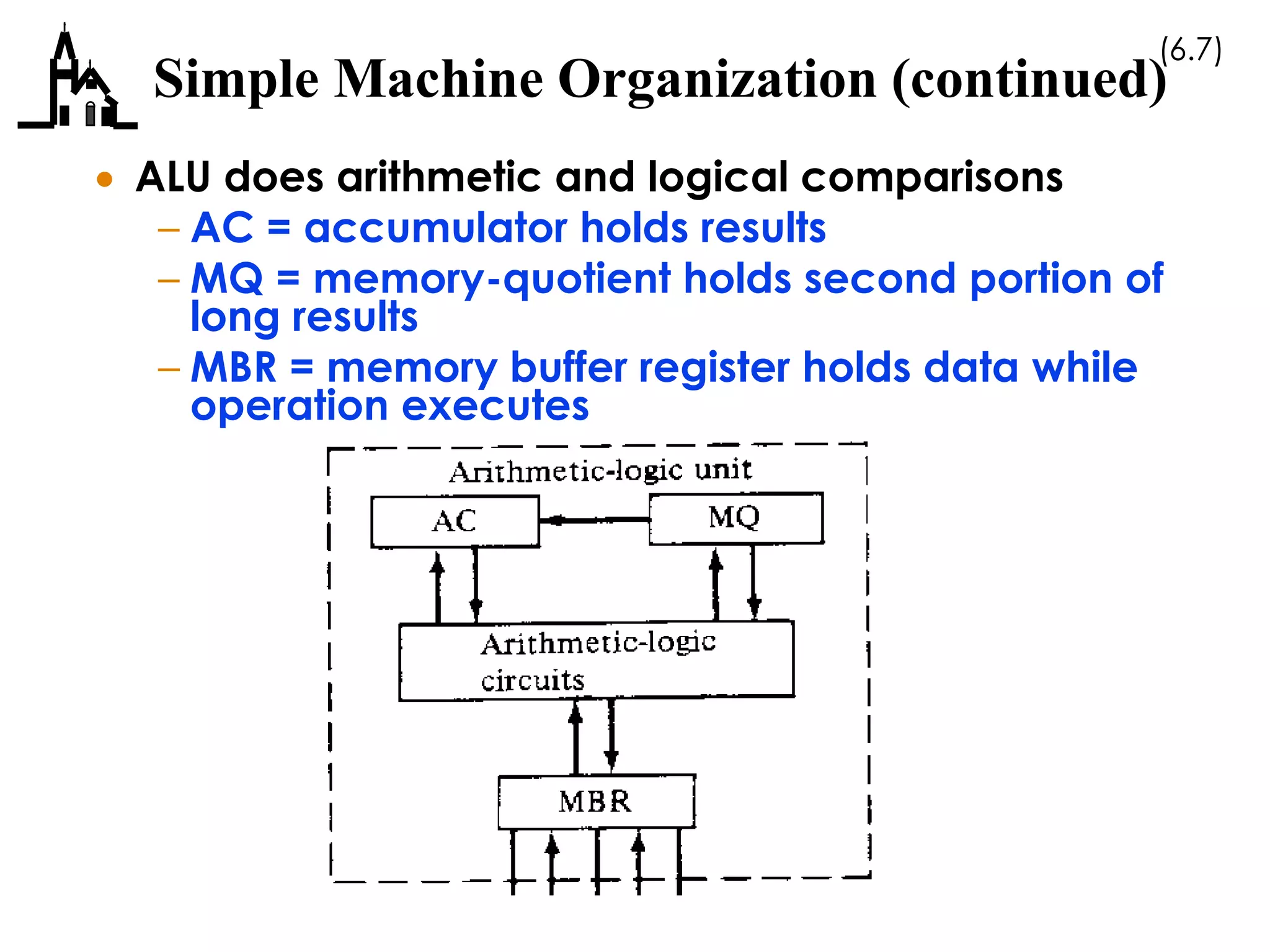
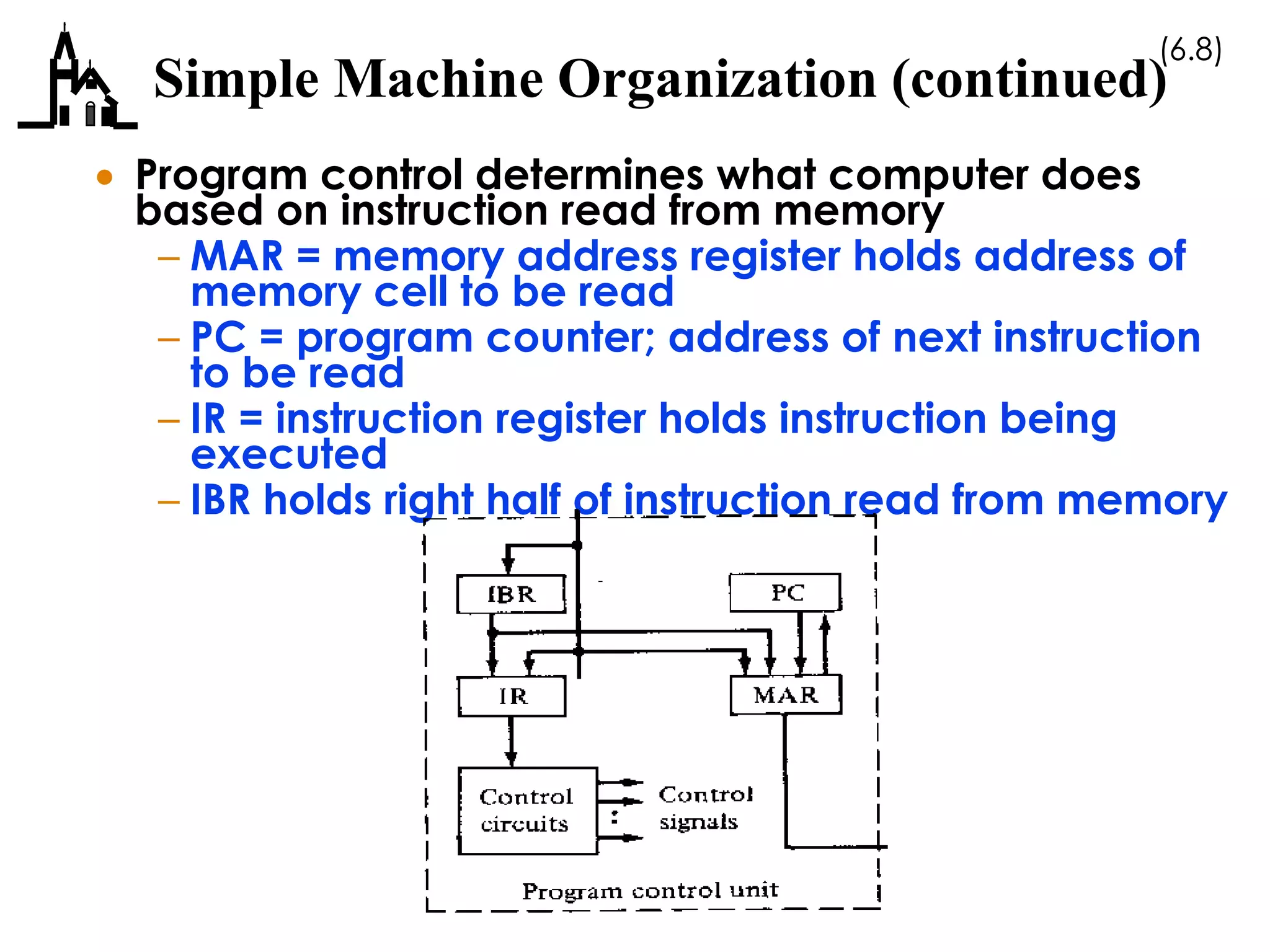

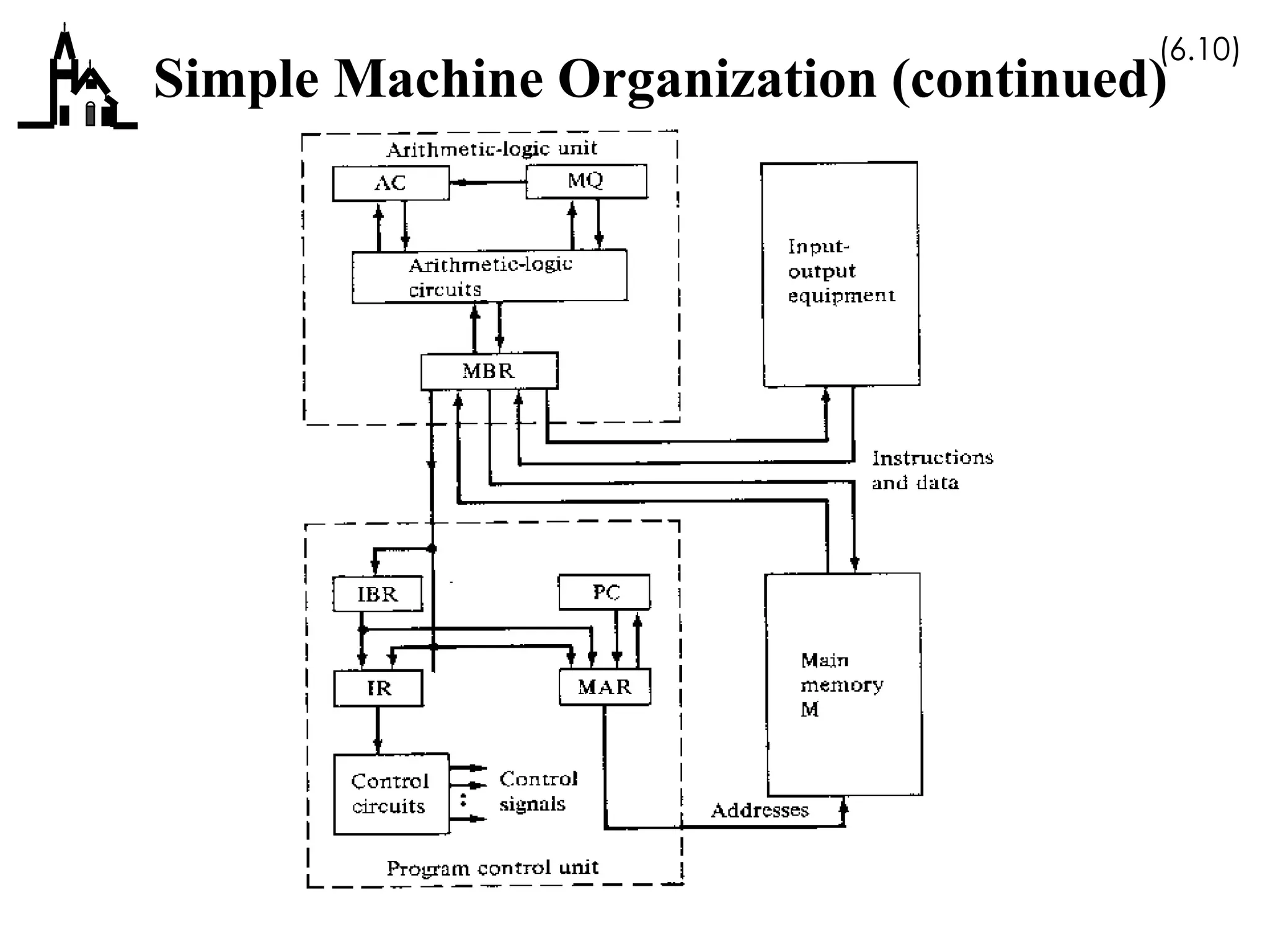






















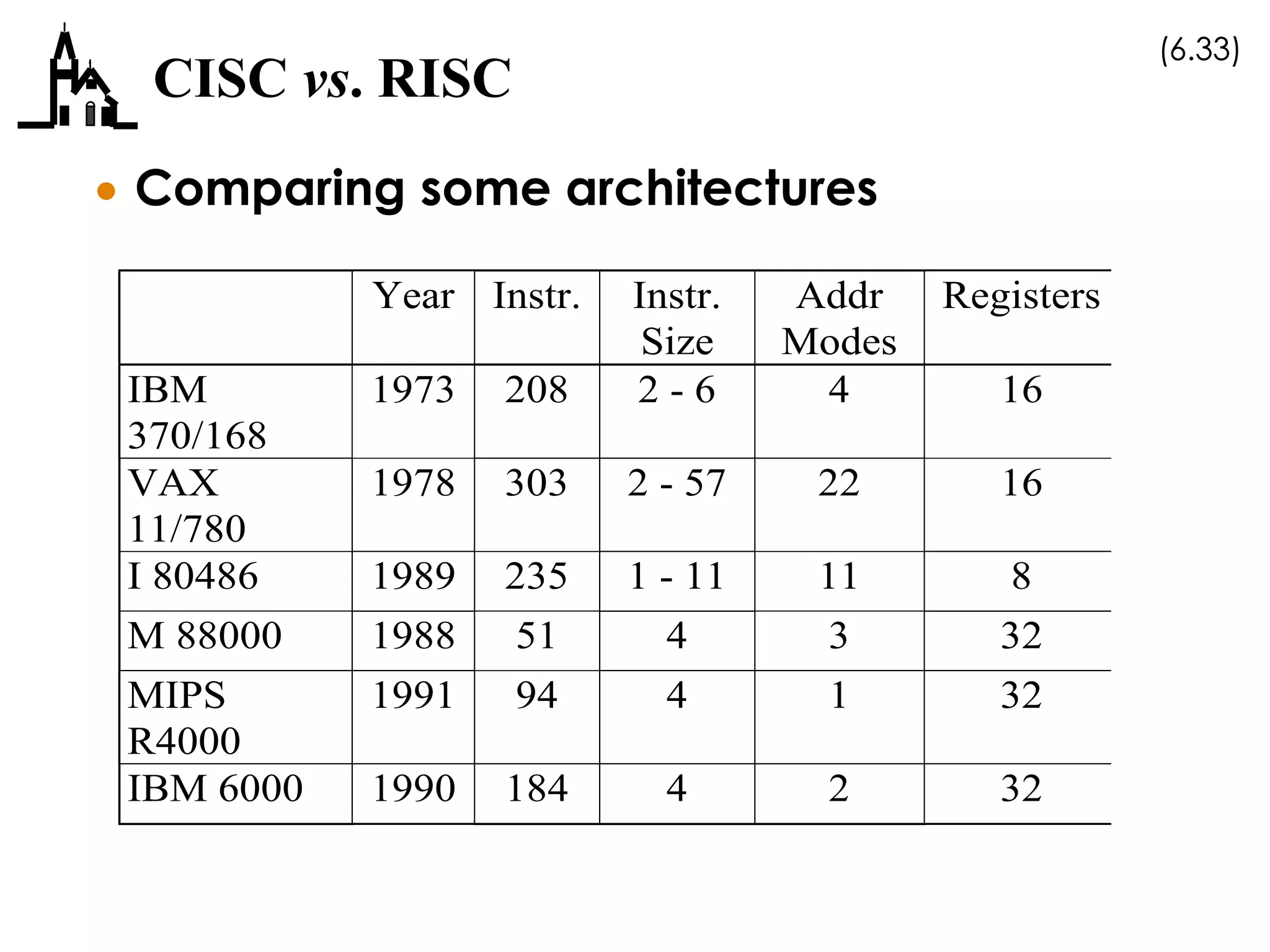


This document discusses computer architecture and organization. It covers the von Neumann architecture, techniques for speeding up CPUs like pipelining and superscalar execution, and differences between CISC and RISC instruction set architectures. It provides examples of simple machine organizations and how instructions are fetched and executed in a basic von Neumann architecture.



































































