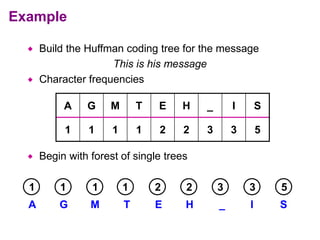
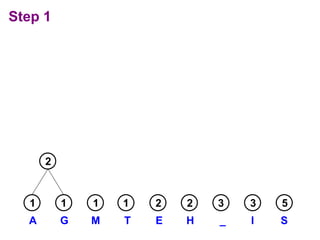
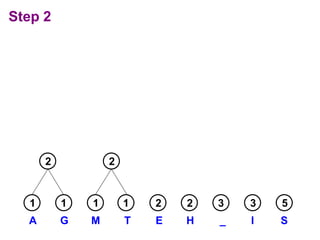
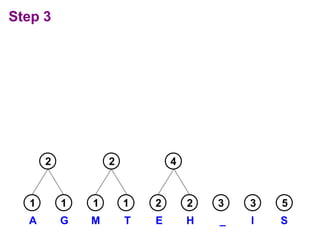
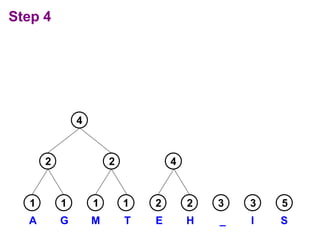
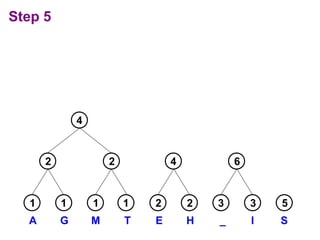
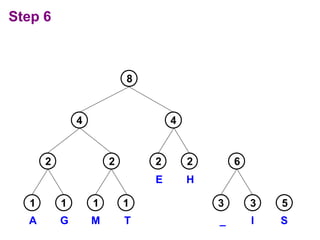
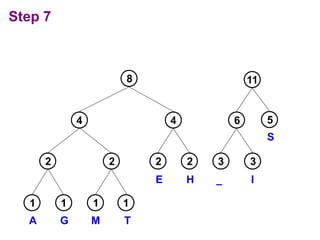
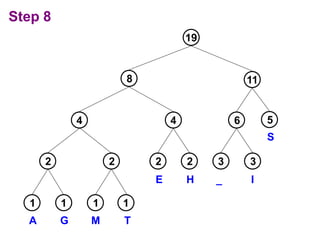
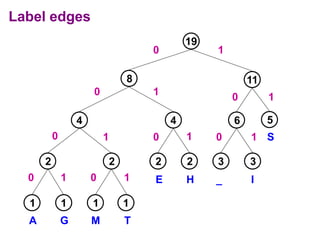
Huffman codes are a type of variable-length code that can more efficiently encode messages compared to fixed-length codes like ASCII. The document describes how to build a Huffman coding tree by assigning codes to characters based on their frequency in a message. The codes are assigned such that more frequent characters have shorter codes. This ensures the encoded message is as short as possible on average. Building the Huffman tree involves recursively combining the two least frequent characters until a full binary tree is constructed, with codes read from the paths.