

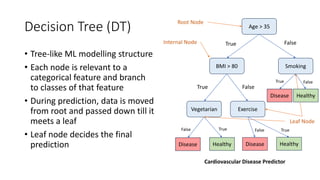






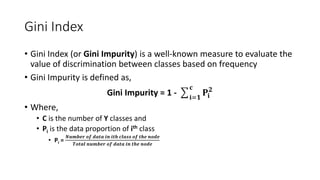

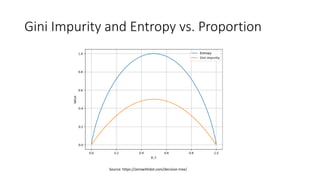
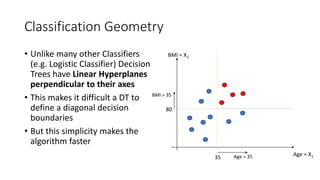





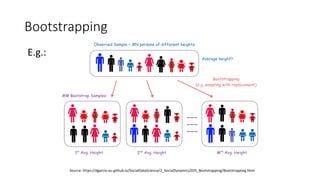


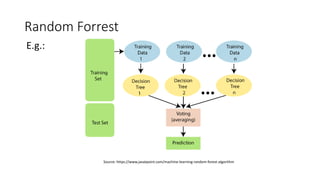


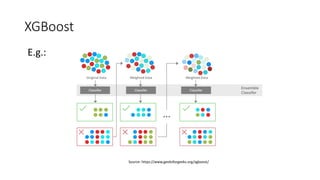





The document discusses decision trees and ensemble methods in statistical and machine learning, explaining the structure and functioning of decision trees, including their optimization and algorithms like CART. It details various measures for evaluating impurity, such as Gini index and entropy, along with regularization techniques to control overfitting. Additionally, it covers ensemble methods like bagging and boosting, including specific algorithms such as Random Forest and XGBoost, highlighting their advantages and disadvantages in machine learning applications.




























![[Women in Data Science Meetup ATX] Decision Trees](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontrees-161118165341-thumbnail.jpg?width=640&height=640&fit=bounds)


























































