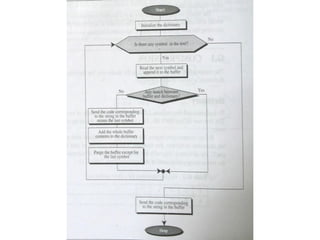
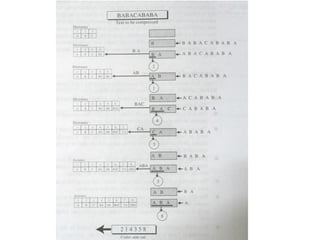
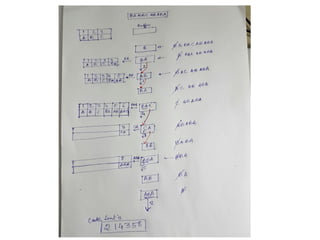
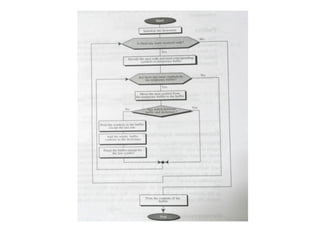
The document provides an overview of the LZW (Lempel-Ziv-Welch) compression method, detailing its lossless compression capabilities and the evolution from the initial Lempel-Ziv method. It explains the components of the compression process, including the use of a dictionary, buffer, and algorithm, and outlines how the decompression process mirrors compression without the need to send the dictionary. A practical example is given, demonstrating the transformation of the input text 'babacababa' into its compressed form '214358'.