More Related Content

PDF

PDF

PPTX

PDF

PDF

PPTX

PPTX

PDF
What's hot

PDF
PRML ベイズロジスティック回帰 4.5 4.5.2 
PDF

PDF

PDF

PDF

PDF

PDF

PPTX

PPTX
![[PRML] パターン認識と機械学習(第2章:確率分布)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter2-171002030018-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[PRML] パターン認識と機械学習(第2章:確率分布) 
PPTX

PDF

PDF

PDF

PDF

PPTX

PPTX
パターン認識と機械学習(PRML)第2章 確率分布 2.3 ガウス分布 
PDF
Prml4.4 ラプラス近似~ベイズロジスティック回帰 
PDF

PDF
Similar to PRML 5.5.6-5.6 畳み込みネットワーク(CNN)・ソフト重み共有・混合密度ネットワーク

PDF

PPTX

PPTX

PDF
![[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190621dlhack-190621022108-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 
PDF
CVPR2018のPointCloudのCNN論文とSPLATNet 
PDF
Convolutional Neural Networks のトレンド @WBAFLカジュアルトーク#2 
PPTX

PPT

PDF

PDF
Deep residual learning for image recognition 
PPTX
Image net classification with Deep Convolutional Neural Networks 
PDF
Convolutional Neural Network @ CV勉強会関東 
PDF
NN, CNN, and Image Analysis 
PDF
SAS Viyaのディープラーニングを用いた物体検出 
PDF

PDF
2014/5/29 東大相澤山崎研勉強会:パターン認識とニューラルネットワーク,Deep Learningまで 
PPTX

PDF
画像認識モデルを自動的に作る。1日以内に。~Simple And Efficient Architecture Search for Convolutio... 
PPTX
PRML 5.5.6-5.6 畳み込みネットワーク(CNN)・ソフト重み共有・混合密度ネットワーク
- 1.
- 2.
- 3.
アブストラクト
5.5.6
入力の変換(平行移動, 回転など)に対して, 出力が不変であるためのアプローチの
一つである,たたみ込みニューラルネットワーク(CNN)を紹介する. CNNは入力に対
して, フィルタによるたたみ込み, 一部の数値を取り出す, といった処理を行うことで特
徴を抽出し, 結果を出力する手法である.
5.5.7
ネットワークの有効な複雑さを削減するために, ソフト重み共有という正則化項を導入
する. ソフト重み共有では, 重みに対して混合分布を導入し, 平均や分散などのパラ
メータをグループ毎に学習する. この際, 一つの分布の平均を0にし, 不要な重みを見
つけ出す. これをカットすることでネットワークを軽量化する.
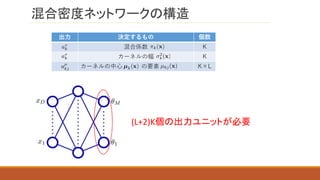
5.6
多峰性を持つ問題に対応するために, データの分布として,
混合分布を仮定する, 混合密度ネットワークについて紹介する.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
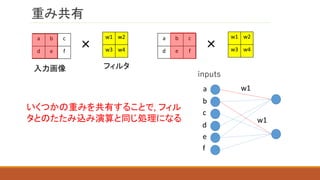
たたみ込み演算による特徴抽出
0 1 1
11 0
1 0 0
入力画像
×
0 1
1 0
2 2
2 0
フィルタ
この値を活性化関数で変
換したものが, たたみ込み
層の出力となる
特徴マップ
(たたみ込み層の入力)
- 12.
平行移動と歪みに対しての不変性
0 1 1
11 0
1 0 0
入力画像
×
0 1
1 0
2 2
2 0
フィルタ 特徴マップ
0 0 0
1 1 1
1 1 0
入力画像を平行
移動したもの
×
0 1
1 0
2 1
2 2
フィルタ 特徴マップ
の部分を全て
1マス下に移動
特徴マップの該当部
分も1マス下に移動
⇒平行移動と歪みに
対しての不変性
- 13.
複数の特徴を抽出する場合
0 1 1
11 0
1 0 0
0 1
1 0
0 1 1
1 1 0
1 0 0
入力画像
×
0 1
1 0
2 2
2 0
フィルタ1
別の特徴を抽出するためには別のフィルタを利用する
0 0
1 1
0 1 1
1 1 0
1 0 0
入力画像
×
2 1
1 0
フィルタ2
0 0
1 1
入力画像
フィルタ2フィルタ1 特徴マップ2
(たたみ込み層の入力)
特徴マップ1
(たたみ込み層の入力)
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
なぜ学習が失敗したのか
0 1
𝑥1 +𝑥2
2
𝑥1
𝑥1
𝑥2
𝑥2
𝑥1 + 𝑥2
2
t1
ここでは単純化のため, での期待値を とするt1
𝑥1 + 𝑥2
2
多峰性を持つ場合, 条件付き平均は解として不適
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
Editor's Notes
- #9 ゼロパティングなど
- #10 ゼロパティングなど
- #11 ゼロパティングなど
- #12 ゼロパティングなど
- #13 ゼロパティングなど
- #14 ゼロパティングなど
- #16 ゼロパティングなど
- #19 左図のようになっている理由は, そのほうがプログラムが書きやすいからだと思われる.