Download as PDF, PPTX




![Chapter 1: Overview
Computing Resource Requests
Lattice QCD community aims for O(1−3) PFlops/s sustained beyond 2010.
Europe
– “The computational requirements voiced by these European groups sum up to more than
1 sustained Petaflop/s by 2009.” [HPC in Europe Taskforce (HET), 2006]
US (USQCD)
– Hope for O(1) PFlops/s sustained in 2010-11. “A goal with very substantial scientific
rewards.” [USQCD SciDAC-2 proposal, 2006]
Similar requests from Japan.
4 © 2009 IBM Corporation](https://image.slidesharecdn.com/22799452-qpace-qcd-parallel-computing-on-the-cell-broadband-engine-cell-b-e-091128140947-phpapp02/85/QPACE-QCD-Parallel-Computing-on-the-Cell-Broadband-Engine-Cell-B-E-4-320.jpg)






![Chapter 2: Application optimized supercomputers
Balanced Hardware
Example caxpy:
Processor FPU throughput Memory bandwidth
[FLOPS / cycle] [words / cycle] [FLOPS / word]
apeNEXT 8 2 4
QCDOC (MM) 2 0.63 3.2
QCDOC (LS) 2 2 1
Xeon 2 0.29 7
GPU 128 x 2 17.3 (*) 14.8
Cell/B.E. (MM) 8x4 1 32
Cell/B.E. (LS) 8x4 8x4 2
11 © 2009 IBM Corporation](https://image.slidesharecdn.com/22799452-qpace-qcd-parallel-computing-on-the-cell-broadband-engine-cell-b-e-091128140947-phpapp02/85/QPACE-QCD-Parallel-Computing-on-the-Cell-Broadband-Engine-Cell-B-E-11-320.jpg)




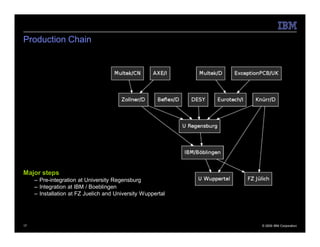


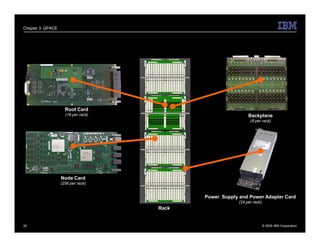


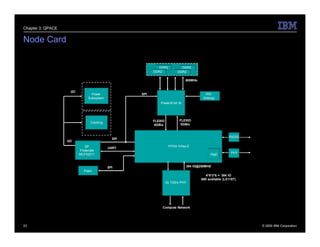
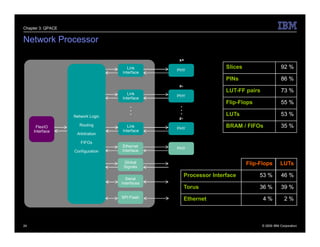
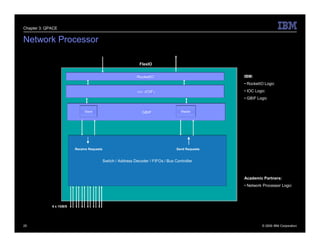

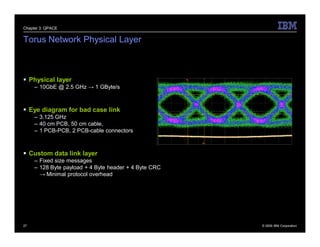
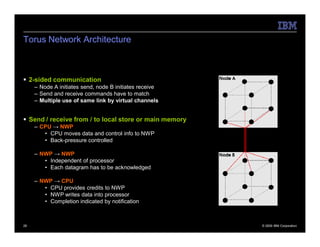


















The document describes the QPACE supercomputer project which aims to build a supercomputer optimized for lattice QCD simulations using IBM PowerXCell 8i processors. Key aspects summarized are: 1) QPACE uses 256 node cards per rack, each with a PowerXCell 8i processor, to achieve 26 TFLOPS and 1 TB memory per rack. 2) Custom networks include a 3D torus for nearest neighbor communication and an interrupt tree for global operations. 3) The node card design features the PowerXCell processor, FPGA network processor, memory, and networking interfaces. 4) Early results found the hardware design worked well but network processor implementation and software deployment took longer than planned.


















































































