Download as PDF, PPTX


![◼
•
• (bbox)
•
• bbox
◼
• DPM [Yan+, CVPR2011]
• R-CNN [Girshick+, CVPR2014]
• YOLO [Redmon+, CVPR2016]
• SSD [Liu+, arXiv2017]
• EfficientDet [Tan+, CVPR2020]
• DeiT [Touvron+, arXiv2020]
dog
bicycle
[Joseph+, CVPR2016]](https://image.slidesharecdn.com/20220617youonlylookonceseries-220630005006-3c48dfe1/85/YOLO-series-v1-v5-X-F-and-YOWO-2-320.jpg)
![YOLOv1 [Redmon+, CVPR2016]
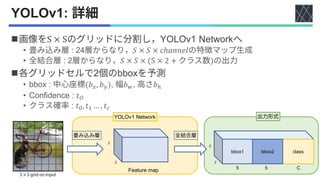
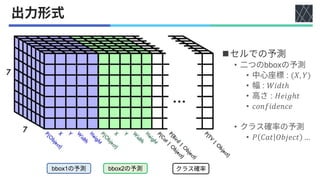
◼1
•
• :
• :
◼2
• DPM
• R-CNN
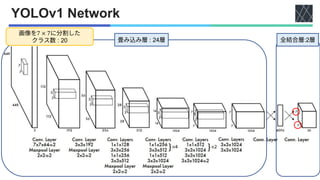
◼YOLOv1
•
•
•](https://image.slidesharecdn.com/20220617youonlylookonceseries-220630005006-3c48dfe1/85/YOLO-series-v1-v5-X-F-and-YOWO-3-320.jpg)
![YOLOv2 [Redmon&Farhadi, CVPR2017]
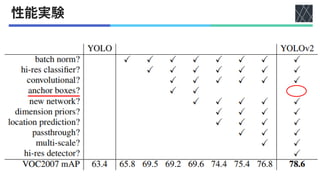
◼YOLOv1
•
•
• 448 × 448
•
• 5
•
• K-means (𝑘 = 5)
•
• bbox
•
•
•
•](https://image.slidesharecdn.com/20220617youonlylookonceseries-220630005006-3c48dfe1/85/YOLO-series-v1-v5-X-F-and-YOWO-7-320.jpg)
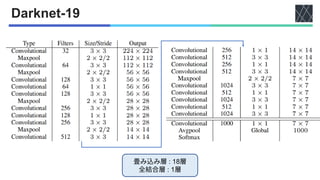
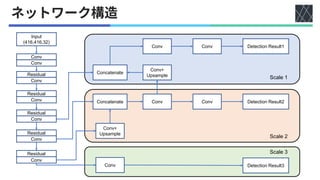
![YOLOv3 [Redmon&Farhadi, arXiv2018]
◼YOLOv2
• FPN
•
•
• v2
◼FPN [Lin+, CVPR2017]
•
(YOLOv3: 3 )
•
• bbox, confidence,
◼YOLOv3
•
YOLOv2
YOLOv3
Single feature map
Feature Pyramid Network](https://image.slidesharecdn.com/20220617youonlylookonceseries-220630005006-3c48dfe1/85/YOLO-series-v1-v5-X-F-and-YOWO-10-320.jpg)

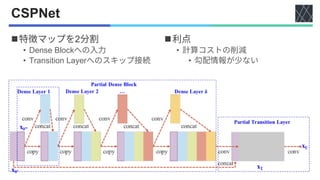
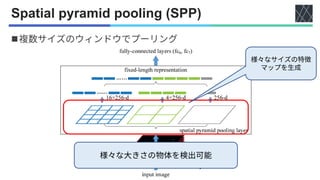
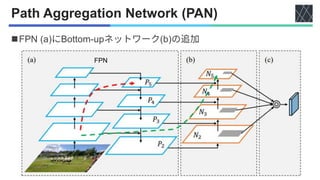
![YOLOv4 [Bochkovskiy+, arXiv2020]
◼Backbone
• CSPNet [Wang+, CVPR2020]
◼Head
• YOLOv3
◼Neck
• Spatial Pyramid Pooling (SPP)
[He+, TPAMI2015]
• Path Aggregation Network (PAN)
[Liu+, CVPR2018]](https://image.slidesharecdn.com/20220617youonlylookonceseries-220630005006-3c48dfe1/85/YOLO-series-v1-v5-X-F-and-YOWO-12-320.jpg)
![YOLOv5 YOWO
◼YOLOv5 [Glenn, GitHub2020]
• YOLOv4
•
•
• YOLOv4 : C
• YOLOv5 : Python
◼YOWO [Köpüklü+, arXiv2021]
• You Only Watch Once
•](https://image.slidesharecdn.com/20220617youonlylookonceseries-220630005006-3c48dfe1/85/YOLO-series-v1-v5-X-F-and-YOWO-16-320.jpg)
![YOLOX
◼YOLOX: Exceeding YOLO Series in 2021 [Ge+, arXiv2021]
◼YOLOv3~v5
• P(Obj)
◼YOLOX
•
• 1anchor box/anchor
• Multi positives
• positive
• bbox
positive
V3~v5](https://image.slidesharecdn.com/20220617youonlylookonceseries-220630005006-3c48dfe1/85/YOLO-series-v1-v5-X-F-and-YOWO-17-320.jpg)
![YOLOF
◼You Only Look One-level Feature [Chen+, CVPR2021]
•
•
•
•Single in Single out](https://image.slidesharecdn.com/20220617youonlylookonceseries-220630005006-3c48dfe1/85/YOLO-series-v1-v5-X-F-and-YOWO-18-320.jpg)

![◼You Only Look Once: Unified, Real-Time Object Detection
[Redom+, CVPR2016]
◼YOLO9000: Better, Faster, Stronger [Redmon+, CVPR2017]
◼YOLOv3: An Incremental Improvement [Redmon+, arXiv2018]
◼YOLOv4: Optimal Speed and Accuracy of Object Detection
[Bochkovskiy+, arXiv2020]
◼You Only Watch Once [Köpüklü+, arXiv2021]
◼YOLOX: Exceeding YOLO Series in 2021 [Ge+, arXiv2021]
◼You Only Look One-level Feature [Chen+, CVPR2021]](https://image.slidesharecdn.com/20220617youonlylookonceseries-220630005006-3c48dfe1/85/YOLO-series-v1-v5-X-F-and-YOWO-20-320.jpg)

20220617_You_Only_Look_Once_Series.pdf You Only Look Once: Unified, Real-Time Object Detection https://www.cv-foundation.org/openaccess/content_cvpr_2016/html/Redmon_You_Only_Look_CVPR_2016_paper.html YOLO9000: Better, Faster, Stronger https://openaccess.thecvf.com/content_cvpr_2017/html/Redmon_YOLO9000_Better_Faster_CVPR_2017_paper.html YOLOv3: An Incremental Improvement https://arxiv.org/abs/1804.02767 YOLOv4: Optimal Speed and Accuracy of Object Detection https://arxiv.org/abs/2004.10934 YOLOv5 https://github.com/ultralytics/yolov5 YOLOX: Exceeding YOLO Series in 2021 https://arxiv.org/abs/2107.08430 You Only Look One-Level Feature https://openaccess.thecvf.com/content/CVPR2021/html/Chen_You_Only_Look_One-Level_Feature_CVPR_2021_paper.html You Only Watch Once: A Unified CNN Architecture for Real-Time Spatiotemporal Action Localization https://openaccess.thecvf.com/content/ICCV2021/html/Chen_Watch_Only_Once_An_End-to-End_Video_Action_Detection_Framework_ICCV_2021_paper.html

![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Object-Centric Learning with Slot Attention](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0717-200717023021-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)






















