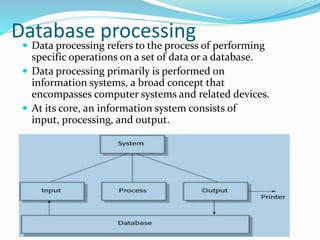
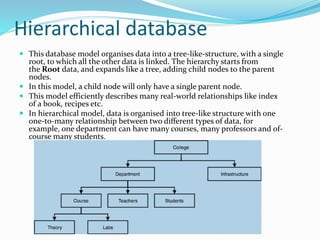
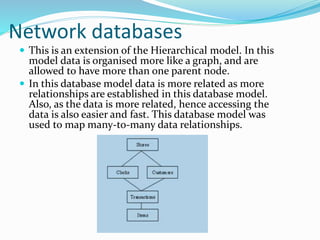
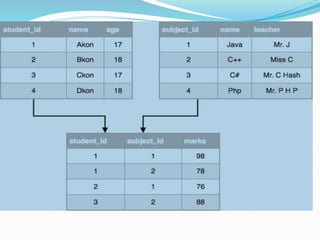
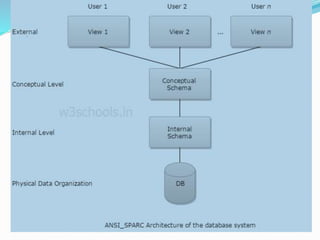
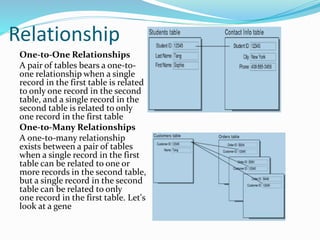
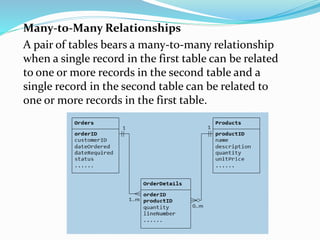
This document discusses concepts related to data processing and databases. It begins with definitions of data processing and how it converts raw data into usable information. It then discusses the differences between data and information. The rest of the document covers database concepts like file processing, database management systems, database design principles like normalization, and different database models.