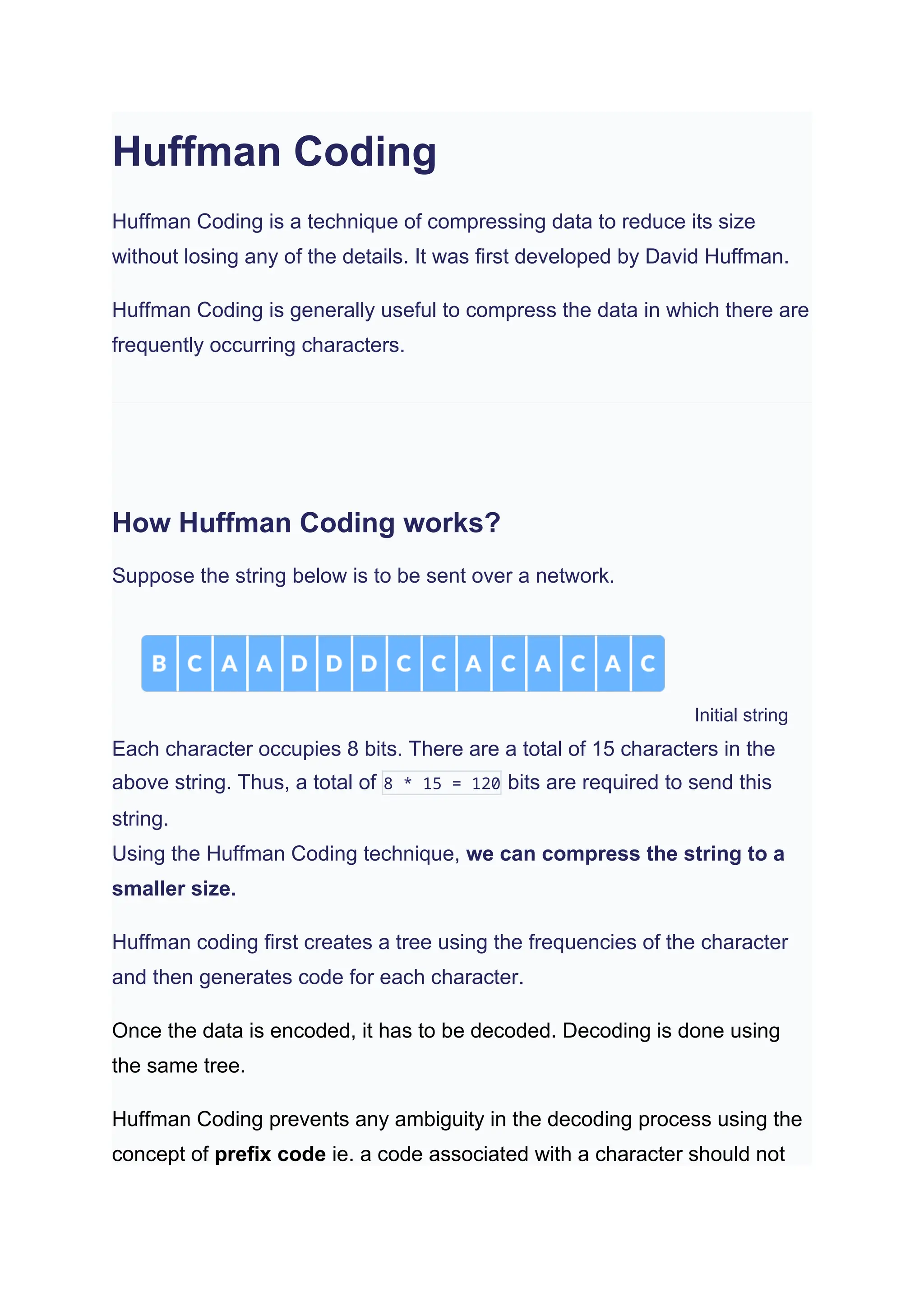
Huffman coding is a data compression technique that reduces file size without losing information, developed by David Huffman. It works by creating a binary tree based on the frequency of characters, allowing for efficient encoding and decoding of data. This method is widely used in compression formats such as gzip and is characterized by its time complexity of O(n log n).