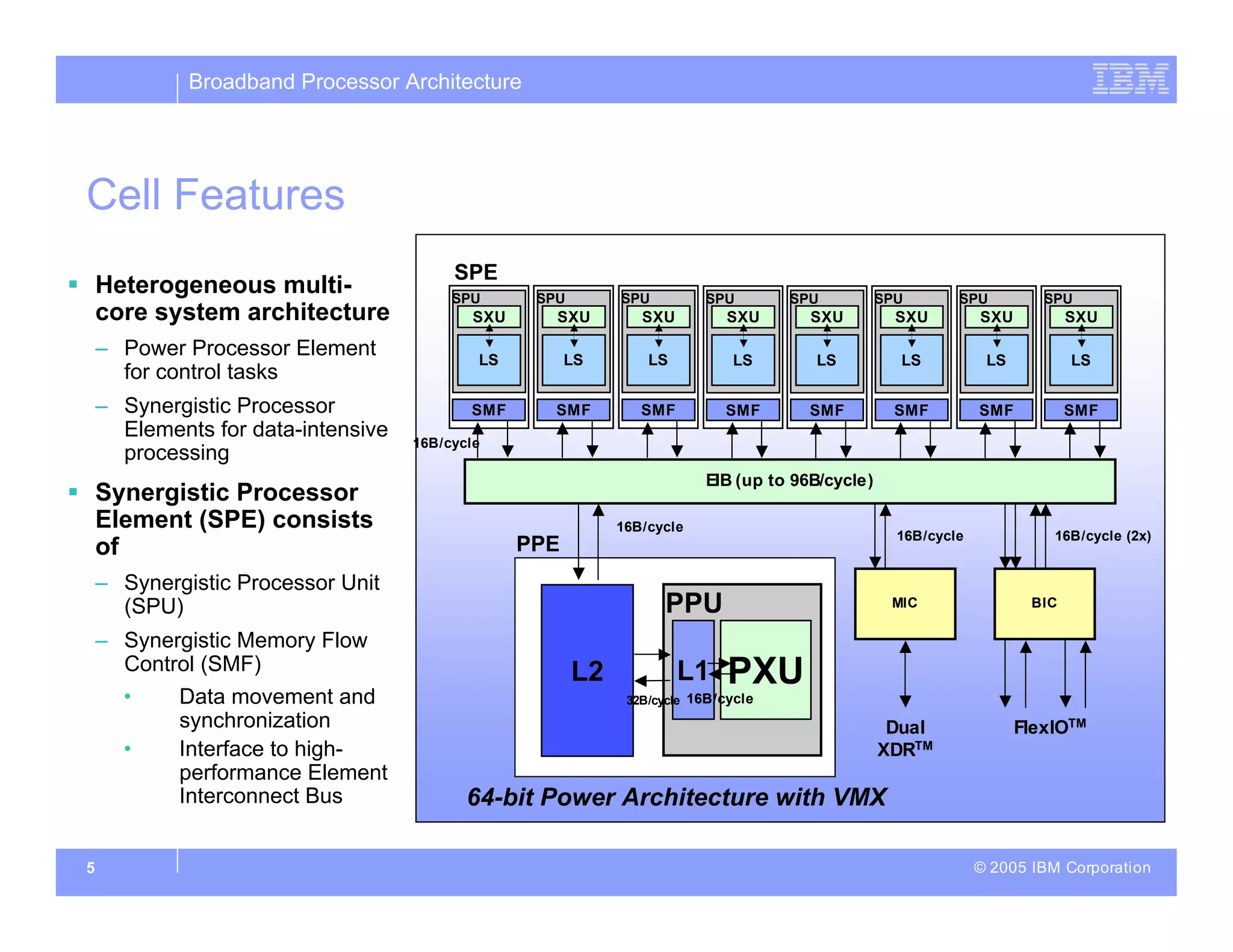
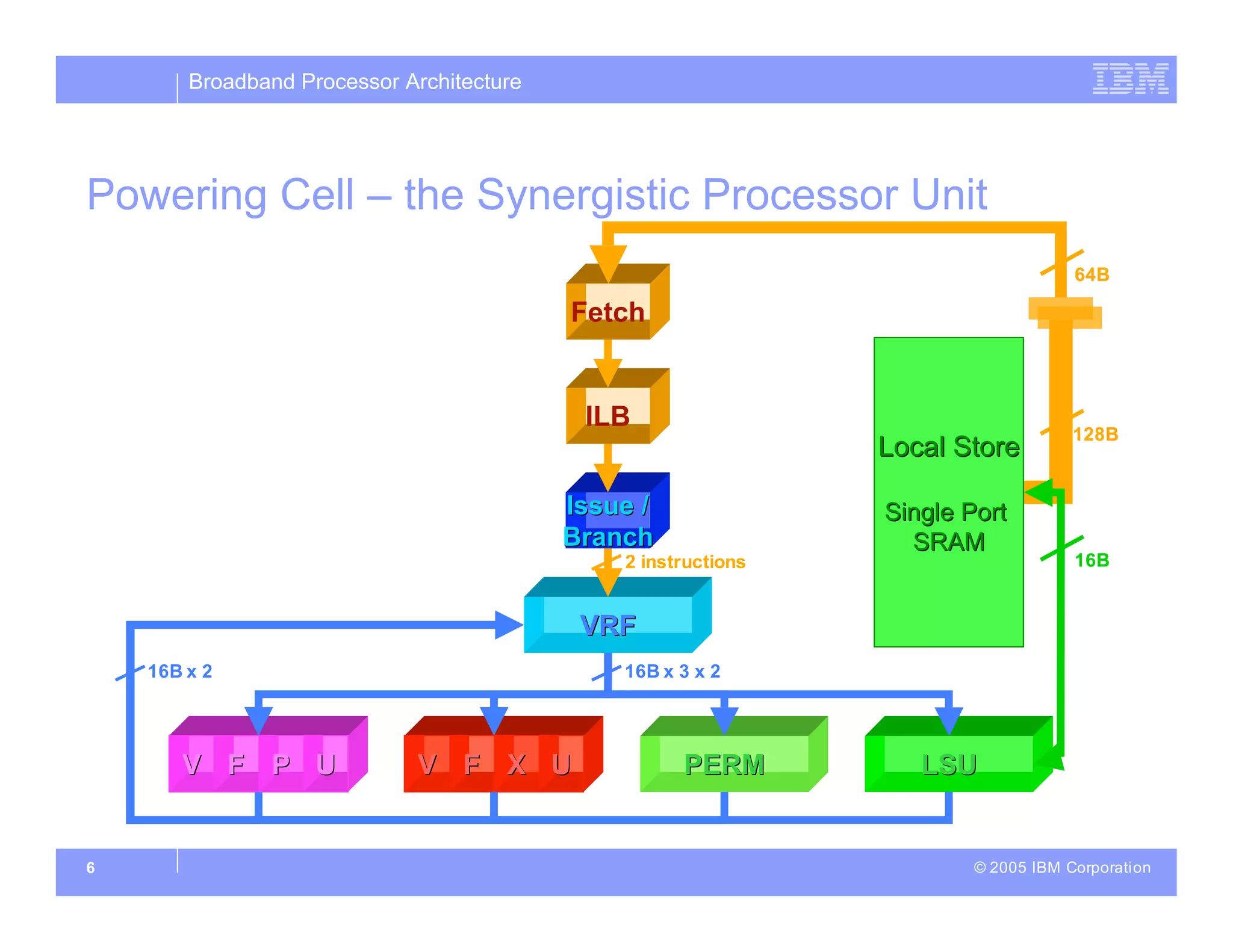
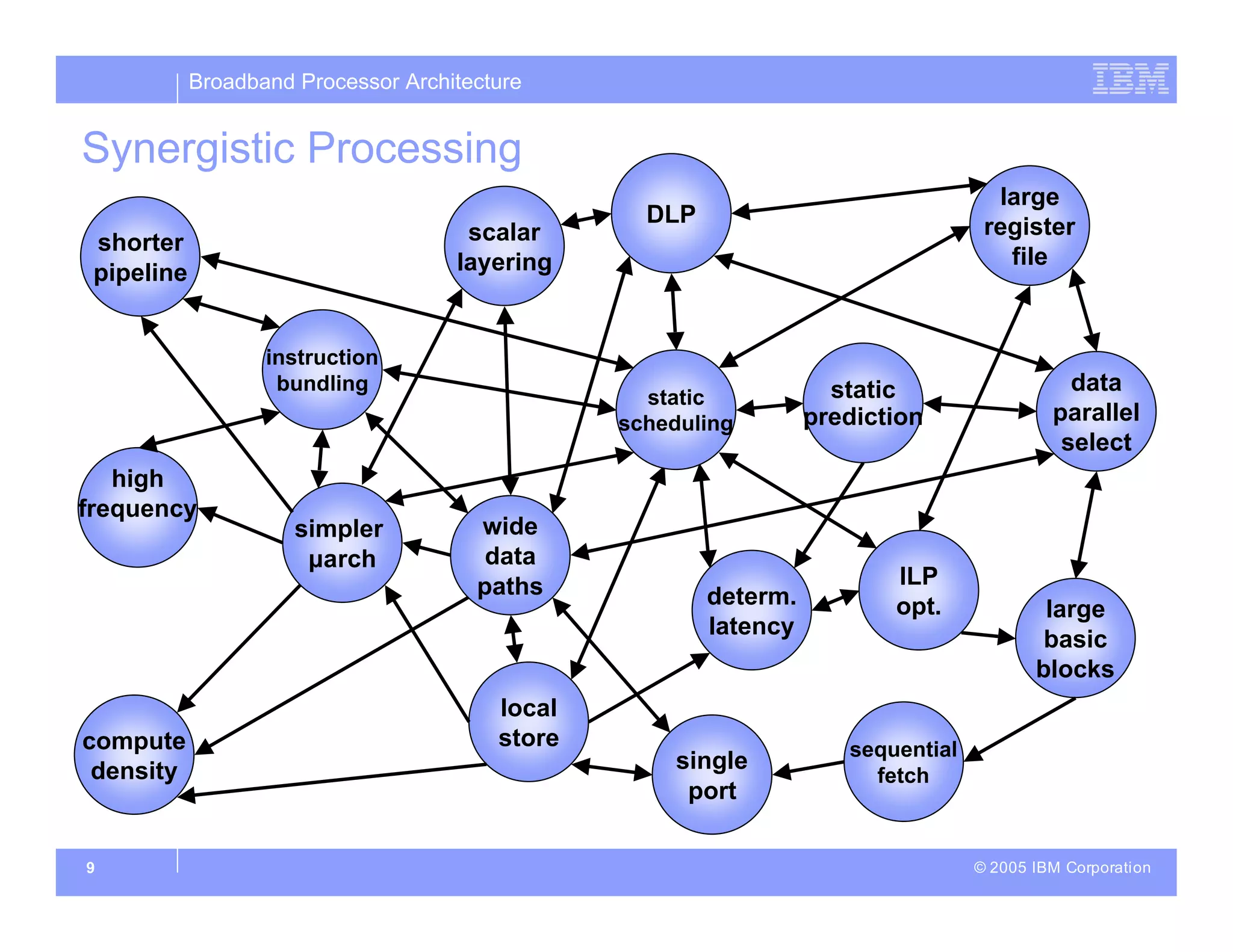
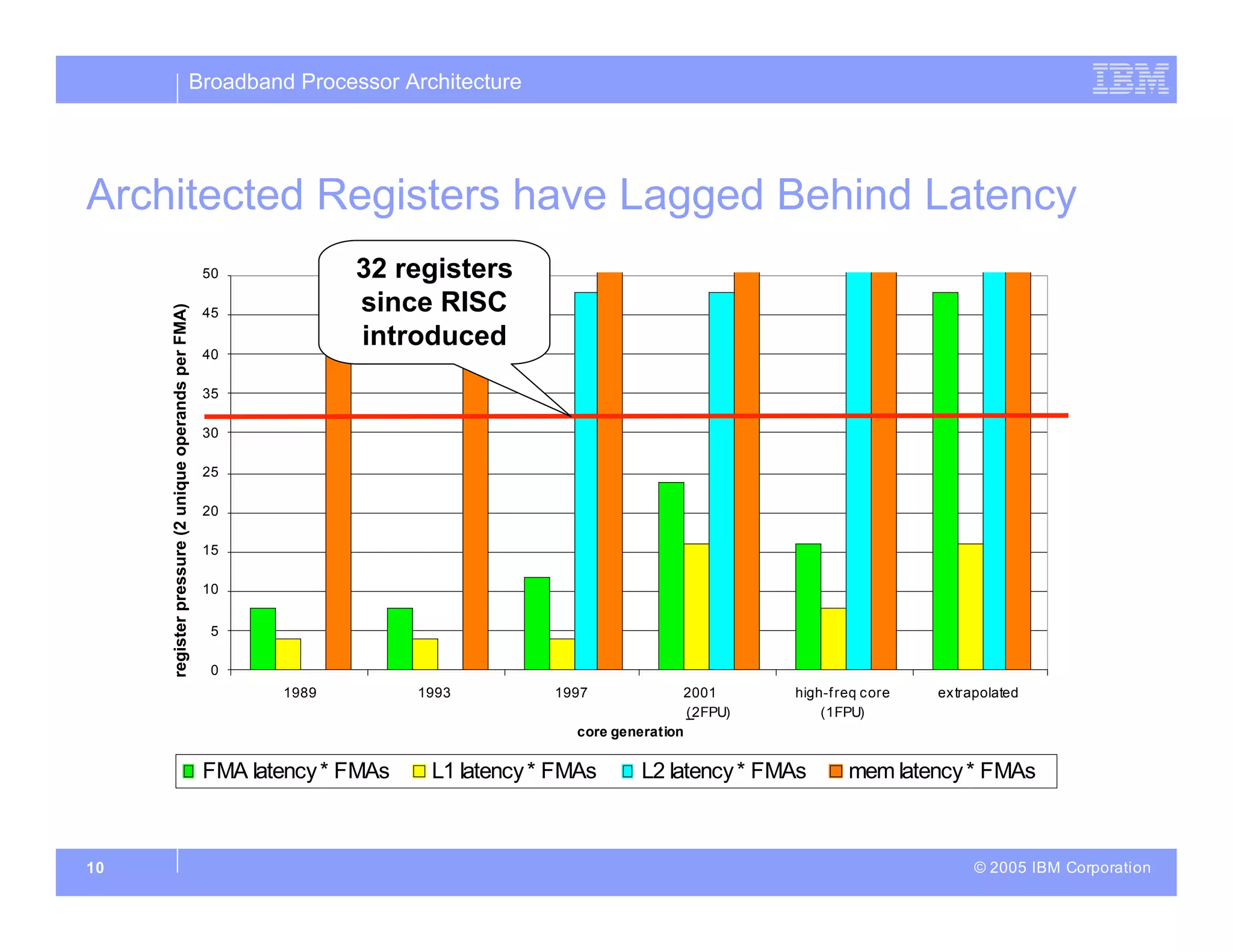
The document discusses the architecture of the Cell broadband processor, a collaborative effort by IBM, Sony, and Toshiba, aimed at enhancing computing performance through a SIMD (Single Instruction, Multiple Data) design. It emphasizes the Cell's ability to leverage application parallelism and features a heterogeneous multi-core design that balances thread-level, instruction-level, and data-level parallelism for improved efficiency. The document also details the technical specifications, data processing capabilities, and innovative strategies implemented to ensure high compute density for diverse applications.













![Broadband Processor Architecture
© 2005 IBM Corporation
18
Data Parallel Select Operation
for (i =0; i< VL; i++)
if (a[i]>b[i])
m[i] = a[i]*2;
else
m[i] = b[i]*3;
a[0]>b[0]
m[0]=a[0]*2; m[0]=b[0]*3;
a[1]>b[1]
m[1]=a[1]*2; m[1]=b[1]*3;
a[2]>b[2]
m[2]=a[2]*2; m[2]=b[2]*3;
a[3]>b[3]
m[3]=a[3]*2; m[3]=b[3]*3;
a’[0] =a[0]*2; b’[0]=b[0]*3;
s[0]=a[0]>b[0]
m[0]=s[0]?
a’[0]:b’[0]
a’[1]=a[1]*2; b’[1]=b[1]*3;
s[1]=a[1]>b[1]
m[1]=s[1]?
a’[1]:b’[1]
a’[2]=a[2]*2; b’[2]=b[2]*3;
s[2]=a[2]>b[2]
m[2]=s[2]?
a’[2]:b’[2]
a’[3]=a[3]*2; b’[3]=b[3]*3;
s[3]=a[3]>b[3]
m[3]=s[3]?
a’[3]:b’[3]
Exploit data parallelism
Long
latency](https://image.slidesharecdn.com/anovelsimdarchitectureforthecellheterogeneouschip-multiprocessor-210208025141/75/M-Gschwind-A-novel-SIMD-architecture-for-the-Cell-heterogeneous-chip-multiprocessor-18-2048.jpg)

















































![02 computer evolution and performance.ppt [compatibility mode]](https://cdn.slidesharecdn.com/ss_thumbnails/02computerevolutionandperformance-pptcompatibilitymode-120918022737-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















