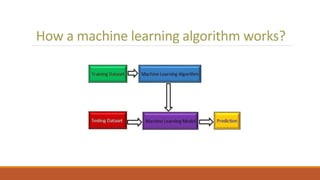
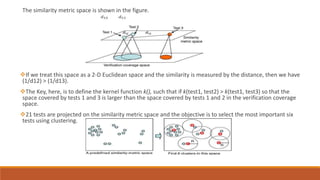
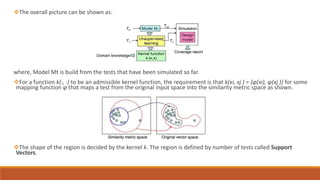
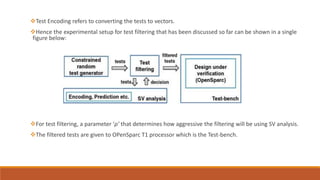
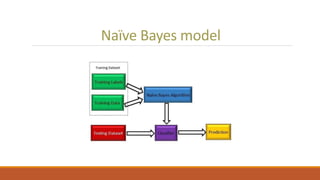
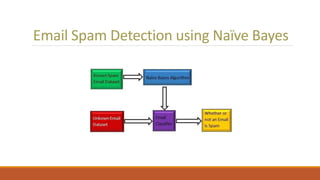
This document discusses using unsupervised support vector analysis to increase the efficiency of simulation-based functional verification. It describes applying an unsupervised machine learning technique called support vector analysis to filter redundant tests from a set of verification tests. By clustering similar tests into regions of a similarity metric space, it aims to select the most important tests to verify a design while removing redundant tests, improving verification efficiency. The approach trains an unsupervised support vector model on an initial set of simulated tests and uses it to filter future tests by comparing them to support vectors that define regions in the similarity space.