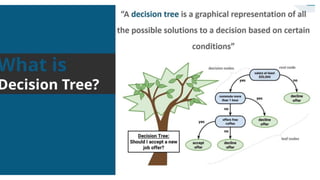
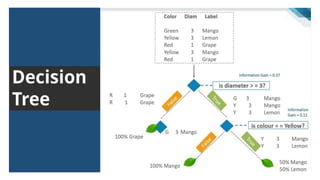
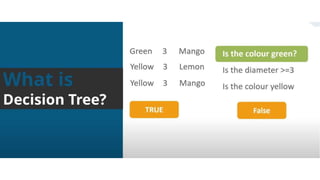
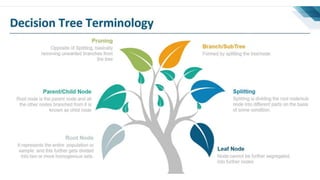
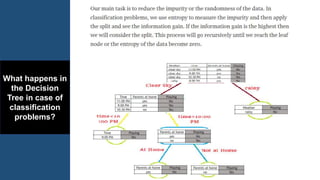
The document summarizes key concepts related to decision trees for classification and regression problems. It defines common terminology like entropy, information gain, and gini impurity used in decision trees for classification. It also discusses the process of how decision trees handle classification and regression problems. The advantages of decision trees are provided as being simple to understand, needing little data preprocessing, and able to handle both regression and classification. Overfitting and instability when new data is added are identified as disadvantages that can be addressed through techniques like tree pruning and using random forests.






















![XGBOOST [Autosaved]12.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/xgboostautosaved12-230501140101-a562c3ba-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[Women in Data Science Meetup ATX] Decision Trees](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontrees-161118165341-thumbnail.jpg?width=640&height=640&fit=bounds)













































