Downloaded 146 times



































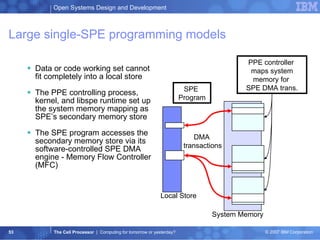
![Large single-SPE programming models – I/O data System memory for large size input / output data e.g. Streaming model System memory int ip[32] int op[32] SPE program: op = func(ip) DMA DMA Local store int g_ip[512*1024] int g_op[512*1024]](https://image.slidesharecdn.com/thecellprocessor-hs-albsig-12-04-2007-091130055311-phpapp01/85/The-Cell-Processor-54-320.jpg)
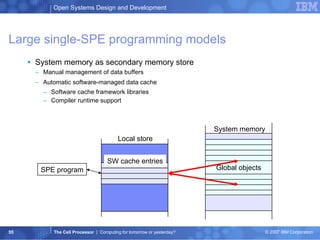
![Large single-SPE programming models - CESOF C ell E mbedded S PE O bject F ormat (CESOF) and PPE/SPE toolchains support the resolution of SPE references to the global system memory objects in the effective-address space. _EAR_g_foo structure Local Store Space Effective Address Space DMA transactions CESOF EAR symbol resolution Char g_foo[512] Char local_foo[512]](https://image.slidesharecdn.com/thecellprocessor-hs-albsig-12-04-2007-091130055311-phpapp01/85/The-Cell-Processor-59-320.jpg)

![libspe sample code #include <libspe.h> int main(int argc, char *argv[], char *envp[]) { spe_program_handle_t *binary; speid_t spe_thread; int status; binary = spe_open_image(argv[1]); if (!binary) return 1; spe_thread = spe_create_thread(0, binary, argv+1, envp, -1, 0); if (!spe_thread) return 2; spe_wait(spe_thread, &status, 0); spe_close_image(binary); return status; }](https://image.slidesharecdn.com/thecellprocessor-hs-albsig-12-04-2007-091130055311-phpapp01/85/The-Cell-Processor-64-320.jpg)
![libspe sample code #include <libspe.h> int main(int argc, char *argv[], char *envp[]) { spe_program_handle_t *binary; speid_t spe_thread; int status; binary = spe_open_image(argv[1]); if (!binary) return 1; spe_thread = spe_create_thread(0, binary, argv+1, envp, -1, 0); if (!spe_thread) return 2; spe_wait(spe_thread, &status, 0); spe_close_image(binary); return status; }](https://image.slidesharecdn.com/thecellprocessor-hs-albsig-12-04-2007-091130055311-phpapp01/85/The-Cell-Processor-65-320.jpg)
![libspe sample code #include <libspe.h> int main(int argc, char *argv[], char *envp[]) { spe_program_handle_t *binary; speid_t spe_thread; int status; binary = spe_open_image(argv[1]); if (!binary) return 1; spe_thread = spe_create_thread(0, binary, argv+1, envp, -1, 0); if (!spe_thread) return 2; spe_wait(spe_thread, &status, 0); spe_close_image(binary); return status; }](https://image.slidesharecdn.com/thecellprocessor-hs-albsig-12-04-2007-091130055311-phpapp01/85/The-Cell-Processor-66-320.jpg)





















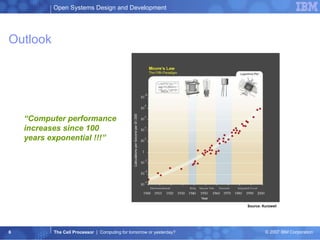
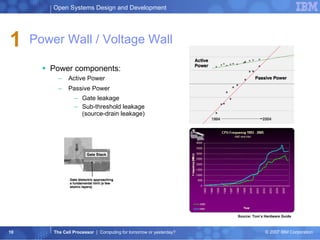
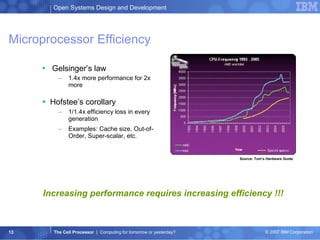
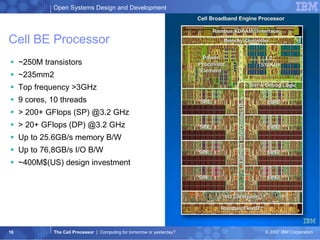
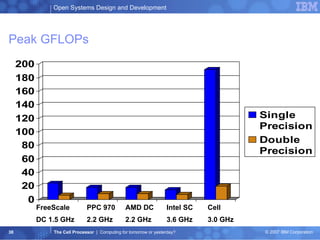
The document summarizes the Cell processor architecture, which was developed as a collaboration between IBM, Sony, and Toshiba to address limitations in processor performance. The Cell consists of 9 cores - 1 PowerPC core called the PPE and 8 synergistic processor elements (SPEs) optimized for SIMD operations. It has a peak performance of over 200 GFLOPS and was used in the PlayStation 3 game console to enable graphics-intensive applications. The document outlines the Cell architecture and how it aims to overcome performance walls related to power, memory, and frequency limitations.

















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)















