Downloaded 22 times











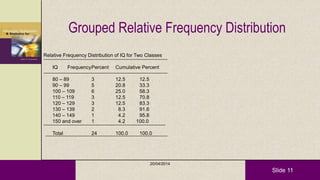











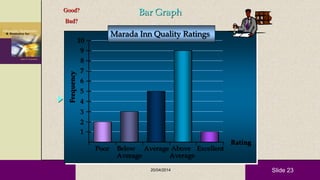
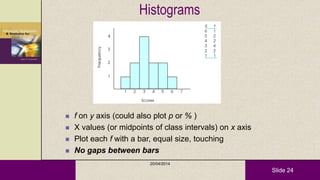






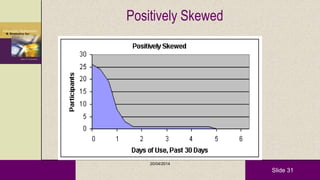
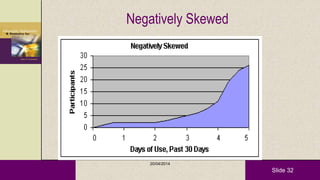




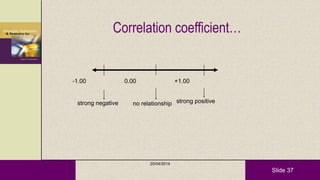









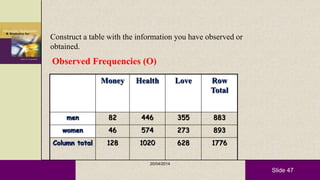
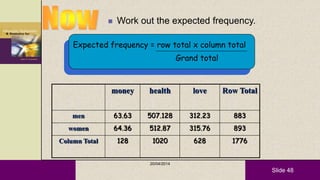
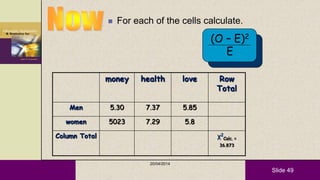





This document provides an overview of descriptive statistics and statistical analyses. It discusses different types of statistical analyses including descriptive analysis, which is used to describe data, and inferential analysis, which is used to make conclusions about populations based on samples. Descriptive statistics tools like tables, graphs, measures of central tendency, and measures of variability are presented. Measures of central tendency include mode, median, and mean, while measures of variability include range, standard deviation, and frequency distributions. Examples of different graphs like histograms, box plots, bar graphs and pie charts are also shown. The document concludes with discussing measures of relationships like correlation coefficients and introducing the chi-square test.

































































































