Download to read offline














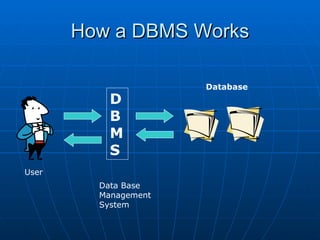




















The document provides an overview of information systems and databases as covered in the HSC course. It discusses different types of information systems and focuses on organizing, storing, and retrieving data with database systems. It describes skills needed to analyze database information systems and provides examples to practice these skills. Finally, it covers topics like database design, data storage and retrieval methods, and some social and ethical issues related to information systems.






















































































