CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multiple Languages
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multiple Languages
Word Sense Disambiguation, BERT, clustering
ということで読みました.
p. 7 は「solid は glass の上位語,glassware は glass の下位語」でした。。。
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multiple Languages
1.
1. 2. 3.4. 5.
CluBERT:
A Cluster-Based Approach for
Learning Sense Distributions in Multiple Languages [1]
2020/07/21
1
[1] Pasini, T., Scozzafava, F., and Scarlini, B.: "CluBERT: A Cluster-Based Approach for
Learning Sense Distributions in Multiple Languages.“, ACL, pp. 4008-4018 (2020).
2.
1. 2. 3.4. 5.
2
論文情報
タイトル:
CluBERT: A Cluster-Based Approach for
Learning Sense Distributions in Multiple Languages
著者:
Pasini, T.1, Scozzafava, F.1, and Scarlini, B.1
1: Sapienza NLP Group, Department of Computer Science, Sapienza University of Rome
出典: ACL 2020
選定理由: clustering と BERT の組み合わせに興味があった
BabelNet [2] の著者 Navigli, R. も同組織所属
1. 2. 3.4. 5.
14
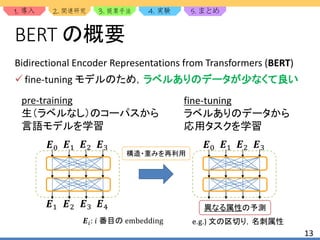
BERT の学習
1. マスクした単語の予測 ≈ 𝑐𝑙𝑜𝑧𝑒 テスト
𝑐𝑙𝑜𝑧𝑒 テスト マスクした単語の予測
the man _____ to the store the man [Mask] to the store
BERT はマスクした単語と文章の連続性の2つを学習
2. 文章の連続性の予測
A) The man went to [MASK] store.
B) He bought a gallon [MASK] milk.
不要とも言われている
A と B の文は連続?
15.
1. 2. 3.4. 5.
15
提案手法の概要
生コーパスから単語がもつ意味の分布を獲得 & 多言語対応
𝐶:コーパス,𝑙: 見出し語,𝑀𝑙: 見出し語 𝑙 が持ち得る意味集合
1. Sentence Clustering
𝑔𝑙𝑎𝑠𝑠 を含む
文(∈ 𝐶)の集合
2. Clustering Disambiguation 3. Distribution Extraction
コーパス 𝐶 中の
意味の分布を獲得
𝑔𝑙𝑎𝑠𝑠 𝑁
1
𝑔𝑙𝑎𝑠𝑠 𝑁
2
0.4
0.68 𝑔𝑙𝑎𝑠𝑠 𝑁
1
0.6𝑔𝑙𝑎𝑠𝑠 𝑁
2
0.32
𝑔𝑙𝑎𝑠𝑠 𝑁
1
0.48
𝑔𝑙𝑎𝑠𝑠 𝑁
2
0.52
𝑀𝑔𝑙𝑎𝑠𝑠 = {𝑔𝑙𝑎𝑠𝑠 𝑁
1
, 𝑔𝑙𝑎𝑠𝑠 𝑁
2
}
Cluster 1
… 𝑔𝑙𝑎𝑠𝑠 requires lower temperatures.
.. walls are made out of 𝑔𝑙𝑎𝑠𝑠.
Cluster 2
He asked for a 𝑔𝑙𝑎𝑠𝑠 of water.
It is traditionally served in a 𝑔𝑙𝑎𝑠𝑠.
1. クラスタを頻出語で表現
2. クラスタ内の分布の導出
実際は,2つ以上の意味が存在
materialn
metaln
plasticn
winen
watern
drinkn
16.
1. 2. 3.4. 5.
16
Sentence Clustering
見出し語を含む文に対してベクトル表現を獲得し,クラスタリング
𝑀𝑔𝑙𝑎𝑠𝑠 = {𝑔𝑙𝑎𝑠𝑠 𝑁
1
, 𝑔𝑙𝑎𝑠𝑠 𝑁
2
, . . } BabelNet 上では,30個近い意味が存在
… 𝑔𝑙𝑎𝑠𝑠 requires lower temperatures.
He asked for a 𝑔𝑙𝑎𝑠𝑠 of water.
.. walls are made out of 𝑔𝑙𝑎𝑠𝑠.
It is traditionally served in a 𝑔𝑙𝑎𝑠𝑠.
1. コーパス 𝐶 から見出し語 𝑔𝑙𝑎𝑠𝑠 を含む文 𝑆 の抽出
2. BERT による文脈における単語の表現 𝒗 𝜎
𝑙 (𝜎 ∈ 𝑆) を獲得
3. 𝑘-means によるクラスタリング
𝒗 𝜎
𝑙
= BERT(𝜎, 𝑙)
1. 文の抽出 2. 特徴空間への写像 3. クラスタリング
17.
1. 2. 3.4. 5.
17
Cluster Disambiguation
1. クラスタを頻出語の Bag of Words (BoW) で表現
2. PPR で得られた値 𝒗 𝑡+1 を正規化し,分布を取得
Cluster 1
… 𝑔𝑙𝑎𝑠𝑠 requires lower temperatures.
.. walls are made out of 𝑔𝑙𝑎𝑠𝑠.
Cluster 2
He asked for a 𝑔𝑙𝑎𝑠𝑠 of water.
It is traditionally served in a 𝑔𝑙𝑎𝑠𝑠.
ベクトル空間
頻出語(top-𝑛)
material, metal, …
water, wine, …
𝒗 𝑡+1 = 1 − 𝛼 𝒗0 + 𝛼𝑨𝒗 𝑡
PPR: 下記の式を繰り返すことで関連度を導出するアルゴリズム
𝛼 = 0.85, 𝑨: 全 synset 間の有向グラフ,
𝒗0: BoW 内の単語がもつ synset の値を 1 とするベクトル
今回は正規化した頻度を値に使用?
1. 2. 3.4. 5.
30
参考文献(1)
[2] Navigli, R., and Ponzetto, S. P.: “BabelNet: Building a very large
multilingual semantic network.”, ACL, pp. 216—225 (2010).
[3] Navigli, R., Jurgens, D., and Vannella, D.: “Semeval-2013 task 12:
Multilingual word sense disambiguation.”, SemEval, pp. 222—231
(2013).
[4] Devlin, J., Chang, M. W., Lee, K., and Toutanova, K.: “Bert: Pre-
training of deep bidirectional transformers for language
understanding.”, NAACL, Vol. 1, pp. 4171—4186 (2019).
[5] Miller, G.A.: “WordNet: A Lexical Database for English.”,
Communications of the ACM, Vol. 38, No. 11, pp. 39—41 (1995).
[6] Sutskever, I., Vinyals, O., and Le, Q. V.: “Sequence to sequence
learning with neural networks.”, NIPS, pp. 3104—3112 (2014).
31.
1. 2. 3.4. 5.
31
参考文献(2)
[7] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L.,
Gomez, A. N., Kaiser, Ł., and Polosukhin, I.: “Attention is all you
need.”, NIPS, pp. 5998—6008 (2017).
[8] Raganato, A., Bovi, C. D., and Navigli, R.: “Neural sequence
learning models for word sense disambiguation.”, EMNLP, pp.
1156—1167 (2017).
[9] Agirre, E., López de Lacalle, O., and Soroa, A.: “Random walks for
knowledge-based word sense disambiguation.”, Computational
Linguistics, Vol. 40, No. 1, pp. 57—84 (2014).
[10] Pasini, T., and Navigli, R.: “Two knowledge-based methods for
high-performance sense distribution learning.”, AAAI, pp. 5374—
5381 (2018).
32.
1. 2. 3.4. 5.
32
参考文献(3)
[11] Hauer, B., Luan, Y., and Kondrak, G.: “You Shall Know the Most
Frequent Sense by the Company it Keeps.”, IEEE ICSC, pp. 208—215
(2019).
[12] Bennett, A., Baldwin, T., Lau, J. H., McCarthy, D., and Bond, F.:
“Lexsemtm: A semantic dataset based on all-words unsupervised
sense distribution learning.”, ACL, Vol. 1, pp. 1513—1524 (2016).
[13] Moro, A., and Navigli, R.: “Semeval-2015 task 13: Multilingual
all-words sense disambiguation and entity linking.”, SemEval, pp.
288—297 (2015).
![1. 2. 3. 4. 5.
CluBERT:
A Cluster-Based Approach for
Learning Sense Distributions in Multiple Languages [1]
2020/07/21
1
[1] Pasini, T., Scozzafava, F., and Scarlini, B.: "CluBERT: A Cluster-Based Approach for
Learning Sense Distributions in Multiple Languages.“, ACL, pp. 4008-4018 (2020).](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-1-320.jpg)
![1. 2. 3. 4. 5.
CluBERT:
A Cluster-Based Approach for
Learning Sense Distributions in Multiple Languages [1]
2020/07/21
1
[1] Pasini, T., Scozzafava, F., and Scarlini, B.: "CluBERT: A Cluster-Based Approach for
Learning Sense Distributions in Multiple Languages.“, ACL, pp. 4008-4018 (2020).](https://image.slidesharecdn.com/clubert-200721002735/75/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-1-2048.jpg)
![1. 2. 3. 4. 5.
2
論文情報
タイトル:
CluBERT: A Cluster-Based Approach for
Learning Sense Distributions in Multiple Languages
著者:
Pasini, T.1, Scozzafava, F.1, and Scarlini, B.1
1: Sapienza NLP Group, Department of Computer Science, Sapienza University of Rome
出典: ACL 2020
選定理由: clustering と BERT の組み合わせに興味があった
BabelNet [2] の著者 Navigli, R. も同組織所属](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-2-320.jpg)
![1. 2. 3. 4. 5.
4
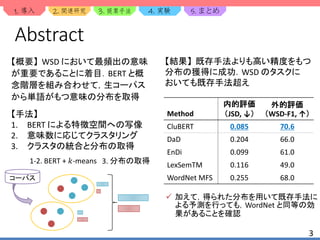
背景
Word Sense Disambiguation (WSD,語義曖昧性解消)のタスク
WSD の性能向上は機械翻訳など他タスクでの精度向上にも寄与
They bombed the Bogota offices last month, …
省庁,政府の行政単位
e.g.) SemEval-2013 task 12 [3]
office
1. 事務所
2. 省庁
3. 役割 文中の単語の意味を特定
文の意味をより明らかに
概念階層上の意味
e.g.) BabelNet [2]](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-4-320.jpg)
![1. 2. 3. 4. 5.
5
WSD が抱える課題
知識ベースでも,正確/十分なネットワークを持たない語が存在
課題: ラベル付きデータの不足 = 教師あり学習が困難
最頻出な意味を選択することで,強いベースラインが作成可能
e.g.) SemEval-2013 task 12 [3]
打開策: Most Frequent Sense (MFS) の利用
課題: 頻度の取得に必要なデータの不足/情報が古い
IT (Italian) ES (Spanish) FR (France) DE (German)
インスタンス数 1490 1260 1449 1076](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-5-320.jpg)
![1. 2. 3. 4. 5.
6
目的
ラベル付きデータの不足 = 教師あり学習が困難
頻度の取得に必要なデータの不足/情報が古い
解決策: 生コーパスからの分布の取得
課題
類似した意味は類似した文脈で使われることに着目
BERT[4]:特徴空間への写像 + BabelNet:クラスタ数と分布の算出
𝑔𝑙𝑎𝑠𝑠 𝑁
2
0.4
𝑔𝑙𝑎𝑠𝑠 𝑁
1
0.6
𝑔𝑙𝑎𝑠𝑠 を含む
文(∈ 𝐶)の集合
クラスタリング
BERT , BabelNet, 𝑘-means
分布の取得
BabelNet, PageRank](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-6-320.jpg)
![1. 2. 3. 4. 5.
7
概念階層:WordNet[5] & BabelNet
概念の関係を階層的に記した言語資源.意味の分布も保持
概念階層上での記述方式: 𝑙𝑒𝑚𝑚𝑎 𝑃𝑎𝑟𝑡_𝑜𝑓_𝑆𝑝𝑝𝑒𝑐ℎ
𝑠𝑦𝑛𝑠𝑒𝑡_𝑛𝑢𝑚𝑏𝑒𝑟
𝑔𝑙𝑎𝑠𝑠 𝑁
2
: 容器
𝑔𝑙𝑎𝑠𝑠 𝑁
1
𝑠𝑜𝑙𝑖𝑑 𝑁
1
𝑔𝑙𝑎𝑠𝑠𝑤𝑎𝑟𝑒 𝑁
1
, 𝑔𝑙𝑎𝑠𝑠𝑤𝑜𝑟𝑘 𝑁
1
今回は多言語対応の BabelNet を使用
synset (a set of one/more synonyms)
is-a
is-a𝑔𝑙𝑎𝑠𝑠 𝑁
1
: 素材
solid は glass の上位語,glassware は glasswork の下位語](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-7-320.jpg)
![1. 2. 3. 4. 5.
8
時系列の深層学習モデル
seq2seq [6]
Recurrent Neural Network (RNN) によるエンコーダ・デコーダ
Transformer [7]
Attention 構造と全結合層によるエンコーダ・デコーダ
エンコーダ デコーダ
エンコーダ デコーダ
𝒉0 𝒉1 𝒉2 𝒉3
𝒉 𝑓𝑖𝑛𝑎𝑙
𝒉
: RNN の各 cell
𝒉𝑖: 𝑖 番目の隠れ層の状態
𝒉 𝑓𝑖𝑛𝑎𝑙: 2層の biRNN の結合
𝒉 = [𝒉0, 𝒉1, 𝒉2, 𝒉3]
: Attention 構造
Attention による接続
Attention 構造後に順序毎に
独立の全結合層
𝒉0 𝒉1 𝒉2 𝒉3
𝒉
𝒉 として文単位の表現を,𝒉𝑖 として文脈における単語の表現を獲得可能](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-8-320.jpg)

教師あり学習では類似の学習方法が多め
BiLSTM Layer
he later check the report
Attention Layer
Embedding Layer
Fully-connected Layer
Softmax WSD + PoS + LEX
WSD he 𝑙𝑎𝑡𝑒𝑟𝑅
1
𝑐ℎ𝑒𝑐𝑘 𝑉
1 the 𝑟𝑒𝑝𝑜𝑟𝑡 𝑁
3
PoS PRON ADV VERB DET NOUN
LEX other adv.all verb.
cognition
other noun.
communication
ラベルがない場合も
マルチラベル予測](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-9-320.jpg)
![1. 2. 3. 4. 5.
10
Knowledge-based approach
UKB [9]: 文脈を考慮した Personalized PageRank (PPR)
𝒗 𝑡+1
= 1 − 𝛼 𝒗0
+ 𝛼𝑨𝒗 𝑡
PPR: 下記の式を繰り返すことで関連度を導出するアルゴリズム
𝛼 = 0.85, 𝑨: 全 synset 間の有向グラフ,
𝒗0: 文上の全単語 / 対象を除いた単語がもつ synset の値を 1 とするベクトル
coach fleet comprise ... seat
𝑐𝑜𝑎𝑐ℎ 𝑁
1
𝑐𝑜𝑎𝑐ℎ 𝑁
5
𝑐𝑜𝑎𝑐ℎ 𝑁
2
𝑡𝑢𝑡𝑜𝑟𝑖𝑎𝑙 𝑁
1𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑁
1
𝑐𝑜𝑚𝑝𝑟𝑖𝑠𝑒 𝑉
1
𝑓𝑙𝑒𝑒𝑡 𝑁
2
𝑠𝑒𝑎𝑡 𝑁
1
𝑡𝑟𝑎𝑖𝑛𝑒𝑟 𝑁
1
ℎ𝑎𝑛𝑑𝑙𝑒 𝑛
8
𝑠𝑝𝑜𝑟𝑡 𝑁
1
無向でも良い.実装上の問題?](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-10-320.jpg)
![1. 2. 3. 4. 5.
Pasini らによる手法 [10]
生コーパスに対して文ごとに意味の確率を導出し,分布を算出
11
Sense Distribution Learning (1)
P 𝑠 𝜎, 𝑤 =
P 𝑤1, … , 𝑤 𝑛 𝑠, 𝑤 P 𝑠 𝑤
P 𝑤1, … , 𝑤 𝑛 𝑤
≈ 𝑤′∈𝜎 max
𝑠∈𝑆
( 𝒗PPR 𝑠
, 𝑤′)
今回の比較対象: knowledge-base + distribution
同一著者
まとめ方
Entropy-based Distribution learning (EnDi)
Domain-aware Distribution learning (DaD)
Sentence 𝒑𝒍𝒂𝒏𝒆 𝑵
𝟏
(aircraft)
𝒑𝒍𝒂𝒏𝒆 𝑵
𝟐
(geometry)
on the plane 0.92 0.08
special plane curves 0.10 0.90
… … …
𝒟 𝑝𝑙𝑎𝑛𝑒 0.60 0.40
※値は適当
𝑠: sense, 𝑤: target word, 𝜎 = {𝑤1, … , 𝑤 𝑛}: sentence 互いの意味が独立と仮定
単語ごとに分布 𝒟 𝑤𝑜𝑟𝑑 を算出](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-11-320.jpg)
![1. 2. 3. 4. 5.
12
Sense Distribution Learning (2)
Hauer らによる手法 [11]
COMP2SENSE
共起語と WordNet の synset 間距離による重みづけ
WCT-VEC
synset ごとにベクトルを導出.類似度の比較により MFS を導出
strong baseline?
MFS 𝑤
= argmax 𝑠∈𝑆{𝜒1cos 𝒔 𝑤,𝑠, 𝒗 𝑤 + 𝜒2cos 𝒔 𝑤,𝑠, 𝒄 𝑤 + 𝜒3cos(𝒔 𝑤,𝑠, 𝒕 𝑤)}
𝜒𝑖: 非負のパラメータ,𝒗 𝑤: word vector,𝒄 𝑤: 共起語の平均ベクトル?
𝒔 𝑤,𝑠: WordNet から取得した類義語の平均ベクトル,𝒕 𝑤: 翻訳語のベクトル
精度は高くなく,メインの比較対象ではない
LexSemTM [12]
topic modeling である HCA を用いて分布を取得
略称しかない?](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-12-320.jpg)
![1. 2. 3. 4. 5.
14
BERT の学習
1. マスクした単語の予測 ≈ 𝑐𝑙𝑜𝑧𝑒 テスト
𝑐𝑙𝑜𝑧𝑒 テスト マスクした単語の予測
the man _____ to the store the man [Mask] to the store
BERT はマスクした単語と文章の連続性の2つを学習
2. 文章の連続性の予測
A) The man went to [MASK] store.
B) He bought a gallon [MASK] milk.
不要とも言われている
A と B の文は連続?](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-14-320.jpg)






![1. 2. 3. 4. 5.
22
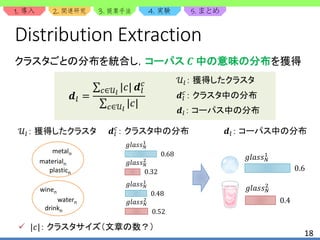
内的評価:結果
Gold distribution [12] との分布の一致度を評価
Method Type JSD (↓) WO (↑)
CluBERT Knowledge? 0.085 0.958
DaD Knowledge 0.204 0.902
EnDi Knowledge 0.099 0.937
LexSemTM Topic model 0.116 0.932
WordNet MFS MFS 0.255 0.837
エラーの大半は名詞属性の意味が不足していたことが原因
e.g.) 複合語,固有名詞
解決策:より多くの意味を事前に取得
逆に言うと,言語資源が備える意味の網羅率に精度が依存
どちらの指標でも高精度](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-22-320.jpg)
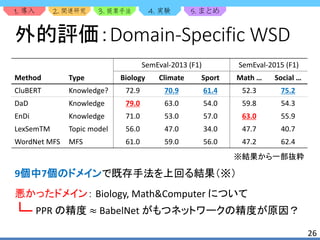
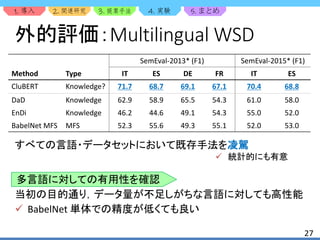
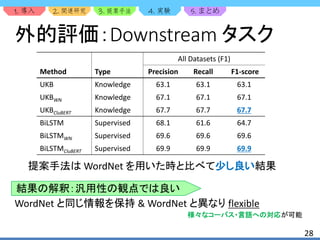
![1. 2. 3. 4. 5.
23
外的評価:評価データセット
WSD の評価に用いられる基本的なデータセットを使用
e.g.) SemEval-2013 [2], SemEval-2015 [13]
They bombed the Bogota offices last month, …
省庁,政府の行政単位office
1. 事務所
2. 省庁
3. 役割 文中の単語の意味を特定
概念階層上の意味
e.g.) BabelNet[2]
SemEval-2013, SemEval-2015 は複数のドメイン・言語に対応
古いバージョンの BabelNet を用いた時,SemEval-2013* と表記](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-23-320.jpg)


![1. 2. 3. 4. 5.
30
参考文献(1)
[2] Navigli, R., and Ponzetto, S. P.: “BabelNet: Building a very large
multilingual semantic network.”, ACL, pp. 216—225 (2010).
[3] Navigli, R., Jurgens, D., and Vannella, D.: “Semeval-2013 task 12:
Multilingual word sense disambiguation.”, SemEval, pp. 222—231
(2013).
[4] Devlin, J., Chang, M. W., Lee, K., and Toutanova, K.: “Bert: Pre-
training of deep bidirectional transformers for language
understanding.”, NAACL, Vol. 1, pp. 4171—4186 (2019).
[5] Miller, G.A.: “WordNet: A Lexical Database for English.”,
Communications of the ACM, Vol. 38, No. 11, pp. 39—41 (1995).
[6] Sutskever, I., Vinyals, O., and Le, Q. V.: “Sequence to sequence
learning with neural networks.”, NIPS, pp. 3104—3112 (2014).](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-30-320.jpg)
![1. 2. 3. 4. 5.
31
参考文献(2)
[7] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L.,
Gomez, A. N., Kaiser, Ł., and Polosukhin, I.: “Attention is all you
need.”, NIPS, pp. 5998—6008 (2017).
[8] Raganato, A., Bovi, C. D., and Navigli, R.: “Neural sequence
learning models for word sense disambiguation.”, EMNLP, pp.
1156—1167 (2017).
[9] Agirre, E., López de Lacalle, O., and Soroa, A.: “Random walks for
knowledge-based word sense disambiguation.”, Computational
Linguistics, Vol. 40, No. 1, pp. 57—84 (2014).
[10] Pasini, T., and Navigli, R.: “Two knowledge-based methods for
high-performance sense distribution learning.”, AAAI, pp. 5374—
5381 (2018).](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-31-320.jpg)
![1. 2. 3. 4. 5.
32
参考文献(3)
[11] Hauer, B., Luan, Y., and Kondrak, G.: “You Shall Know the Most
Frequent Sense by the Company it Keeps.”, IEEE ICSC, pp. 208—215
(2019).
[12] Bennett, A., Baldwin, T., Lau, J. H., McCarthy, D., and Bond, F.:
“Lexsemtm: A semantic dataset based on all-words unsupervised
sense distribution learning.”, ACL, Vol. 1, pp. 1513—1524 (2016).
[13] Moro, A., and Navigli, R.: “Semeval-2015 task 13: Multilingual
all-words sense disambiguation and entity linking.”, SemEval, pp.
288—297 (2015).](https://image.slidesharecdn.com/clubert-200721002735/85/CluBERT-A-Cluster-Based-Approach-for-Learning-Sense-Distributions-in-Multiple-Languages-32-320.jpg)


![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]It's not just size that maters small language models are also few sho...](https://cdn.slidesharecdn.com/ss_thumbnails/itsnotjustsizethatmaterssmalllanguagemodelsarealsofew-shotlearners-210910034516-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL Hacks]Pretraining-Based Natural Language Generation for Text Summarizatio...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspretraining-basednaturallanguagegenerationfortextsummarization-190422070150-thumbnail.jpg?width=640&height=640&fit=bounds)










