Deep Residual Learningfor
Image Recognition
2018/11/12
1
[1] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition.
In Proceedings of the IEEE conference on computer vision and pattern recognition
(pp. 770-778).
残差表現Ⅰ
Bag of VisualWords (BoVW) による情報抽出/次元削減
10
画像から特徴を抽出
(ex. 色,エッジなど)
各特徴点をクラスタリング
(クラスタ数に確証なし)
各クラスタをベクトルの要素とし
各画像をベクトルで表現
[8] Yang, J., Jiang, Y. G., Hauptmann, A. G., & Ngo, C. W. (2007, September). Evaluating bag-of-visual-words representations in scene
classification. In Proceedings of the international workshop on Workshop on multimedia information retrieval(pp. 197-206). ACM.
図5. BoVW の流れ[8]
11.
残差表現Ⅱ
フィルター間の差により,画像から特徴量を抽出(SIFT)
11
[9] Lowe, D.G. (2004). Distinctive image features from scale-invariant
keypoints. International journal of computer vision, 60(2), 91-110.
元画像
DoG フィルタを
画像に使用
局所的極値を
探索
特徴量を抽出
※図6. 元画像,Difference of Gausiann (DoG)の適用,
各スケール間の比較,特徴量抽出結果(左から)[9]
差分が最大となる点
Residual Learning
多重非線形関数が漸近的に複雑な関数を近似できる時
ℱ x∶= ℋ x − x (1)
ℱ x : residual function, x: ブロックへの入力層
ℋ x : 2層以上の非線形関数,元々の関数
ℋ x について解くと,
ℋ x = ℱ x + x (2)
(2)について学習しても,パラメータは変わらず計算も容易
15
Residual Learning では ℋ x = ℱ x + x について学習
![Deep Residual Learning for
Image Recognition
2018/11/12
1
[1] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition.
In Proceedings of the IEEE conference on computer vision and pattern recognition
(pp. 770-778).](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-1-320.jpg)
![Deep Residual Learning for
Image Recognition
2018/11/12
1
[1] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition.
In Proceedings of the IEEE conference on computer vision and pattern recognition
(pp. 770-778).](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/75/Deep-residual-learning-for-image-recognition-1-2048.jpg)
![ResNet の成果
ResNet の発表前と比べて,非常に深いネットワークを実現
2
[2] http://image-net.org/challenges/talks/ilsvrc2015_deep_residual_learning_kaiminghe.pdf
22層 ⇒ 152層
図1. ImageNet の分類タスクの発展[2]](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-2-320.jpg)
![背景
深層学習(CNN)は
ImageNet のような画像分類タスクで多大な効果を発揮
自然に低レベルから高レベルの特徴を接続可能
3
[3] LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the
IEEE, 86(11), 2278-2324.
[4] http://scs.ryerson.ca/~aharley/vis/conv/flat.html
高レベルな特徴
図2. LeNet の構造(下)[3]と LeNet の特徴マップ(上)[3]](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-3-320.jpg)
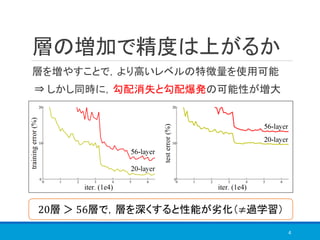
![目的
2014年における“深い”ネットワーク ⇒ 20層前後
2015年における“深い”ネットワーク ⇒ 100層以上?!
5
劣化せず,より“深い”ネットワーク構造の実現
図3. plain network (左) と residual learning (右) [1]
式変形
shortcut](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-5-320.jpg)

![勾配消失問題
一般的な勾配消失/発散問題に対する対策として
Normalized initialization
隠れ層の数から分散を決定した分布を初期値に使用[4]
Batch Normalization
バッチ内での正規化
Construction
浅い層で学習した初期値をより深い層の初期値に使用
7
[4] He, K., Zhang, X., Ren, S., & Sun, J. (2015). Delving deep into rectifiers: Surpassing human-level performance on
imagenet classification. In Proceedings of the IEEE international conference on computer vision (pp. 1026-1034).
Deeper
Shallower
network
Input
Output
Shallower
Input
Output
New layer重みを転用
⇐ copied
⇐ added](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-7-320.jpg)
![Shortcut Ⅰ
GoogLeNet [6]では
Shortcut Connections を使用
中間層から出力層へ
直接接続
Inception 内の
1 × 1 CNNによる
次元削減
8
[6] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., ... & Rabinovich, A. (2015). Going deeper
with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
図4. GoogleNetのモデル図[6]
出力層
計3つの shortcut
を用いることで,
勾配消失を回避
inception](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-8-320.jpg)
![Shortcut Ⅱ
Highway network[7]
LSTM のように,gating function を用いて学習
𝒚 = 𝐻 𝐱, 𝐖 𝐇 ∙ 𝐺 𝐱, 𝐖 𝐆 + 𝐱 ∙ 1 − 𝐺 𝐱, 𝐖 𝐆
𝒚:出力層,𝐱:入力層
𝐖 𝐇:隠れ層の重み,𝐖 𝐆:ゲート層の重み
𝐻 𝐱, 𝐖 :非線形関数, 𝐺 𝐱, 𝐖 :ゲート関数
gating function の問題点として
ゲートが閉じているとき,𝐺 𝐱, 𝐖 𝐆 = 0 となり,残差なし
100層以上ではモデルが劣化
9
[7] Srivastava, R. K., Greff, K., & Schmidhuber, J. (2015). Highway networks. arXiv preprint arXiv:1505.00387.](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-9-320.jpg)
![残差表現Ⅰ
Bag of Visual Words (BoVW) による情報抽出/次元削減
10
画像から特徴を抽出
(ex. 色,エッジなど)
各特徴点をクラスタリング
(クラスタ数に確証なし)
各クラスタをベクトルの要素とし
各画像をベクトルで表現
[8] Yang, J., Jiang, Y. G., Hauptmann, A. G., & Ngo, C. W. (2007, September). Evaluating bag-of-visual-words representations in scene
classification. In Proceedings of the international workshop on Workshop on multimedia information retrieval(pp. 197-206). ACM.
図5. BoVW の流れ[8]](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-10-320.jpg)
![残差表現Ⅱ
フィルター間の差により,画像から特徴量を抽出(SIFT)
11
[9] Lowe, D. G. (2004). Distinctive image features from scale-invariant
keypoints. International journal of computer vision, 60(2), 91-110.
元画像
DoG フィルタを
画像に使用
局所的極値を
探索
特徴量を抽出
※図6. 元画像,Difference of Gausiann (DoG)の適用,
各スケール間の比較,特徴量抽出結果(左から)[9]
差分が最大となる点](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-11-320.jpg)

![残差表現Ⅳ (おまけ)
先ほどの近似式を取り入れた BoVW の改良として
平均,分散を考慮した Fisher Vector
⇒ 次元数は[クラスタ数] × [平均と分散の次元数]
平均のみを考慮した VLAD
⇒ 次元数は[クラスタ数] × [平均の次元数]
13
図7. クラスタ数16,次元数16の VLAD の特徴量[10]
[10] Jegou, H., Perronnin, F., Douze, M., Sánchez, J., Perez, P., & Schmid, C. (2012). Aggregating local image descriptors
into compact codes. IEEE transactions on pattern analysis and machine intelligence, 34(9), 1704-1716.](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-13-320.jpg)
![本研究の概要
残差を考慮した residual learning
Shortcut による Identity Mapping
残差と shortcut を用いて,“深い”ネットワーク構造を実現
14
図3. plain network (左) と residual learning (右) [1]
式変形
shortcut](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-14-320.jpg)


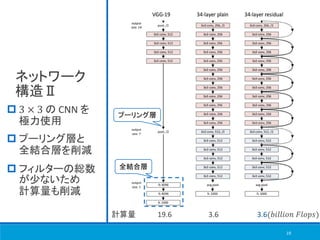
![18
ネットワーク
構造Ⅰ
VGG-19 を参考に
plain/residual nets
を構築[11]
画像サイズを縮小
するために
ダウンサンプリング
[11] Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image
recognition. arXiv preprint arXiv:1409.1556.
ダウン
サンプリング
(𝑟𝑒𝑠. 2)
(𝑟𝑒𝑠. 1)
CNN 内で
ダウン
サンプリング](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-18-320.jpg)
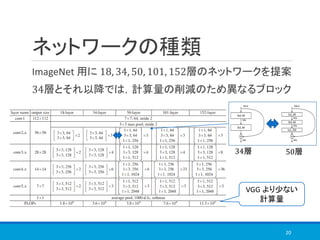
![実験対象
Object Classification
➢ImageNet
画像数: 1400万以上,synsets 数: 2万以上,pixcel 数: 256 × 256
※実験に用いた ImageNet-2012 では
画像数: 128万,synsets 数: 1000
➢Cifar-10
画像数: 6万,synsets 数: 10,pixcel 数: 32 × 32
Object Detection
Microsoft COCO データセット
画像数: 6万,カテゴリ数: 80
21
図8. COCOデータセット[12]
[12] Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., ... & Zitnick, C. L. (2014, September). Microsoft
coco: Common objects in context. In European conference on computer vision (pp. 740-755). Springer, Cham.](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-21-320.jpg)
![ImageNet の例
花の中でも,非常に細かな分類(4000以上)
22[13] http://image-net.org/explore
図9. ImageNet の synset 例[13]](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-22-320.jpg)
![Cifar-10 の例
ImageNet と比べると,非常に大まかな分類
23[14] https://www.cs.toronto.edu/~kriz/cifar.html
図10. Cifar-10 のカテゴリ[14]](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-23-320.jpg)

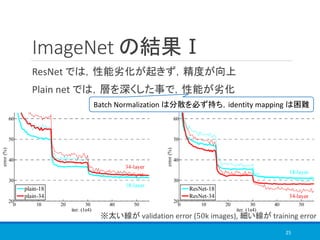
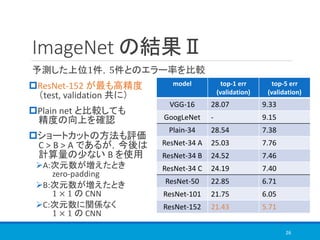

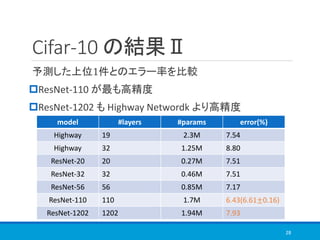
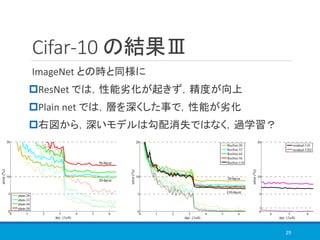
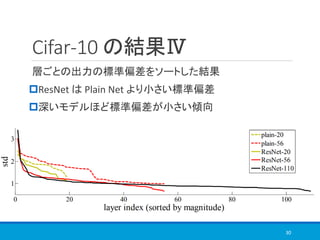
![COCO の結果
Faster R-CNN に VGG-16 と ResNet-101 を組み込んで学習
VGG に比べて高精度
31
図11. faster R-CNN[2]
物体の候補を
検出
VGG-16
or
ResNet-101
metric mAP@5 mAP@[.5, .95]
VGG-16 41.5 21.2
ResNet-101 48.4 27.2
※mAP(平均適合率)](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-31-320.jpg)
![まとめ
Residual Learning によって,深い層での学習に成功
152層のモデルを構築し,他手法よりも高い精度を達成
Object Classification だけてなく
Object Detection でも効果を示し
他のタスクでの有効性も確認
32
劣化せず,より“深い”ネットワーク構造の実現
図12. COCO に対する結果[2]
沢山あるから,注意深く見てね!!だそう](https://image.slidesharecdn.com/deepresiduallearningforimagerecognition-181113011900/85/Deep-residual-learning-for-image-recognition-32-320.jpg)



![[DL輪読会]A closer look at few shot classification](https://cdn.slidesharecdn.com/ss_thumbnails/acloserlookatfew-shotclassification-190304034759-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning convolutional neural networks for graphs](https://cdn.slidesharecdn.com/ss_thumbnails/learningconvolutionalneuralnetworksforgraphs-170222032121-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)







![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)

































