背景・目的
関連研究
Information
Dataset Cartography: Mappingand Diagnosing
Datasets with Training Dynamics
Swayamdipta, S.1, Schwartz, R. 2, Lourie, N. 1,
Wang, Y. 3, Hajishirzi, H. 3, Smith, N. A. 3, & Choi, Y. 3
1: Allen Institute for Artificial Intelligence, Seattle
2: The Hebrew University of Jerusalem, Israel
3: Paul G. Allen School of Computer Science & Engineering, University of Washington, Seattle
https://arxiv.org/pdf/2009.10795.pdf
https://github.com/allenai/cartography
2
Allen AI は OSS の活動で有名
関連研究
提案手法
背景・目的
関連研究2
◆ Joshi ら[10]:AL-uncertainty
➢ 着目点: SVM (margin based model) における不確かさ
➢ 分析項目: active learning での効用
◆ Sener and Savarese ら[11]: AL-greedyK
➢ 着目点: データ集合の中における k 個の center (≈cluster)
と各 center のデータ集合全体への影響度
➢ 分析項目: active learning に効果的な部分集合
18
同様の視点から adversarial (データに誤りのある)シナリオでの
学習安定化・精度向上とも関連があるそう
19.
参考文献
まとめ
参考文献1
[1] Kailas Vodrahalli,Ke Li, and Jitendra Malik. 2018. Are all training
examples created equal? an empirical study. ArXiv:1811.12569.
[2] Dan Hendrycks, Xiaoyuan Liu, Eric Wallace, Adam Dziedzic, Rishabh
Krishnan, and Dawn Song. 2020. Pretrained transformers improve out-of-
distribution robustness. ArXiv preprint arXiv:2004.06100.
[3] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar S. Joshi, Danqi
Chen, Omer Levy, Mike Lewis, Luke S. Zettlemoyer, and Veselin Stoyanov.
2019. RoBERTa: A robustly optimized BERT pretraining approach.
ArXiv:1907.11692.
[4] Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D.
Manning. 2015. A large annotated corpus for learning natural language
inference. In Proceedings of the 2015 Conference on Empirical Methods in
Natural Language Processing, pages 632–642, Lisbon, Portugal.
Association for Computational Linguistics.
[5] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi.
2020. Winogrande: An adversarial winograd schema challenge at scale. In
AAAI.
19
20.
参考文献
まとめ
参考文献2
[6] Wei Hu,Zhiyuan Li, and Dingli Yu. 2020. Simple and effective
regularization methods for training on noisily labeled data with
generalization guarantee. In ICLR. OpenReview.net.
[7] Chen Xing, Devansh Arpit, Christos Tsirigotis, and Yoshua Bengio. 2018.
A walk with SGD.
[8] Mariya Toneva, Alessandro Sordoni, Remi Tachet des Combes, Adam
Trischler, Yoshua Bengio, and Geoffrey J Gordon. 2018. An empirical study
of example forgetting during deep neural network learning. In ICLR.
[9] Ronan LeBras, Swabha Swayamdipta, Chandra Bhagavatula, Rowan
Zellers, Matthew E. Peters, Ashish Sabharwal, and Yejin Choi. 2020.
Adversarial filters of dataset biases. In ICML.
[10] Ajay J Joshi, Fatih Porikli, and Nikolaos Papanikolopoulos. 2009. Multi-
class active learning for image classification. In CVPR, pages 2372– 2379.
IEEE.
[11] Ozan Sener and Silvio Savarese. 2018. Active learning for
convolutional neural networks: A core-set approach. In ICLR.
20



![背景・目的
関連研究
提案手法の目的
4
何を知りたいか
In- and Out-Of-Distribution (OOD) の関係や影響
◆サンプルは学習・予測に対して均一に貢献しない[1]
◆Pre-trained model は IOD, OOD の GAP を緩和[2]
Pre-trained model を用いたモデルベースの分析により
自動的に(容易に)モデル・データセットの両性質を把握
➢ 今回は NLP なので,ROBERTa を使用
BERT の Next Sentence Prediction なし
➢ Out-of-Distribution がかなり少ない
supervised な学習を挟んでおらずとも
関連した情報は含まれているはず](https://image.slidesharecdn.com/datasetcartographymappinganddiagnosingdatasetswithtrainingdynamicsslideshare-210830045934/85/Dataset-cartography-mapping-and-diagnosing-datasets-with-training-dynamics-4-320.jpg)



![提案手法
実験
関連研究
提案手法: Data Maps
あくまで相対的に見て
Easy-, Hard-to-Learn を定義
⇒ 結局,正解がわからん
8
※論文中では,appendix を含めて4つ
SNLI[3] の Data Map
残念な点:特にグループ化(閾値)の議論がない
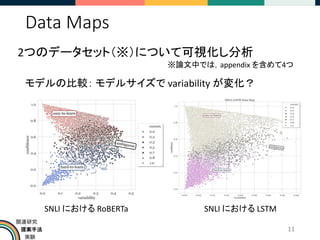
2つのデータセット(※)について可視化し分析
Confidence, variability に加え
学習過程での正解率を
plot することでグループを確認](https://image.slidesharecdn.com/datasetcartographymappinganddiagnosingdatasetswithtrainingdynamicsslideshare-210830045934/85/Dataset-cartography-mapping-and-diagnosing-datasets-with-training-dynamics-8-320.jpg)
![実験
まとめ
提案手法
実験設定
モデル
◆Bag-of-Words, eSim
◆LSTM, BERT, RoBERTa[3]
9
データセット In-, Out- の区切りも気になる所](https://image.slidesharecdn.com/datasetcartographymappinganddiagnosingdatasetswithtrainingdynamicsslideshare-210830045934/85/Dataset-cartography-mapping-and-diagnosing-datasets-with-training-dynamics-9-320.jpg)
![提案手法
実験
関連研究
Data Maps
2つのデータセット(※)について可視化し分析
10
※論文中では,appendix を含めて4つ
SNLI[4] の Data Map WinoGrande[5] の Data Map
データセットの比較: Hrad-to-Learn の密度が異なる](https://image.slidesharecdn.com/datasetcartographymappinganddiagnosingdatasetswithtrainingdynamicsslideshare-210830045934/85/Dataset-cartography-mapping-and-diagnosing-datasets-with-training-dynamics-10-320.jpg)



![実験
まとめ
提案手法
Detecting Mislabeled Examples
クラウドソースによるデータセットはミスラベルを含有
⇒ 誤ったラベルの学習は汎化性能を低下[]
15
実際に,1%のノイズを含めることで,学習が不安定に
安定していた instance の
評価も大きく変化
Confidence を特徴量としてミスラベルを検知(2値分類)
ノイズ率(1%, 4,039/49,399) ⇒ 13個をノイズと判定
ノイズ率(33%, 50/155) ⇒ 67%をノイズと判定
あまり意味のない実験に思うが](https://image.slidesharecdn.com/datasetcartographymappinganddiagnosingdatasetswithtrainingdynamicsslideshare-210830045934/85/Dataset-cartography-mapping-and-diagnosing-datasets-with-training-dynamics-15-320.jpg)

![関連研究
提案手法
背景・目的
関連研究1
◆ Xing ら[7]
➢ 着目点: SGD による最適化の loss の軌跡
➢ 分析項目: バッチサイズに起因するノイズ
◆ Toneva ら[8]: forgetting
➢ 着目点: 数 epoch 後に忘れられる ‘forgotten’ instance
➢ 分析項目: training set に含む instance の影響
◆ LeBras ら[9]: AFLite
➢ 着目点: 単純な分類器の ensemble による予測可能性
➢ 分析項目: dataset がもつ bias によるモデルの過大評価
17
LeBras らやその他の研究ではEasy-to-Learn は除くべきと主張
WinoGrande[5] で始めて提案](https://image.slidesharecdn.com/datasetcartographymappinganddiagnosingdatasetswithtrainingdynamicsslideshare-210830045934/85/Dataset-cartography-mapping-and-diagnosing-datasets-with-training-dynamics-17-320.jpg)
![関連研究
提案手法
背景・目的
関連研究2
◆ Joshi ら[10]: AL-uncertainty
➢ 着目点: SVM (margin based model) における不確かさ
➢ 分析項目: active learning での効用
◆ Sener and Savarese ら[11]: AL-greedyK
➢ 着目点: データ集合の中における k 個の center (≈cluster)
と各 center のデータ集合全体への影響度
➢ 分析項目: active learning に効果的な部分集合
18
同様の視点から adversarial (データに誤りのある)シナリオでの
学習安定化・精度向上とも関連があるそう](https://image.slidesharecdn.com/datasetcartographymappinganddiagnosingdatasetswithtrainingdynamicsslideshare-210830045934/85/Dataset-cartography-mapping-and-diagnosing-datasets-with-training-dynamics-18-320.jpg)
![参考文献
まとめ
参考文献1
[1] Kailas Vodrahalli, Ke Li, and Jitendra Malik. 2018. Are all training
examples created equal? an empirical study. ArXiv:1811.12569.
[2] Dan Hendrycks, Xiaoyuan Liu, Eric Wallace, Adam Dziedzic, Rishabh
Krishnan, and Dawn Song. 2020. Pretrained transformers improve out-of-
distribution robustness. ArXiv preprint arXiv:2004.06100.
[3] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar S. Joshi, Danqi
Chen, Omer Levy, Mike Lewis, Luke S. Zettlemoyer, and Veselin Stoyanov.
2019. RoBERTa: A robustly optimized BERT pretraining approach.
ArXiv:1907.11692.
[4] Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D.
Manning. 2015. A large annotated corpus for learning natural language
inference. In Proceedings of the 2015 Conference on Empirical Methods in
Natural Language Processing, pages 632–642, Lisbon, Portugal.
Association for Computational Linguistics.
[5] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi.
2020. Winogrande: An adversarial winograd schema challenge at scale. In
AAAI.
19](https://image.slidesharecdn.com/datasetcartographymappinganddiagnosingdatasetswithtrainingdynamicsslideshare-210830045934/85/Dataset-cartography-mapping-and-diagnosing-datasets-with-training-dynamics-19-320.jpg)
![参考文献
まとめ
参考文献2
[6] Wei Hu, Zhiyuan Li, and Dingli Yu. 2020. Simple and effective
regularization methods for training on noisily labeled data with
generalization guarantee. In ICLR. OpenReview.net.
[7] Chen Xing, Devansh Arpit, Christos Tsirigotis, and Yoshua Bengio. 2018.
A walk with SGD.
[8] Mariya Toneva, Alessandro Sordoni, Remi Tachet des Combes, Adam
Trischler, Yoshua Bengio, and Geoffrey J Gordon. 2018. An empirical study
of example forgetting during deep neural network learning. In ICLR.
[9] Ronan LeBras, Swabha Swayamdipta, Chandra Bhagavatula, Rowan
Zellers, Matthew E. Peters, Ashish Sabharwal, and Yejin Choi. 2020.
Adversarial filters of dataset biases. In ICML.
[10] Ajay J Joshi, Fatih Porikli, and Nikolaos Papanikolopoulos. 2009. Multi-
class active learning for image classification. In CVPR, pages 2372– 2379.
IEEE.
[11] Ozan Sener and Silvio Savarese. 2018. Active learning for
convolutional neural networks: A core-set approach. In ICLR.
20](https://image.slidesharecdn.com/datasetcartographymappinganddiagnosingdatasetswithtrainingdynamicsslideshare-210830045934/85/Dataset-cartography-mapping-and-diagnosing-datasets-with-training-dynamics-20-320.jpg)



![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Policy Information Capacity: Information-Theoretic Measure for Task Co...](https://cdn.slidesharecdn.com/ss_thumbnails/20210430furuta-210430023728-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)















![[NeurIPS2019 論文読み会] A Meta Analysis of Overfitting in Machine Learning](https://cdn.slidesharecdn.com/ss_thumbnails/ametaanalysisofoverfittinginmachinelearning-200131084459-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)







