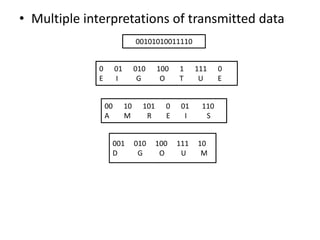
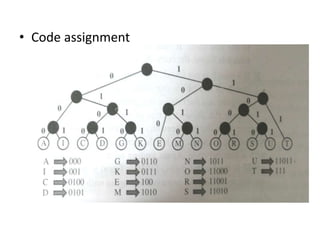
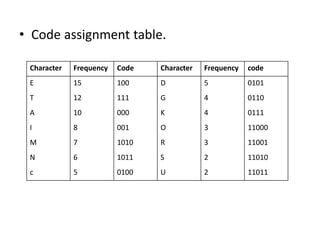
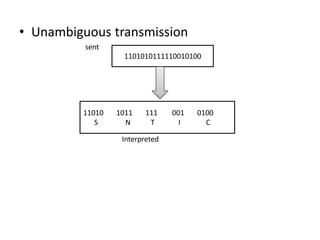
The document provides an overview of the Huffman algorithm, a method for lossless data compression that assigns variable-length codes to characters based on their frequency of occurrence. It explains how shorter codes are given to more frequent characters to optimize encoding efficiency and illustrates the construction of a Huffman tree for code assignment. The process of decoding messages encoded with Huffman coding is also described to ensure unambiguous transmission.