More Related Content

PDF
Transformerを多層にする際の勾配消失問題と解決法について 
PDF

PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料 
PDF
三次元点群を取り扱うニューラルネットワークのサーベイ 
PDF

PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化 
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ ![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
What's hot

PPTX
近年のHierarchical Vision Transformer ![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向 ![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Understanding Black-box Predictions via Influence Functions ![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,... 
PPTX

PPTX
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021) 
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces 
PDF
最近のディープラーニングのトレンド紹介_20200925 ![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling ![[DL輪読会]Wav2CLIP: Learning Robust Audio Representations From CLIP](https://cdn.slidesharecdn.com/ss_thumbnails/dlwav2clip1-211105022837-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Wav2CLIP: Learning Robust Audio Representations From CLIP 
PDF
Contrastive learning 20200607 
PDF
![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP) ![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder 
PDF
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait... 
PDF
BlackBox モデルの説明性・解釈性技術の実装 ![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会] マルチエージェント強化学習と心の理論 ![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und... 
PPTX
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models 
PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料) Similar to Transformerを用いたAutoEncoderの設計と実験

PDF

PDF
attention_is_all_you_need_nips17_論文紹介 
PDF
【DeepLearning研修】Transformerの基礎と応用 -- 第1回 Transformerの基本 
PDF

PDF
Transformerについて解説!!(Encoder部分) ![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜 
PDF
transformer解説~Chat-GPTの源流~ 
PDF
PythonによるDeep Learningの実装 
PPTX

PDF
Learning Deep Architectures for AI (第 3 回 Deep Learning 勉強会資料; 松尾) ![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S... 
PDF
文献紹介:Length-Controllable Image Captioning 
PDF

PDF

PDF
【DeepLearning研修】Transfomerの基礎と応用 --第4回 マルチモーダルへの展開 
PDF
【DL輪読会】ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders 
PPTX

PPTX
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」 
PDF

PDF
DL Hacks輪読 Semi-supervised Learning with Deep Generative Models Recently uploaded

PDF
krsk_aws_re-growth_aws_devops_agent_20251211 
PDF
音楽アーティスト探索体験に特化した音楽ディスカバリーWebサービス「DigLoop」|Created byヨハク技研 
PPTX
君をむしばむこの力で_最終発表-1-Monthon2025最終発表用資料-.pptx 
PDF
2025/12/12 AutoDevNinjaピッチ資料 - 大人な男のAuto Dev環境 
PDF
ソフトウェアエンジニアがクルマのコアを創る!? モビリティの価値を最大化するソフトウェア開発の最前線【DENSO Tech Night 第一夜】 
PDF
ソフトとハードの二刀流で実現する先進安全・自動運転のアルゴリズム開発【DENSO Tech Night 第二夜】 ー高精度な画像解析 / AI推論モデル ... Transformerを用いたAutoEncoderの設計と実験
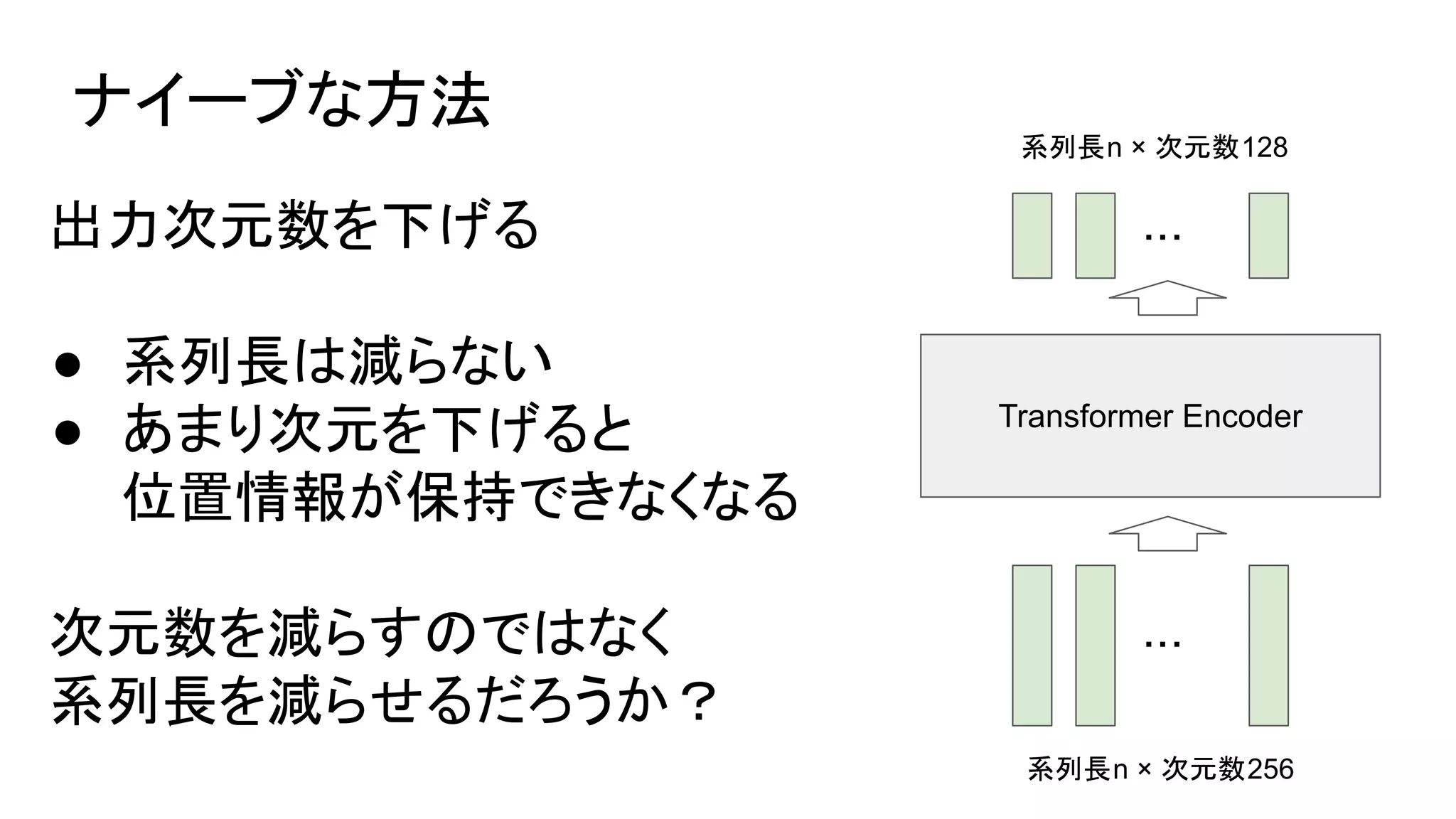
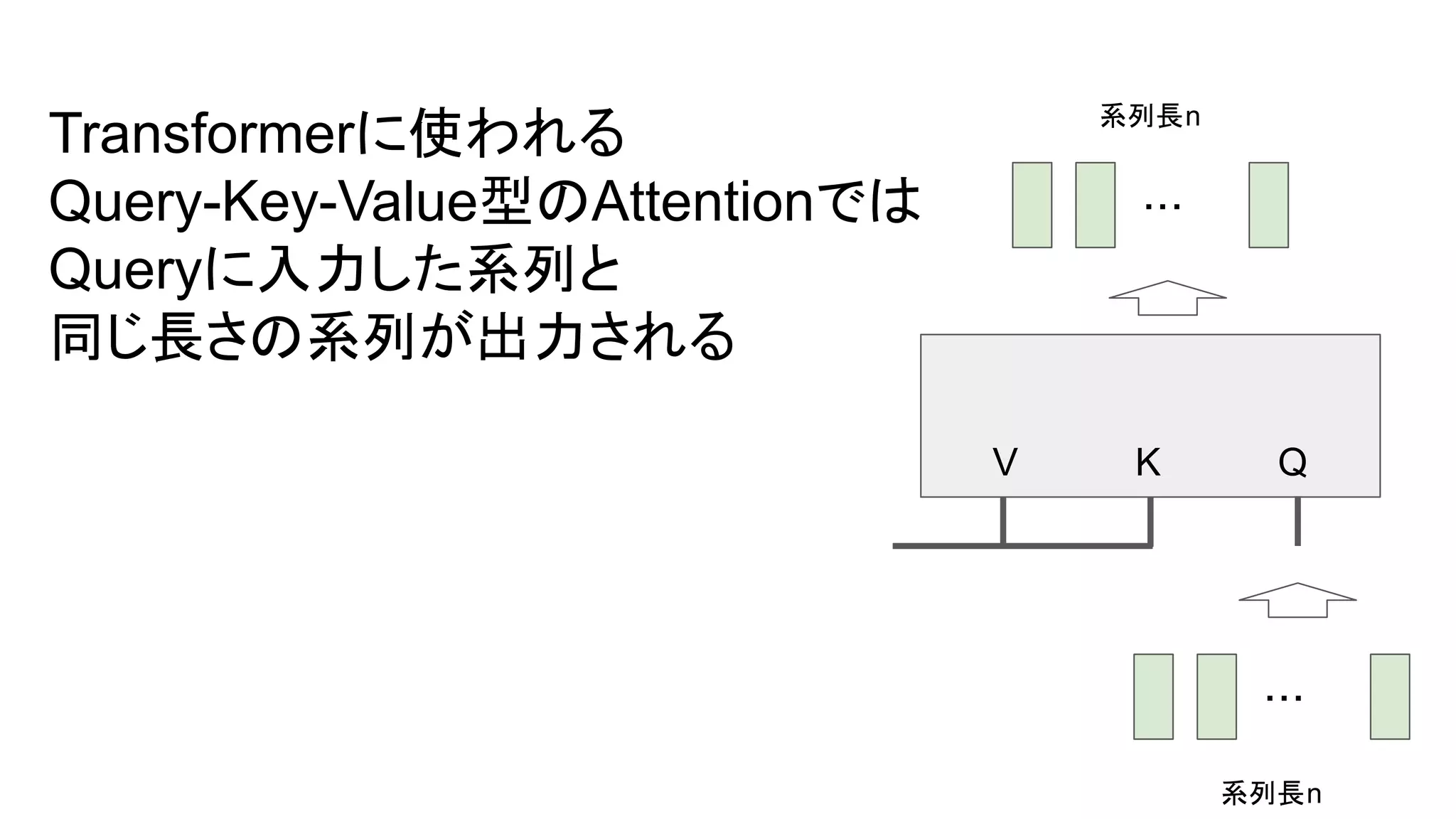
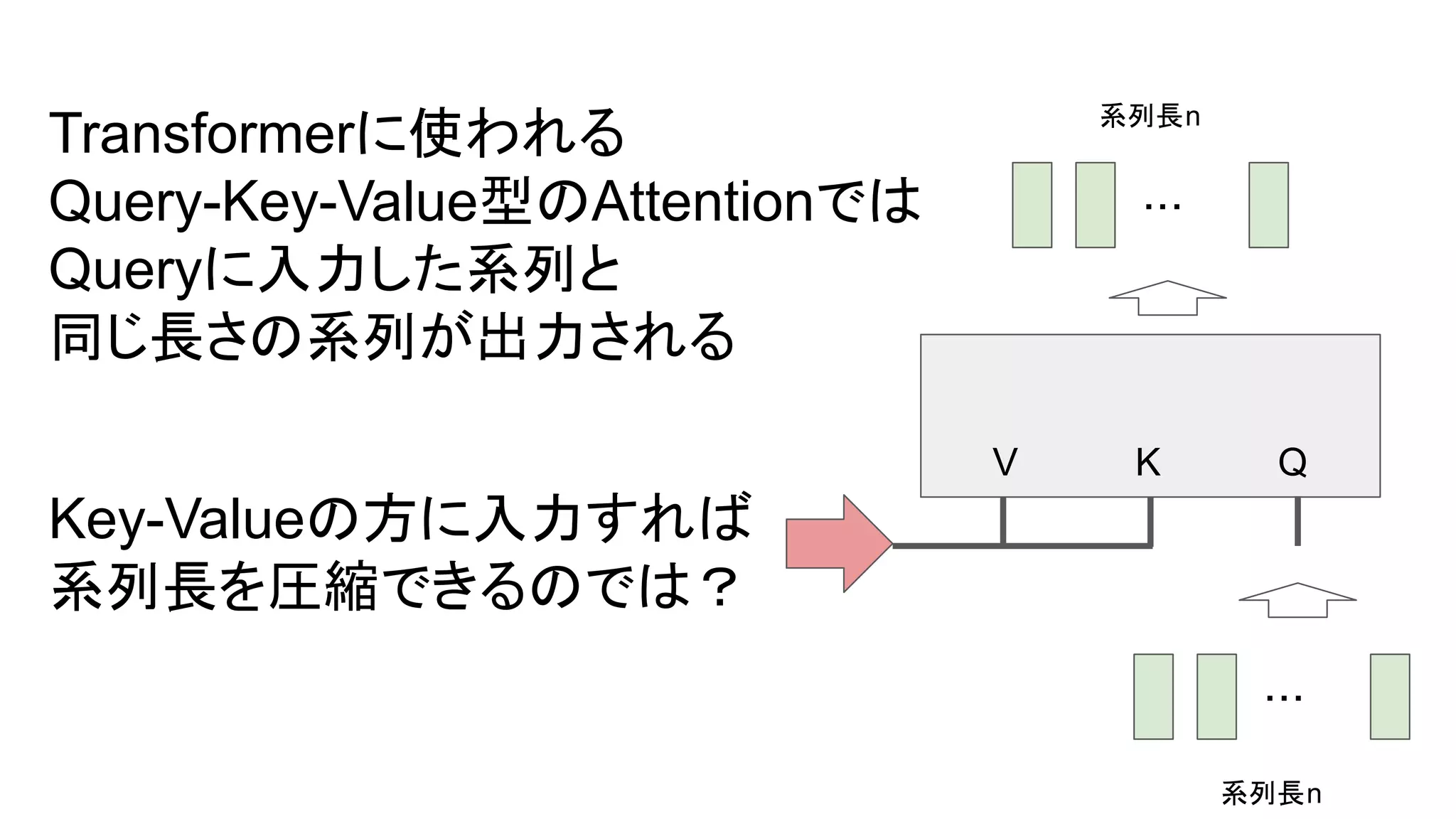
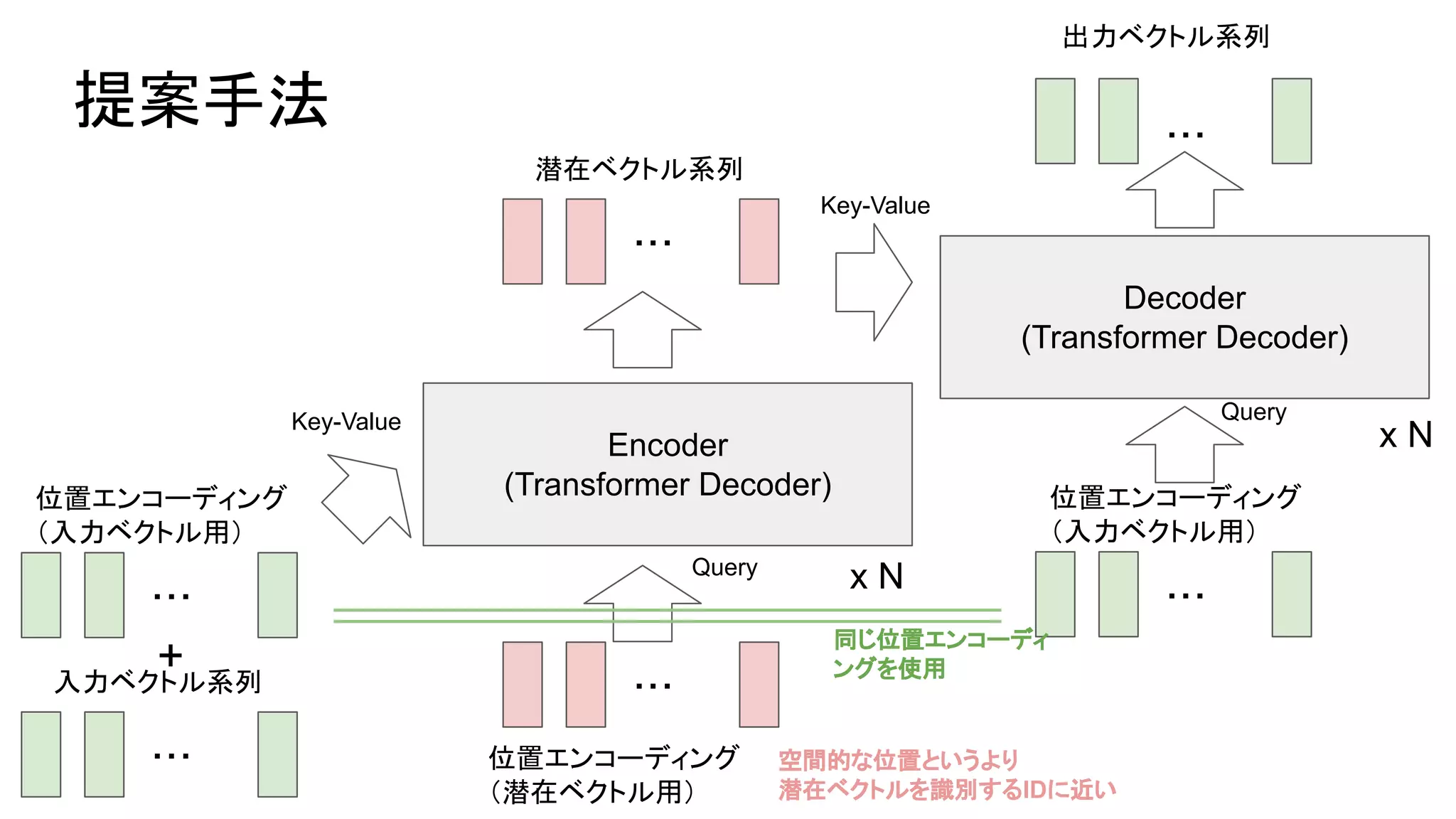
- 1.
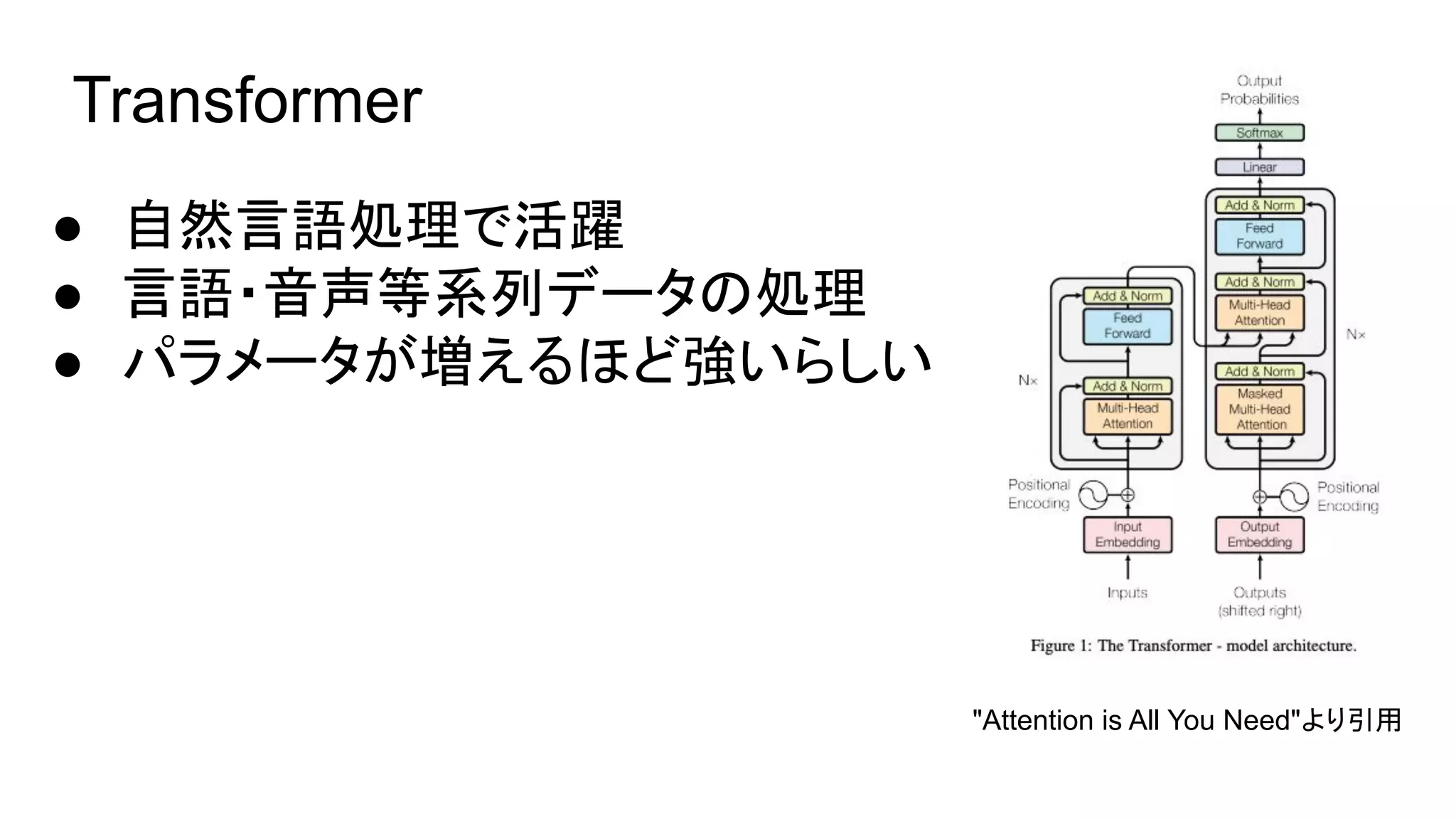
- 2.
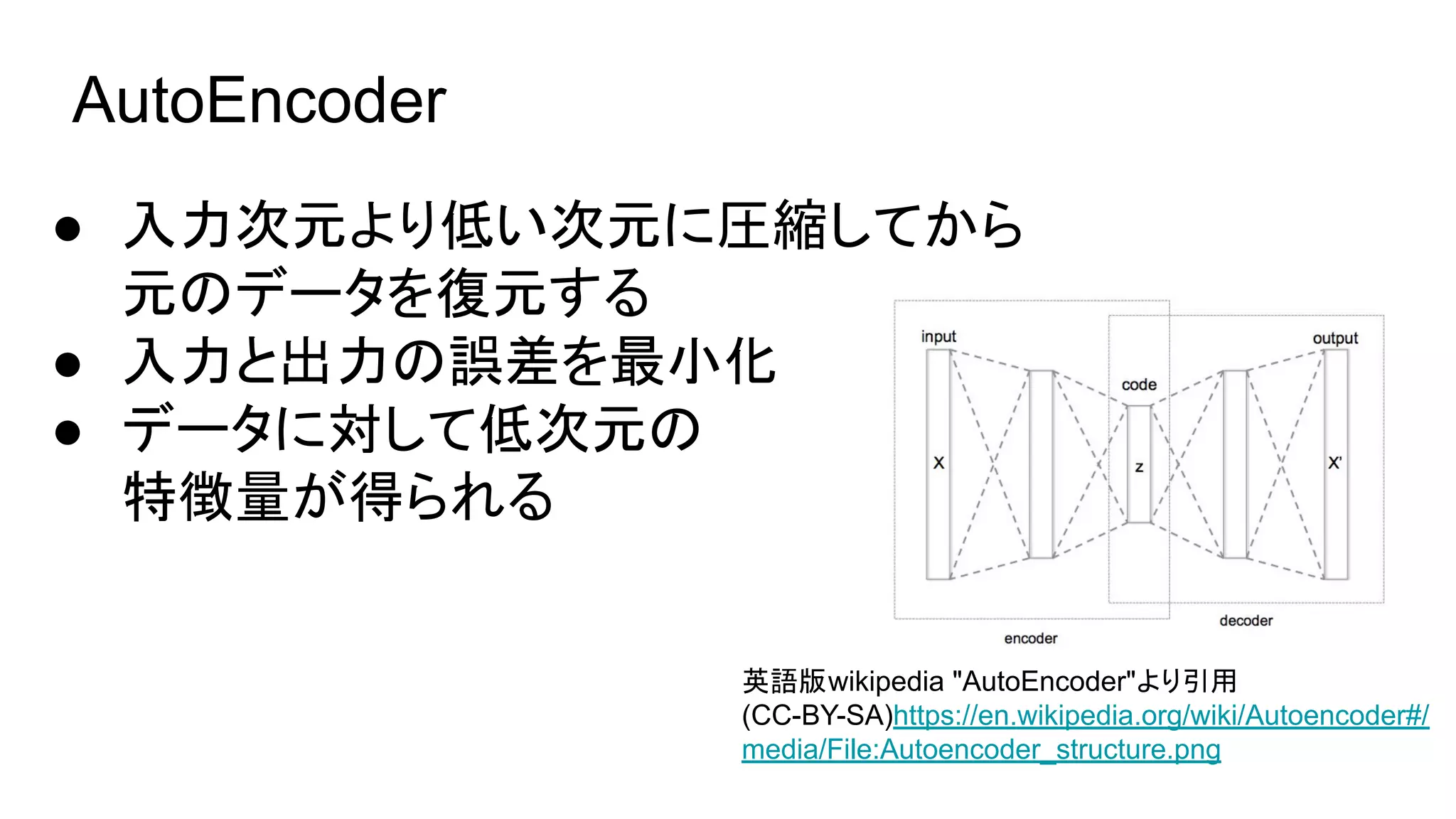
- 3.
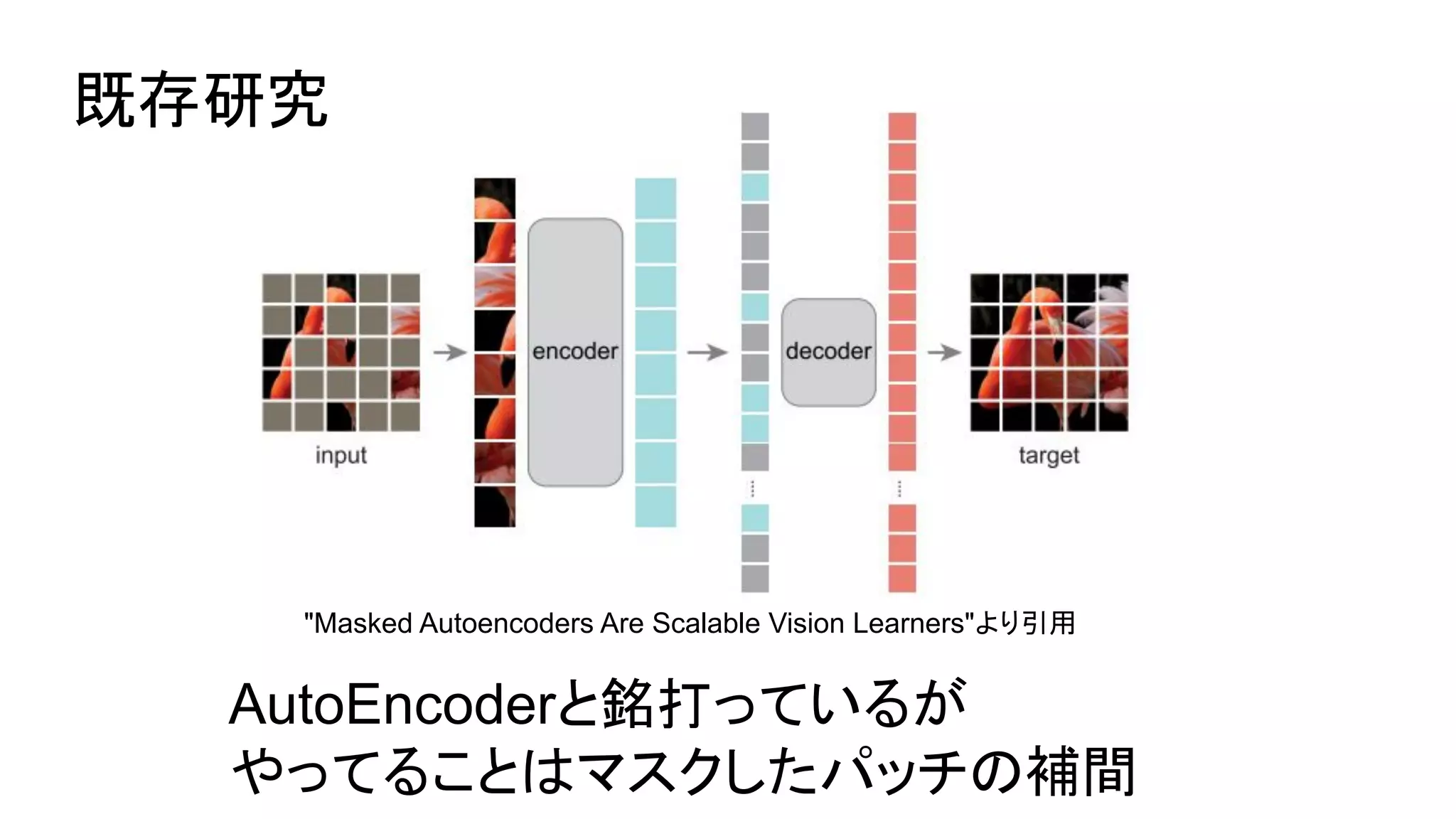
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.