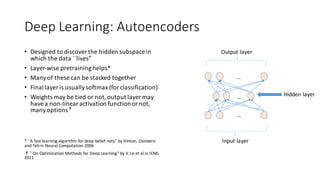
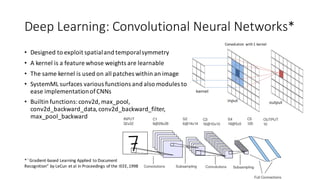
The document provides an overview of classification algorithms in Apache SystemML, including supervised learning techniques like support vector machines, logistic regression, naive Bayes, and decision trees. It discusses how these algorithms are formulated and implemented in SystemML, with a focus on optimization methods and parallelization. Key topics covered include the representer theorem, dual formulations, multi-class extensions, and using group-by aggregates and matrix operations for efficient training.





![Training Discriminative Classifiers
𝑓 = argmin 𝑓 ∑ ℓ(𝑓(𝒙𝑖), 𝑦𝑖) + ℊ(∥ 𝑓 ∥)/
012
• The second term is ``regularization”
• A common form for 𝑓(𝒙) is 𝐰′𝒙 (linear classifier)
• ℓ(w’x,y) is ``convexified” loss
• Besides discriminative classifiers, generative classifiers also exist
• e.g., naïve Bayes
Classifier Loss function (y ∈ {±1})
support vector machine max(0, 1 - y w’x)
logistic regression log[1 + exp(-y w’x)]
adaboost exp(-y w’x)
square loss (1 – y w’x)2
Algorithms for Direct 0–1 Loss Optim
−1.5 −1 −0.5 0 0.5 1 1.5 2
0
1
2
3
4
5
6
7
8
margin (m)
LossValue
0−1 Loss
Hinge Loss
Log Loss
Squared Loss
T
ar
is
W
in
(w
fw
as
th
T
{x
t
cl](https://image.slidesharecdn.com/s4classification-160913183141/85/Classification-using-Apache-SystemML-by-Prithviraj-Sen-5-320.jpg)

![Binary Class Support Vector Machines
minw ∑ max 0,1 − 𝑦𝑖𝒘S 𝒙𝑖 +
T
U
𝒘S 𝒘 /
012
• Expressed in standard form:
minw ∑ ξi +
T
U
𝒘S 𝒘 0
s.t. 𝑦𝑖 𝒘S 𝒙𝑖 ≥ 1 − ξi
∀𝑖
ξi ≥ 0 ∀𝑖
• Lagrangian (𝛼𝑖, 𝛽𝑖 ≥ 0):
ℒ = ∑ ξi +
T
U
𝒘S 𝒘 + ∑ 𝛼𝑖(1 − 𝑦𝑖 𝒘S 𝒙𝑖 − ξi00 ) − ∑ 𝛽𝑖 𝜉𝑖0
]ℒ
𝝏w
: w =
2
_
∑ 𝛼𝑖 𝑦𝑖 𝒙𝑖0
]ℒ
𝝏`i
: 1 = 𝛼𝑖+𝛽𝑖 ∀
𝑖](https://image.slidesharecdn.com/s4classification-160913183141/85/Classification-using-Apache-SystemML-by-Prithviraj-Sen-7-320.jpg)



![Logistic Regression
maxw -∑ log 1 + 𝑒hi0 𝒘j 𝒙0 −
T
U
𝒘S 𝒘 /
012
• To derive the dual form use the following bound*:
log
2
2klmn𝒘j 𝒙
≤ min 𝛼
𝛼𝑦𝒘′𝒙 − 𝐻(𝛼)
where 0 ≤ 𝛼 ≤ 1 and 𝐻(𝛼) = −𝛼log(𝛼) − (1 − 𝛼)log(1 − 𝛼)
• Substituting:
maxw min 𝛼 ∑ 𝛼𝑖 𝑦𝑖 𝒘′𝒙𝑖0 − 𝐻(𝛼𝑖) −
T
U
𝒘S 𝒘 s.t. 0 ≤ 𝛼𝑖 ≤ 1 ∀𝑖
]ℒ
𝝏w
: w =
2
_
∑ 𝛼𝑖 𝑦𝑖 𝒙𝑖0
• Dual form:
min 𝛼
2
UT
∑ 𝛼𝑖 𝛼𝑗 𝑦𝑖 𝑦𝑗 𝒙𝑖′𝒙𝑗0b − ∑ 𝐻(𝛼𝑖)0 s.t. 0 ≤ 𝛼𝑖 ≤ 1 ∀𝑖
• Apply kernel trick to obtain kernelized logistic regression
*``Probabilistic Kernel Regression Models” by Jaakkola and Haussler in AISTATS 1999](https://image.slidesharecdn.com/s4classification-160913183141/85/Classification-using-Apache-SystemML-by-Prithviraj-Sen-11-320.jpg)
![Multiclass Logistic Regression
• Also called softmax regression or multinomial logistic regression
• W is now a matrix of weights, jth column contains the jth class’s weights
Pr(y|x) =
lp
j
qn
∑ lp
j
qn
n
minW
_
U
∥ 𝑊 ∥ 2 + ∑ [log(Zi)0 − 𝑥𝑖′𝑊𝑦𝑖] where 𝑍𝑖 = 1S 𝑒wjx0
• The DML script is called MultiLogReg.dml
• Uses trust-region Newton method to learn the weights*
• Care needs to be taken because softmax is an over-parameterized function
*See regression class’s slides on ibm.biz/AlmadenML](https://image.slidesharecdn.com/s4classification-160913183141/85/Classification-using-Apache-SystemML-by-Prithviraj-Sen-12-320.jpg)
![Generative Classifiers: Naïve Bayes
• Generative models “explain” the generation of the data
• Naïve Bayes assumes, each feature is independent given class label
Pr(x,y) = py ∏ (𝑝𝑦𝑗b )nj
• A conjugate prior is used to avoid 0 probabilities
Pr({(xi,yi)}) = ∏ [
{|
(_)
{(|_)
∏ 𝑝 𝑦𝑗
𝜆]bi ∏ [𝑝𝑦𝑖∏ 𝑝 𝑦𝑖𝑗
𝑛𝑖𝑗]b0
s.t. 𝑝 𝑦 ∀ 𝑦, 𝑝𝑦𝑗 ∀𝑦 ∀𝑗 form legal distributions
• Maximum is obtained when:
𝑝 𝑦 =
𝑛 𝑦
∑ 𝑛 𝑦i
∀𝑦, 𝑝𝑦𝑗 =
𝜆 + ∑ 𝑛𝑖𝑗0:i01i
𝑚𝜆 + ∑ ∑ 𝑛𝑖𝑗b0:i01i
∀𝑦∀𝑗
• This is multinomial naïve Bayes, other forms include multivariate Bernoulli*
* ``A Comparison of Event Models for Naïve Bayes Text Classification” by McCallum and Nigam in AAAI/ICML-98 Workshop on Learning for Text
Categorization](https://image.slidesharecdn.com/s4classification-160913183141/85/Classification-using-Apache-SystemML-by-Prithviraj-Sen-13-320.jpg)









































![Echo National Sales Meeting 2016 [Day 1]](https://cdn.slidesharecdn.com/ss_thumbnails/day1-160225173953-thumbnail.jpg?width=640&height=640&fit=bounds)



































































