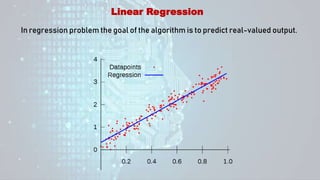
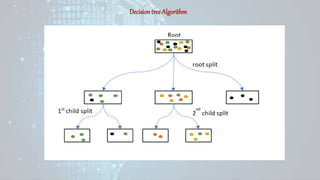
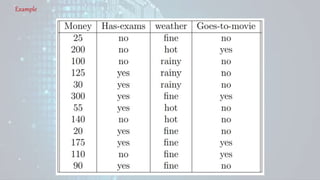
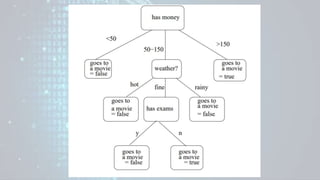
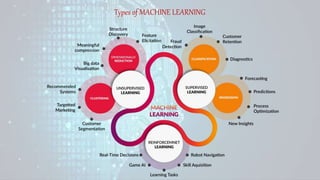
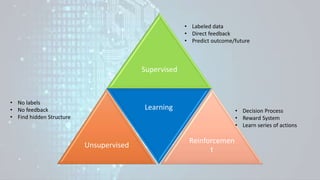
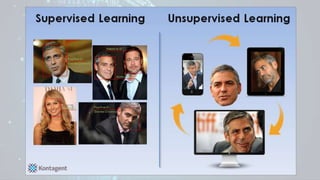
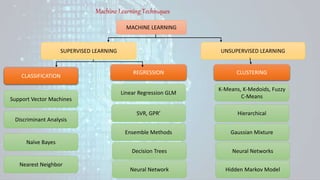
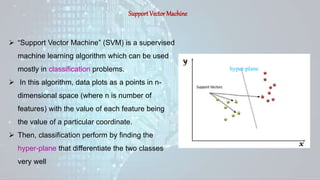
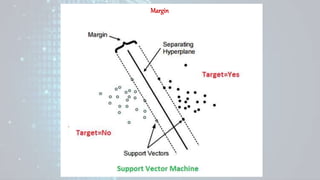
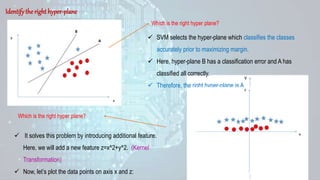
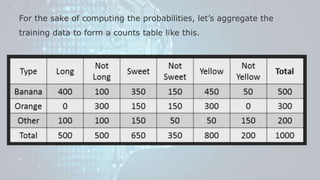
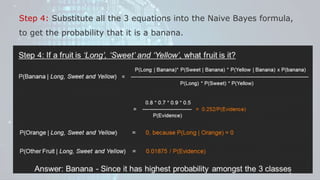
Machine learning is a field of study that gives computers the ability to learn without being explicitly programmed. There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning. Supervised learning uses labeled training data to infer a function that maps inputs to outputs, unsupervised learning looks for hidden patterns in unlabeled data, and reinforcement learning allows an agent to learn from interaction with an environment through trial-and-error using feedback in the form of rewards. Some common machine learning algorithms include support vector machines, discriminant analysis, naive Bayes classification, and k-means clustering.



















































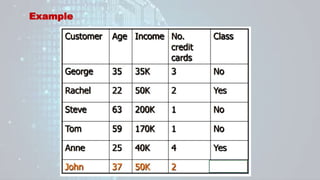
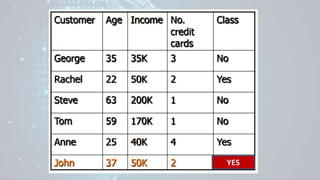
![George to John Distance = Sqrt[(35 − 37)2+(35 − 50)2+(3 − 2)2] = 15.16
Rachel to John Distance = Sqrt[(22 − 37)2+(50 − 50)2+(2 − 2)2] = 15
Steve to John Distance = Sqrt[(63 − 37)2+(200 − 50)2+(1 − 2)2] = 152.23
Tom to John Distance = Sqrt[(59 − 37)2+(170 − 50)2+(1 − 2)2] = 122
Tom to John Distance = Sqrt[(25 − 37)2+(40 − 50)2+(4 − 2)2] = 15.74
Distance Measure from john to others using Euclidean
Distance](https://image.slidesharecdn.com/machinelearningppt-230831150831-6ff1b768/85/Machine-Learning_PPT-pptx-66-320.jpg)