Download to read offline


















![Step2: Build Huffman Tree& AssignCodes
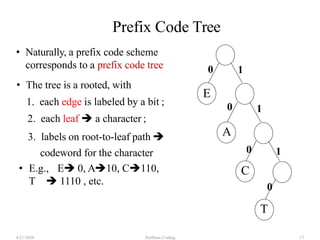
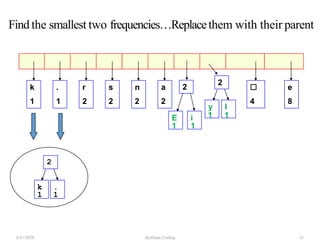
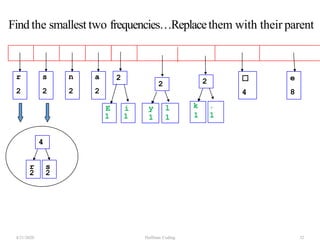
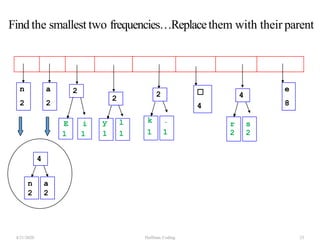
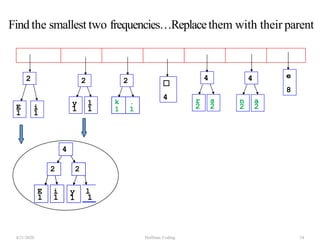
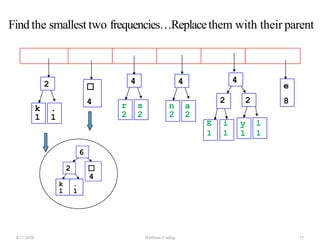
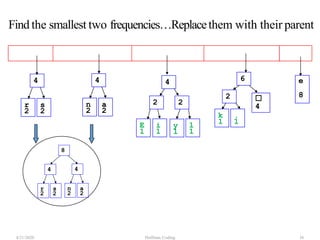
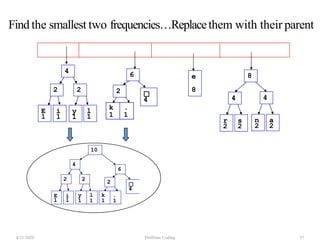
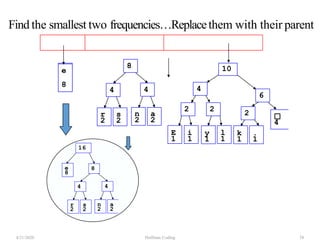
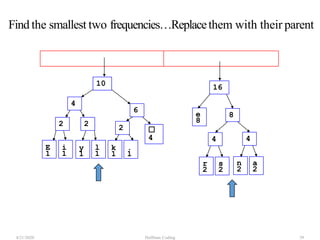
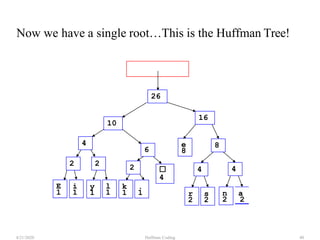
• It is a binary tree in which each character is a leaf node
• Initially each node is a separate root
• At each step
• Select two roots with smallest frequency and connect
them to a new parent (Break ties arbitrary) [The greedy
choice]
• The parent will get the sum of frequencies of the two
child nodes
• Repeat until you have one root
4/21/2020 Huffman Coding 27](https://image.slidesharecdn.com/farhanashaikhwebinarhuffmancoding-200421094201/85/Farhana-shaikh-webinar_huffman-coding-27-320.jpg)
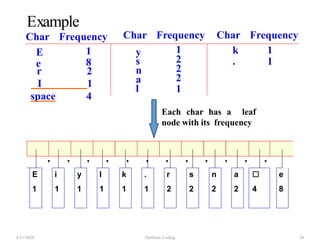
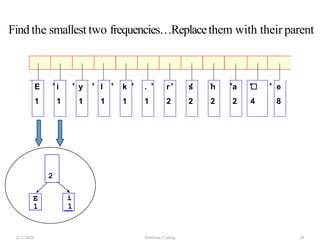
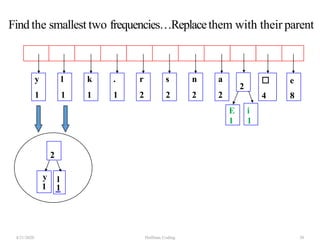
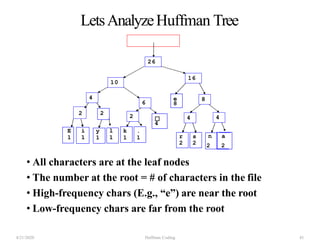
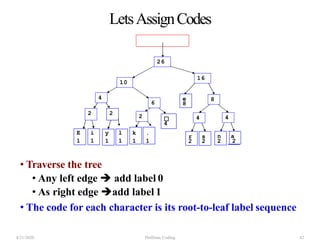
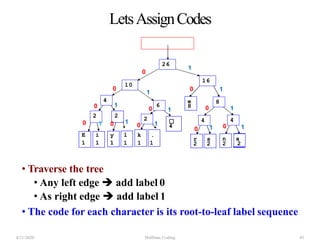
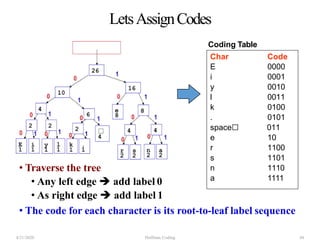


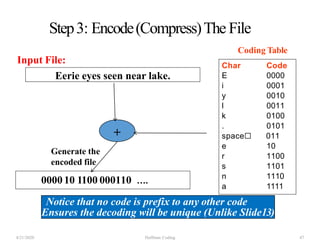

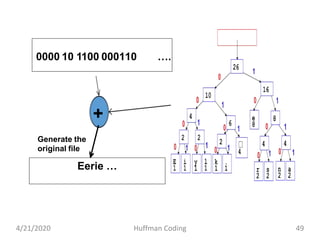



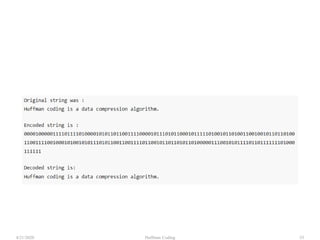

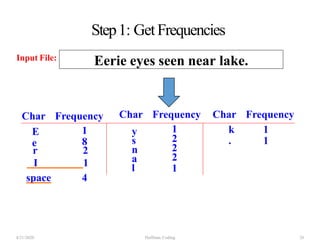
The document discusses Huffman coding, which is a lossless data compression algorithm that uses variable-length codes to encode characters based on their frequency of occurrence. It involves building a Huffman tree by iteratively combining the two lowest frequency nodes and assigning codes to characters based on their paths in the tree. The algorithm is described in 4 steps - getting character frequencies, building the Huffman tree and assigning codes, encoding the data, and decoding the compressed data. Examples are provided to illustrate how the Huffman tree is constructed bottom-up and codes are assigned.



































































