Unit IV :MACHINE LEARNING
Introduction – ML Algorithms Overview – Types – Supervised – Unsupervised
– Reinforcement Learning – Introduction to Neural Networks – Working of
Deep Learning – Applications of DL – Ethical consideration in AI and ML.
3.
Introduction to MachineLearning
• The term machine learning was first coined in the 1950s.
• Machine learning is used in automated translation, image recognition, voice
search technology, self-driving cars, and beyond.
Machine Learning:
• Machine Learning (ML) is a branch of Artificial Intelligence (AI) that
focuses on enabling computers to learn from data without being explicitly
programmed. (or)
• Machine learning (ML) is a branch of artificial intelligence (AI) that
enables computers to “self-learn” from training data and improve over
4.
Key Concepts inMachine Learning
• Training Data & Testing Data: Training data is used to build the model, while
testing data evaluates its performance.
• Features & Labels: Features are the input variables (e.g., age, height), and
labels are the output or prediction (e.g., whether a person is healthy).
• Model Training & Evaluation: The model learns from training data, and its
accuracy is tested on new data to ensure it generalizes well.
• Optimization: This process involves adjusting the model to minimize errors and
improve accuracy.
5.
How does MachineLearning Works
Machine learning system builds prediction models, learns from previous data, and
predicts the output of new data whenever it receives it. The amount of data helps to
build a better model that accurately predicts the output, which in turn affects the
accuracy of the predicted output.
• Collect data: Data can come from databases, sensors, or the internet.
• Prepare data: Data is preprocessed to ensure it's suitable for analysis.
• Train a model: An algorithm is trained to learn from the data.
• Evaluate the model: The model's performance is assessed to determine if it
meets the desired criteria.
• Deploy the model: The model is used in real-world applications.
6.
Machine Learning algorithmsoverview
Machine Learning algorithms are the programs that can learn the hidden patterns
from the data, predict the output, and improve the performance from experiences
on their own.
Types of Machine Learning Algorithms:
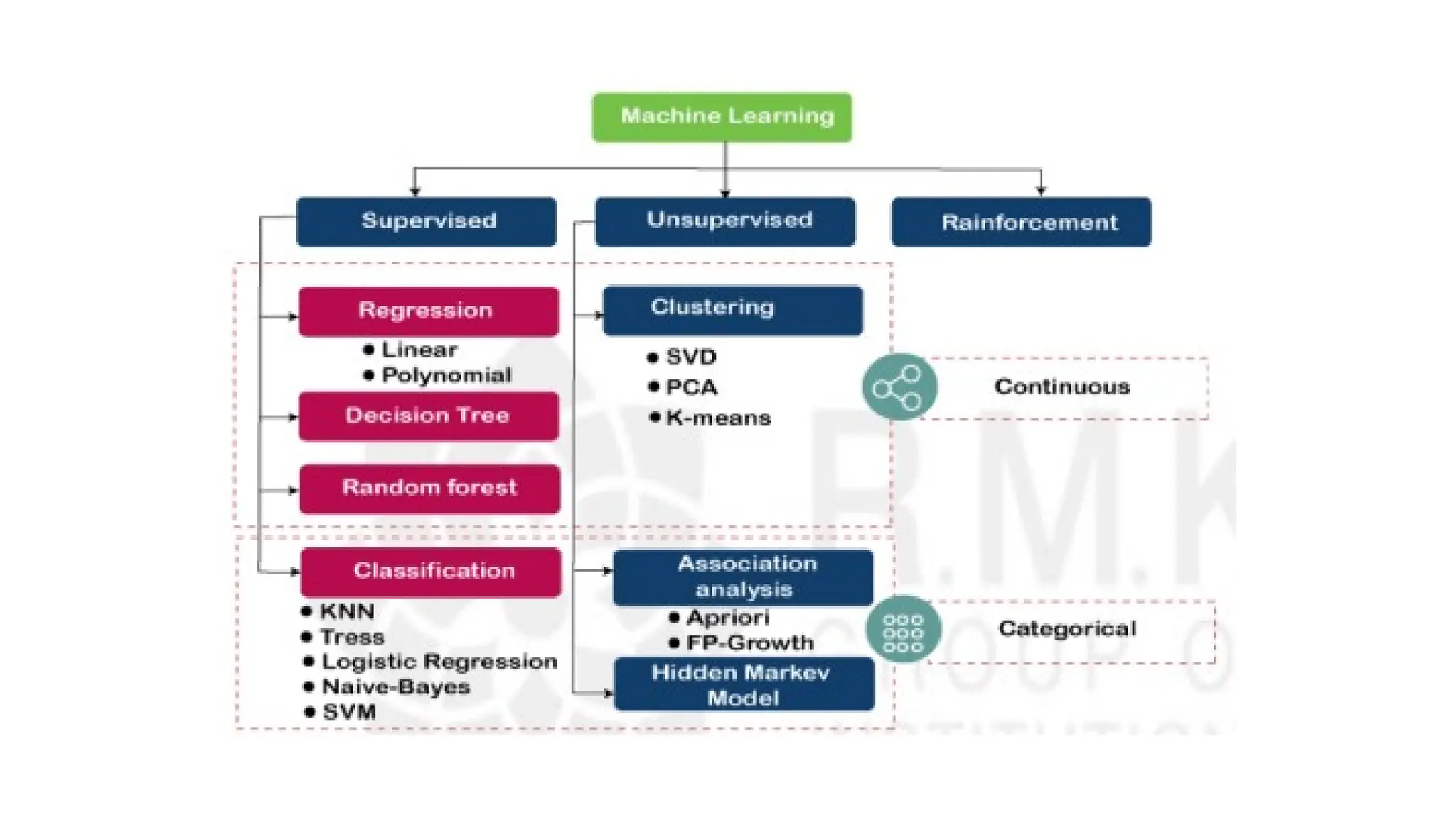
Machine Learning Algorithm can be broadly classified into three types:
1. Supervised Learning Algorithms
2. Unsupervised Learning Algorithms
3. Reinforcement Learning algorithm
8.
Supervised Machine learningAlgorithms
Supervised learning is a machine learning technique in which the algorithm is
trained on labeled data. This means that for each input, the corresponding output
(or label) is provided. The model’s goal is to learn the mapping from inputs to
outputs and make accurate predictions on new, unseen data.
Working of Supervised Machine Learning
Supervised learning algorithm consists of input features and corresponding output
labels. The process works through:
Training Data: The model is provided with a training dataset that includes input
data (features) and corresponding output data (labels or target variables).
9.
Learning Process: Thealgorithm processes the training data, learning the
relationships between the input features and the output labels. This is achieved by
adjusting the model’s parameters to minimize the difference between its predictions
and the actual labels.
After training, the model is evaluated using a test dataset to measure its
accuracy and performance. Then the model’s performance is optimized by
adjusting parameters and using techniques like cross validation to balance bias and
variance.
10.
Types of SupervisedLearning in Machine Learning
Supervised learning can be applied to two main types of problems:
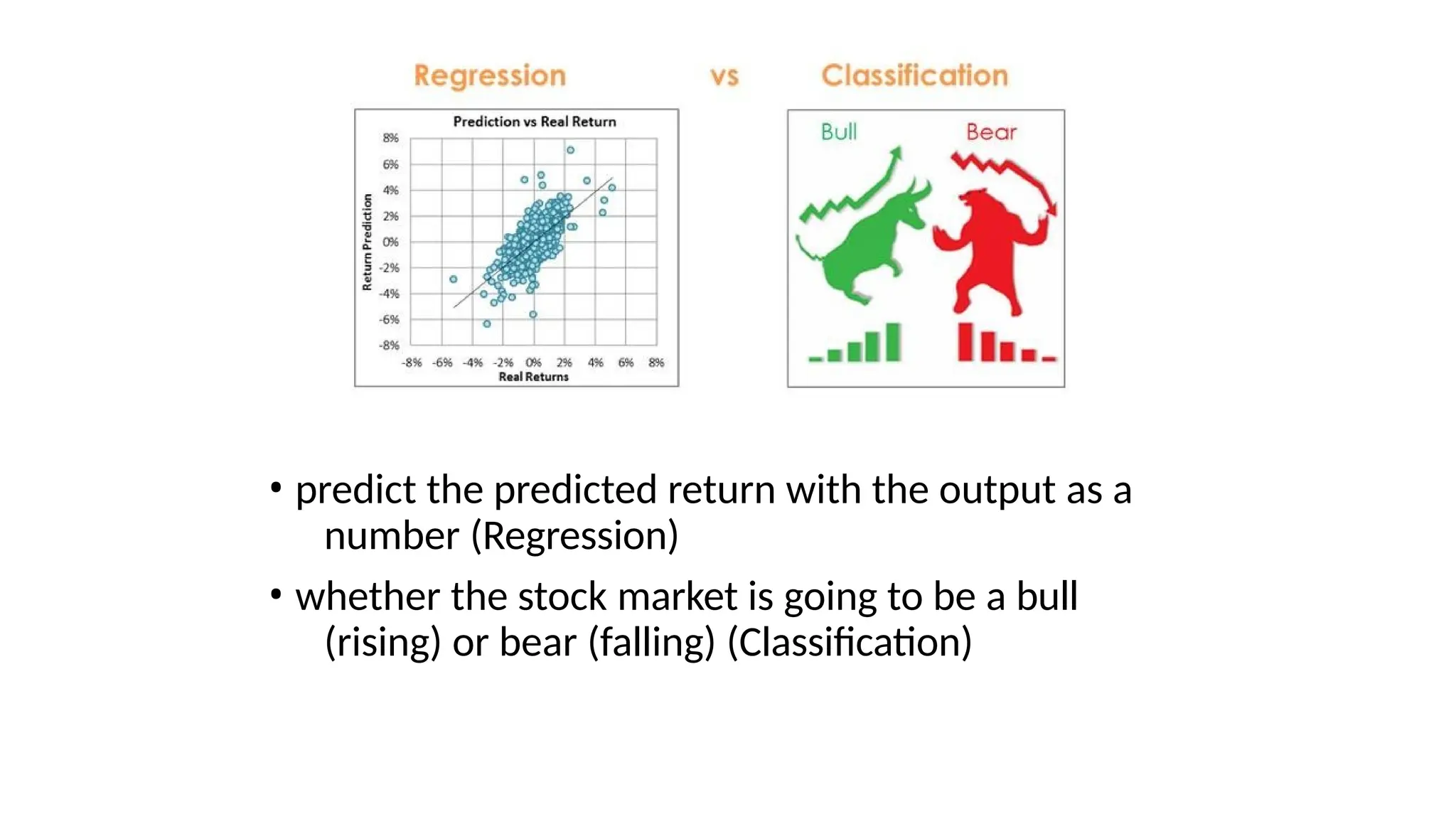
• Classification: Where the output is a categorical variable (e.g., spam vs. non-
spam emails, yes vs. no).
• Regression: Where the output is a continuous variable (e.g., predicting house
prices, stock prices).
11.
• predict thepredicted return with the output as a
number (Regression)
• whether the stock market is going to be a bull
(rising) or bear (falling) (Classification)
12.
Supervised Learning algorithms
•Some Supervised Learning algorithms work for
both types of problems while some works on only one.
• k-Nearest Neighbour (Classificiation)
• Naive Bayes (Classificiation)
• Decision Tress/Random Forest (Classificiation and
Regression)
• Support Vector Machine (Classificiation)
• Linear Regression (Regression)
• Logistic Regression (Classificiation)
13.
Regression
Regression in machinelearning refers to a supervised learning technique where the
goal is to predict a continuous numerical value based on one or more independent
features. It finds relationships between variables so that predictions can be made.
we have two types of variables present in regression:
• Dependent Variable (Target): The variable we are trying to predict. e.g house
price.
• Independent Variables (Features): The input variables that influence the
prediction. e.g locality, number of rooms.
14.
Importance of Regression
-Predicting Future Values (e.g., sales forecasting, weather prediction)
- Understanding Relationships between variables (e.g., how study time affects
exam scores)
- Identifying Trends & Patterns in data
Types of Regression Models
1. Linear Regression
2. Multiple Linear Regression
3. Polynomial Regression
4. Logistic Regression (For Classification)
15.
Types of RegressionModels
Regression is broadly classified into linear and non-linear methods.
Linear Regression
Linear Regression is a fundamental supervised learning algorithm used for
predicting a continuous dependent variable based on one or more independent
variables. It assumes a linear relationship between the input variables (features) and
the output variable.
16.
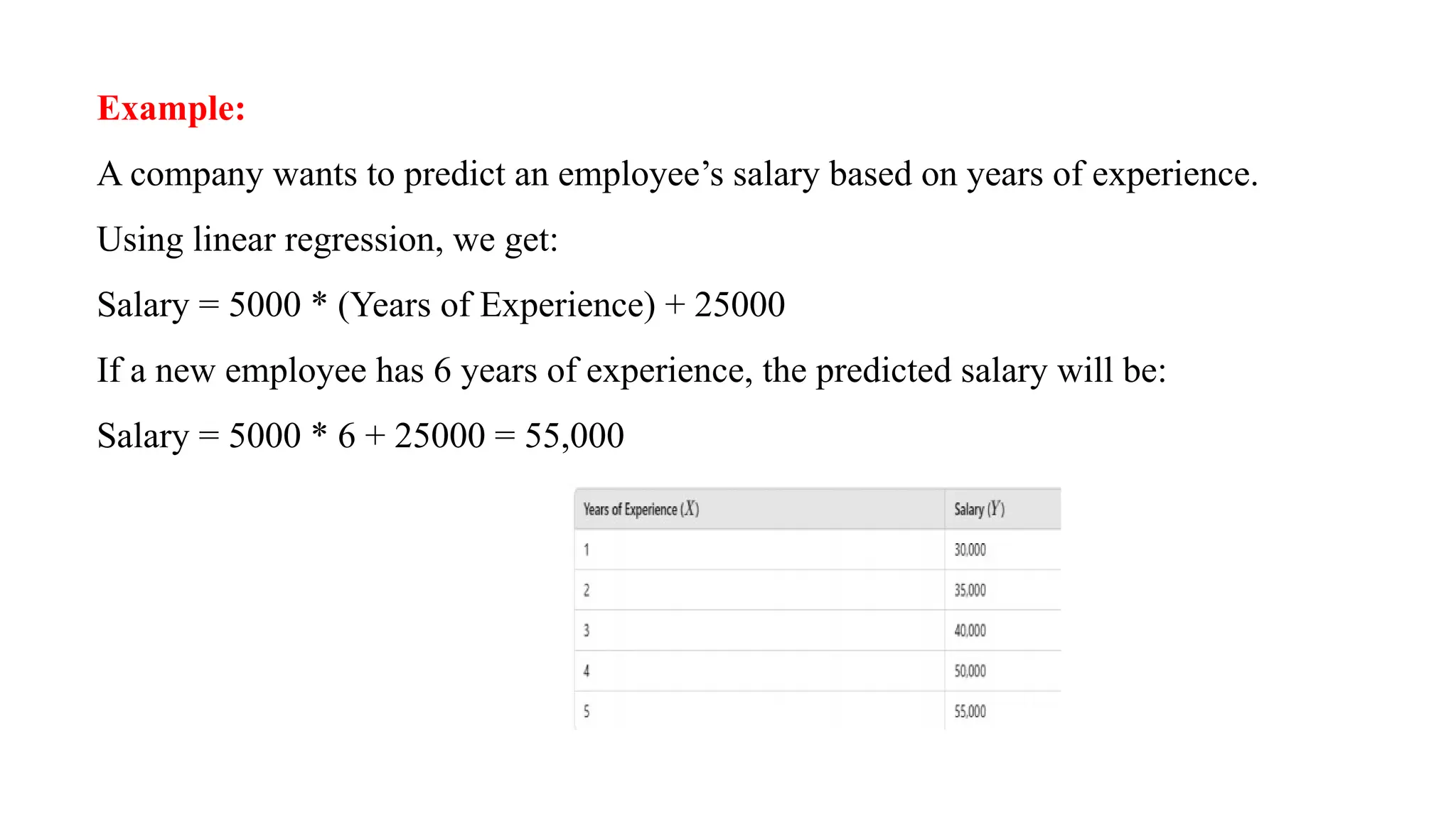
Example:
A company wantsto predict an employee’s salary based on years of experience.
Using linear regression, we get:
Salary = 5000 * (Years of Experience) + 25000
If a new employee has 6 years of experience, the predicted salary will be:
Salary = 5000 * 6 + 25000 = 55,000
Polynomial Regression
A typeof regression that models a non-linear relationship between the
independent variable (X) and the dependent variable (Y) by introducing
higher-degree polynomial terms.
19.
Example:
Predicting population growthover time (which follows an exponential or
quadratic trend rather than a straight line).
A linear model might not fit well, but a quadratic function like:
20.
Logistic Regression (ForClassification)
Used for binary classification problems, predicting probabilities rather than
continuous values.
Example:
Predicting whether a student passes or fails based on study hours and
previous grades.
Output: 0 (Fail), 1 (Pass)
If P(Y)>0.5P(Y) > 0.5P(Y)>0.5, predict Pass (1), else Fail (0).
21.
Logistic Regression
A statisticalmethod for binary classification that predicts the probability of an
event occurring (e.g., Yes/No, Spam/Not Spam, Disease/No Disease).
Unlike linear regression, it models the output using the sigmoid (logistic) function.
How Logistic Regression Works
Step 1: Apply a Linear Function
Logistic Regression calculates a weighted sum of the input features:
where
• w= weights (importance of each feature)
• x = input features (Glucose, BMI, etc.)
• b = bias term
22.
For example, ifa person has:
Glucose = 150, BMI = 30, Age = 40,
The equation might be:
Step 2: Convert to Probability Using the Sigmoid Function
Since we need a probability (between 0 and 1), we apply the sigmoid function:
Example :
If σ(Z) > 0.5, predict 1 (Diabetes)
If σ(Z) ≤ 0.5, predict 0 (No Diabetes)
23.
Types of LogisticRegression
Binary Logistic Regression: The target variable has only two possible outcomes
such as Spam or Not Spam, Cancer or No Cancer.
Multinomial Logistic Regression: The target variable has three or more nominal
categories, such as predicting the type of Wine.
Ordinal Logistic Regression: the target variable has three or more ordinal
categories, such as restaurant or product rating from 1 to 5
24.
Classification
Classification is atype of supervised machine learning where algorithms learn
from the data to predict an outcome or event in the future.
example:
A bank may have a customer dataset containing credit history, loans, investment
details, etc. and they may want to know if any customer will default. In the
historical data, we will have Features and Target. Features will be attributes of a
customer such as credit history, loans, investments, etc.
Target will represent whether a particular customer has defaulted in the past
(normally represented by 1 or 0 / True or False / Yes or No.
25.
• Classification algorithmsare used for predicting discrete outcomes, if the
outcome can take two possible values such as True or False, Default or No
Default, Yes or No, it is known as Binary Classification.
• When the outcome contains more than two possible values, it is known as
Multiclass Classification. There are many machine learning algorithms that can
be used for classification tasks.
Some of them are: Logistic Regression, Decision Tree Classifier
26.
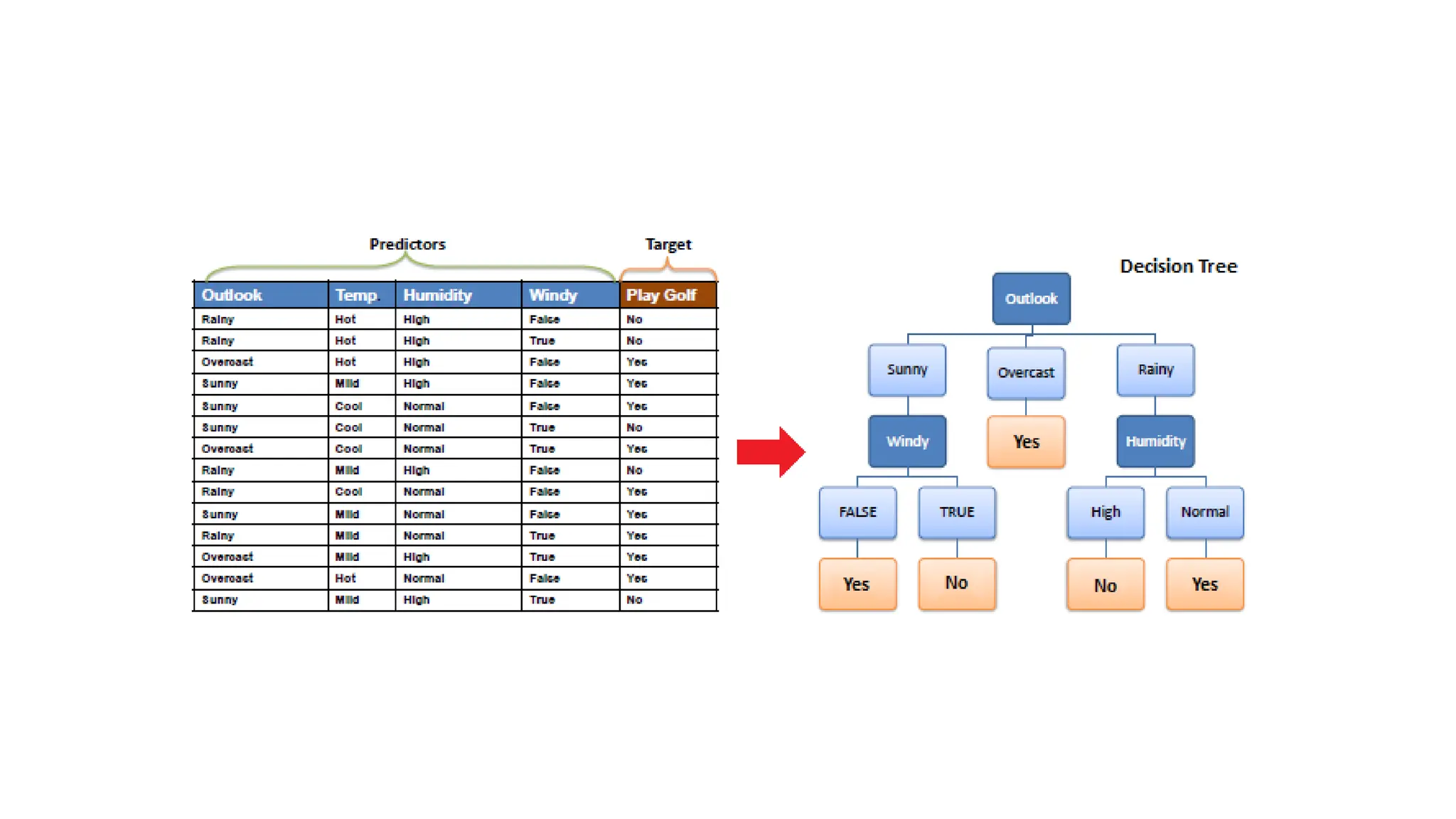
Decision Tree Classification
•Decision tree classification is a non parametric regression technique that models
the relationship between the independent and dependent variables using a tree-
like structure.
• The algorithm splits the data into subsets based on the values of the independent
variables, aiming to minimize the variance of the target variable within each
subset.
Example
Predicting the price of a used car based on factors such as mileage, age, brand, and
model. Decision tree classification can capture complex interactions between these
features, providing a clear and interpretable model for predicting car prices.
27.
Decision Tree Classifier
ADecision Tree is a supervised machine learning algorithm used for classification
and regression tasks. It is a tree-like structure where each internal node represents a
decision based on a feature, each branchrepresents an outcome of that decision, and
each leaf node represents a final classification or decision.
28.
1.Structure of aDecision Tree
A Decision Tree consists of:
Root Node: The topmost node that represents the entire dataset and gets split into
two or more branches.
Internal Nodes: Represent decision points where a feature_x0002_based condition
is checked.
Branches: The links connecting nodes, representing possible outcomes of a
decision.
Leaf Nodes: The terminal nodes that contain the final decision (class label or
predicted value).
29.
2.How Decision TreesWork?
A Decision Tree is built using a recursive process called Recursive Partitioning or
Divide and Conquer, where:
1. Choose the Best Feature to Split: The dataset is divided based on a feature that
results in the best separation of classes or values.
2. Split the Data: Create branches based on feature values and recursively repeat the
process on each subset.
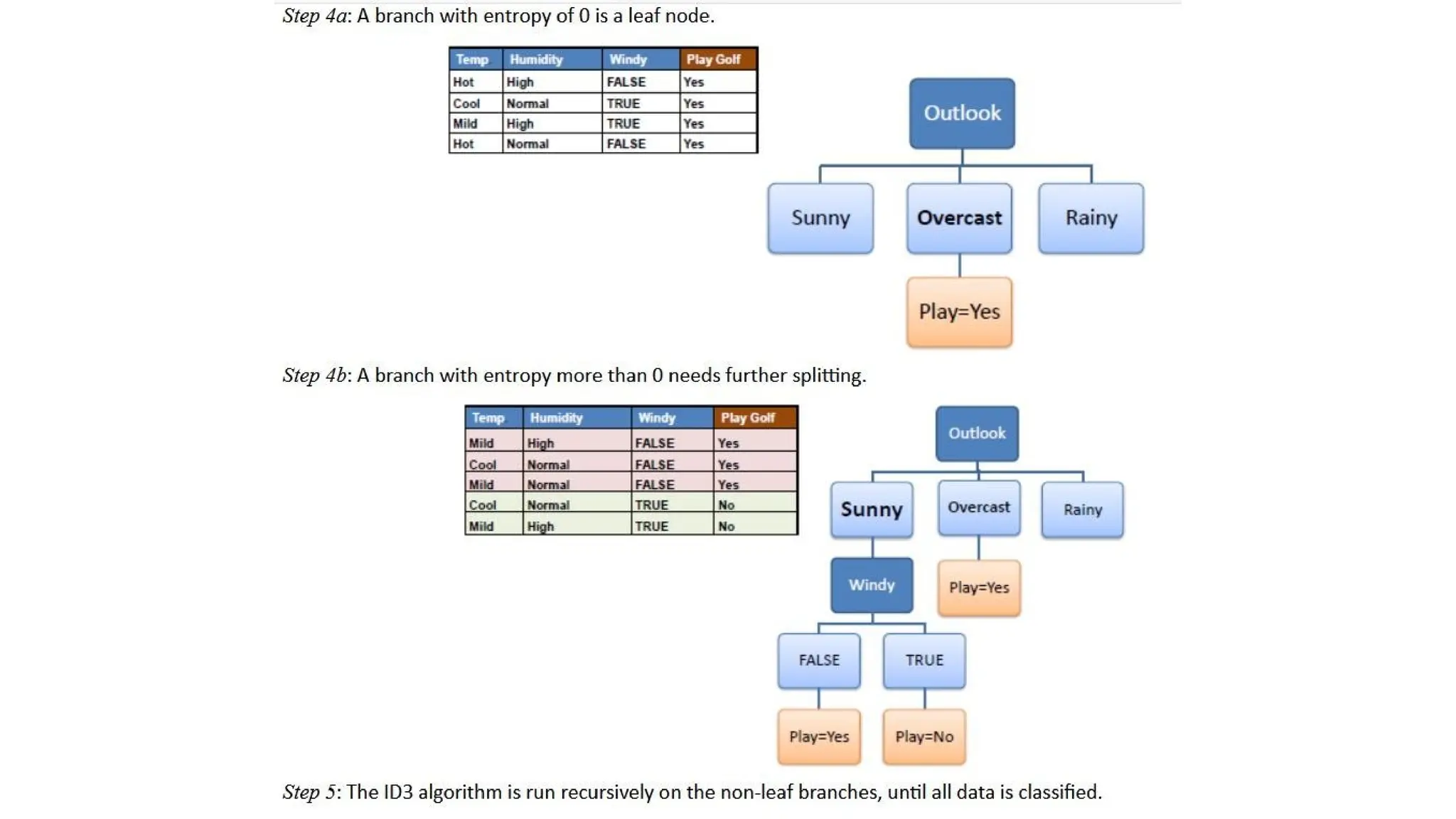
3. Stopping Criteria: The process stops when:
o All instances belong to the same class (pure node).
o No more features are available for splitting.
o A predefined depth or minimum number of samples per node is reached.
30.
3.Splitting Criteria
Decision Treesuse mathematical measures to determine the best feature to split a
node:
(i) For Classification Trees
(ii) For Regression Trees
31.
(i) For ClassificationTrees
Gini Impurity: Measures how often a randomly chosen element would be incorrectly
classified.
Entropy (Information Gain): Measures disorder or uncertainty in a dataset.
Information Gain: The reduction in entropy after splitting.
32.
(ii) For RegressionTrees
• Mean Squared Error (MSE): Measures variance within a split.
• Mean Absolute Error (MAE): Measures the average absolute differences.
Pruning to Avoid Overfitting
To reduce overfitting, pruning techniques are used:
• Pre-Pruning (Early Stopping): Stop growing the tree when it reaches a certain
depth or minimum samples per node.
• Post-Pruning: Grow the full tree first and then remove unnecessary branches
based on validation data.
33.
Decision Tree Algorithms
Somepopular algorithms for building Decision Trees:
ID3 (Iterative Dichotomiser 3): Uses Information Gain for splitting.
C4.5: Improvement over ID3, supports continuous data and pruning.
CART (Classification and Regression Trees): Uses Gini impurity (classification)
and MSE (regression).
34.
Attribute selection
• InDecision Tree the major challenge is to
identification of the attribute for the root node
in each level. This process is known as
attribute selection.
• two popular attribute selection measures:
1.Information Gain
2.Gini Index
36.
ID3 algorithm
• corealgorithm for building decision trees called ID3
(Iterative Dichotimizer)
• ID3 uses Entropy and Information Gain to construct
a decision tree.
37.
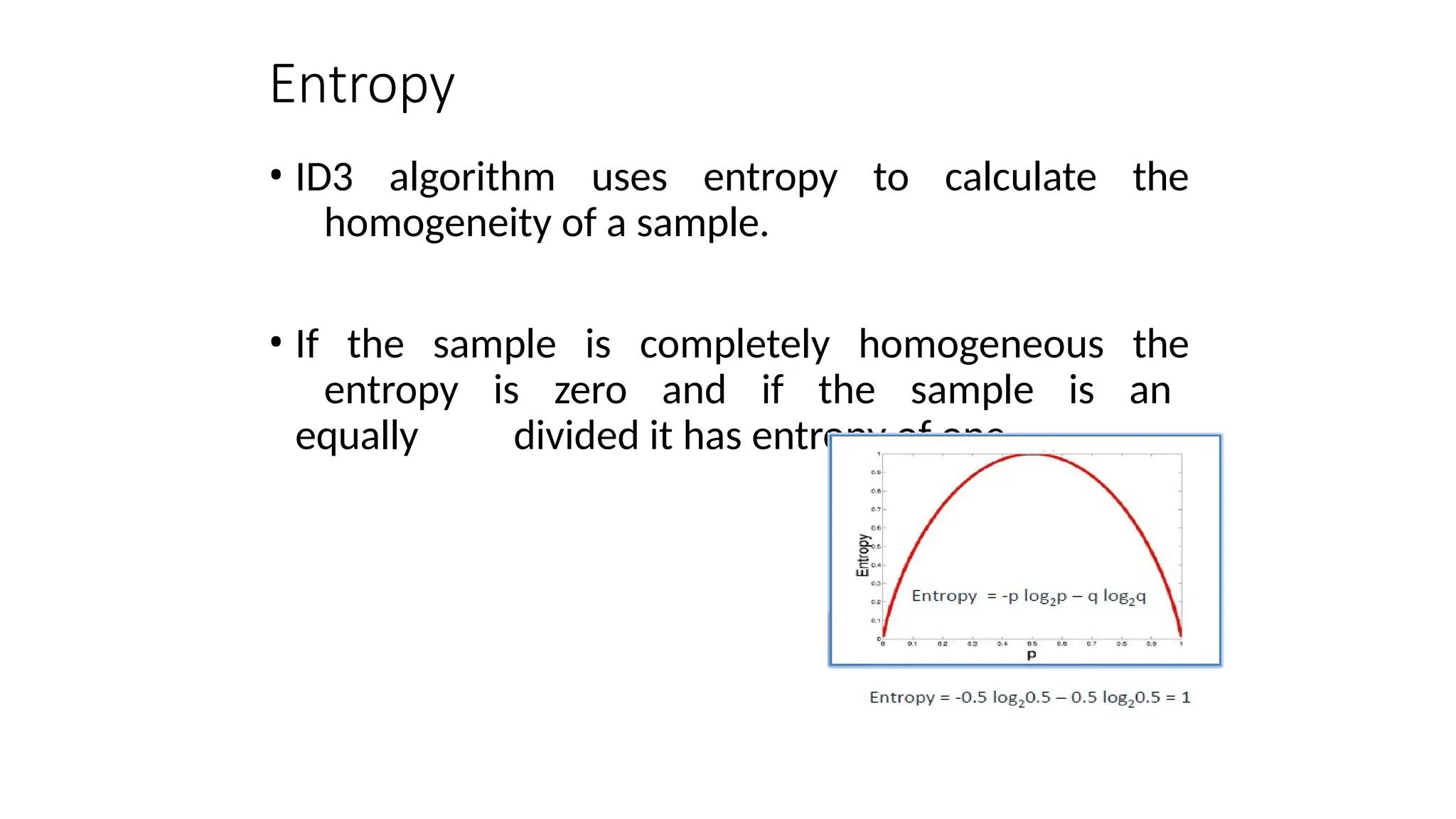
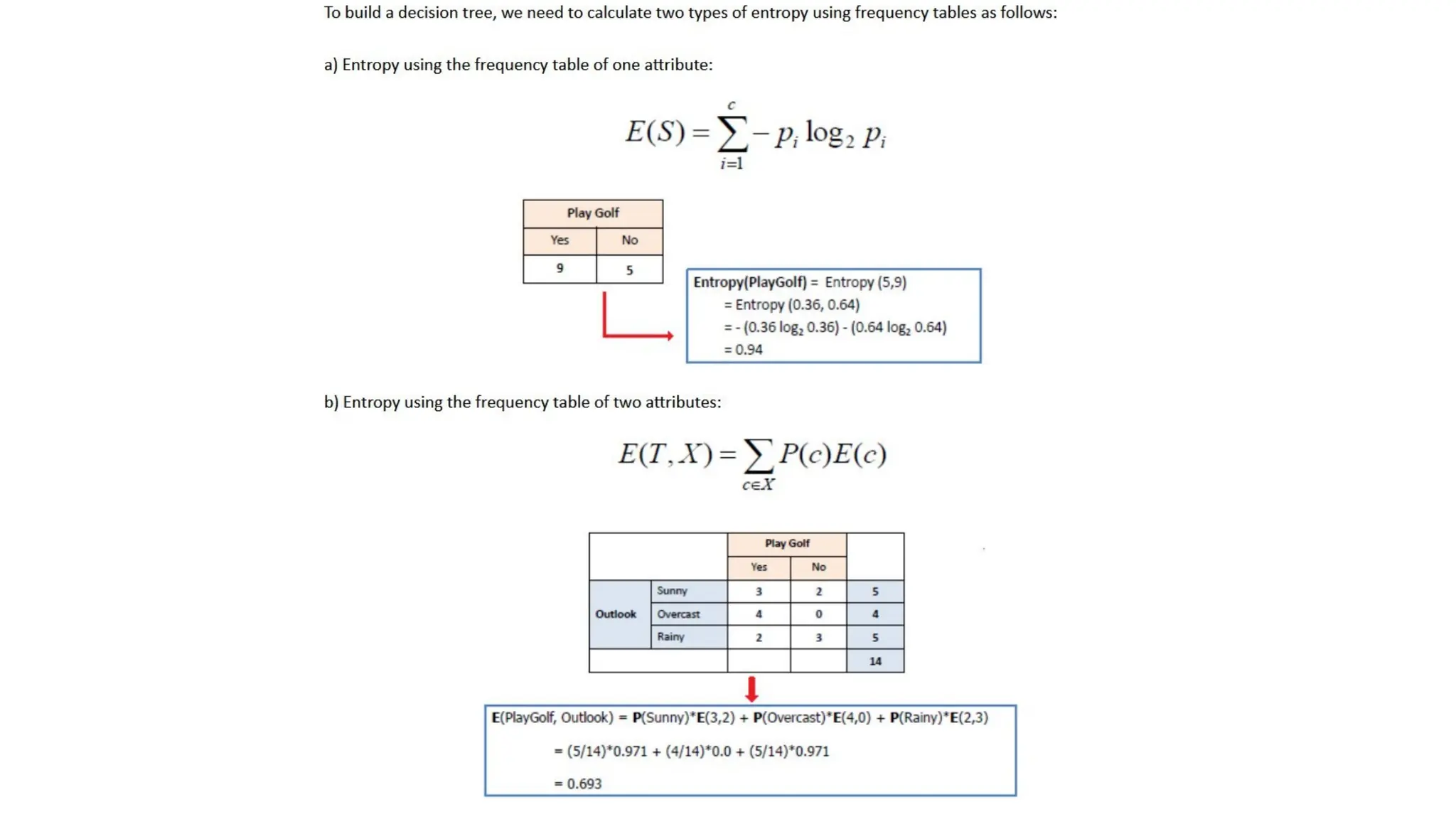
Entropy
• ID3 algorithmuses entropy to calculate the
homogeneity of a sample.
• If the sample is completely homogeneous the
entropy is zero and if the sample is an
equally divided it has entropy of one.
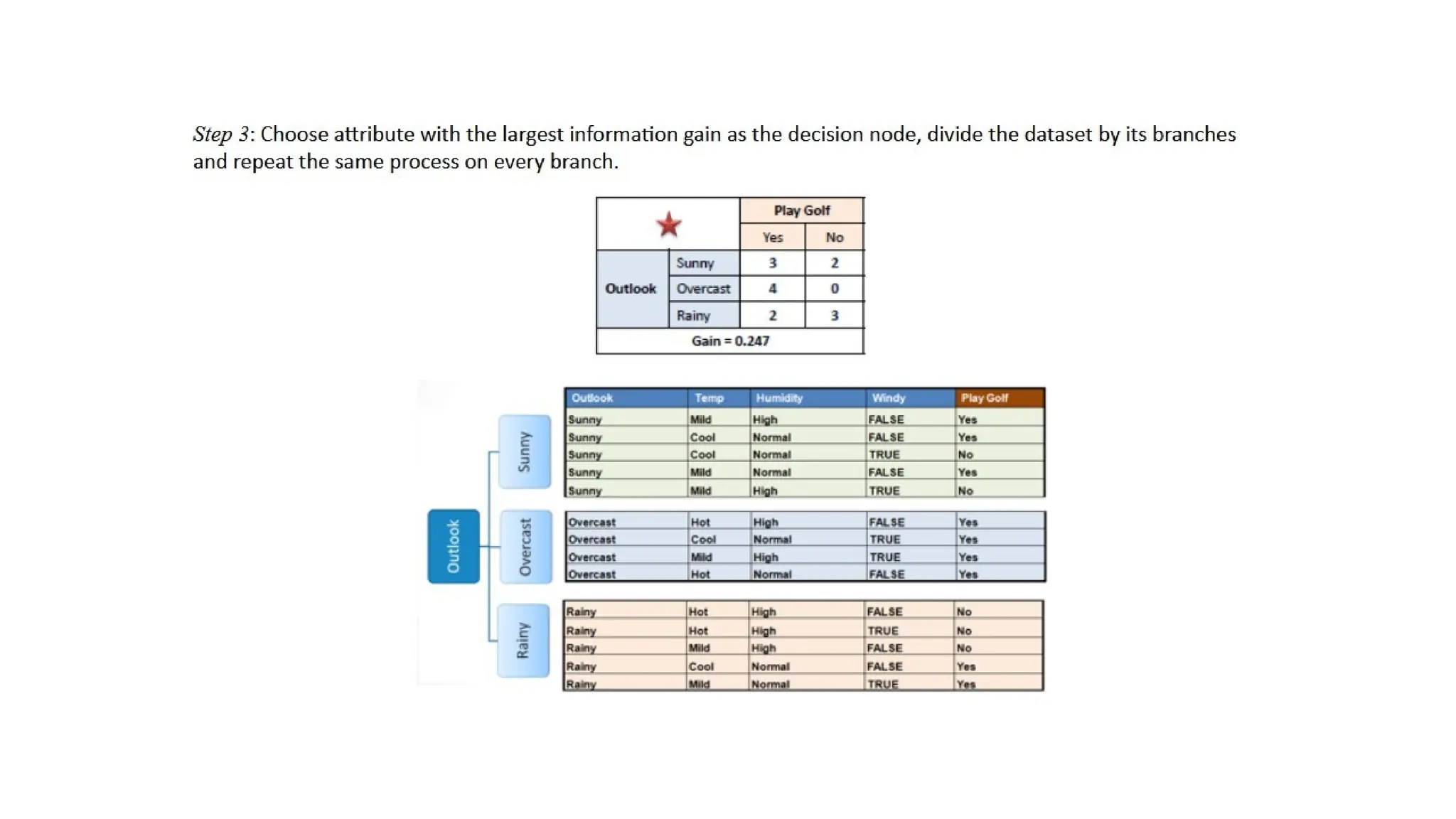
Decision Tree Representation
Whenbuilding a decision tree, we choose the root node
(first split) based on the attribute that provides the highest
Information Gain (IG) or the lowest Gini Impurity.
Let's compare Credit History and Income using
Information Gain (IG).
44.
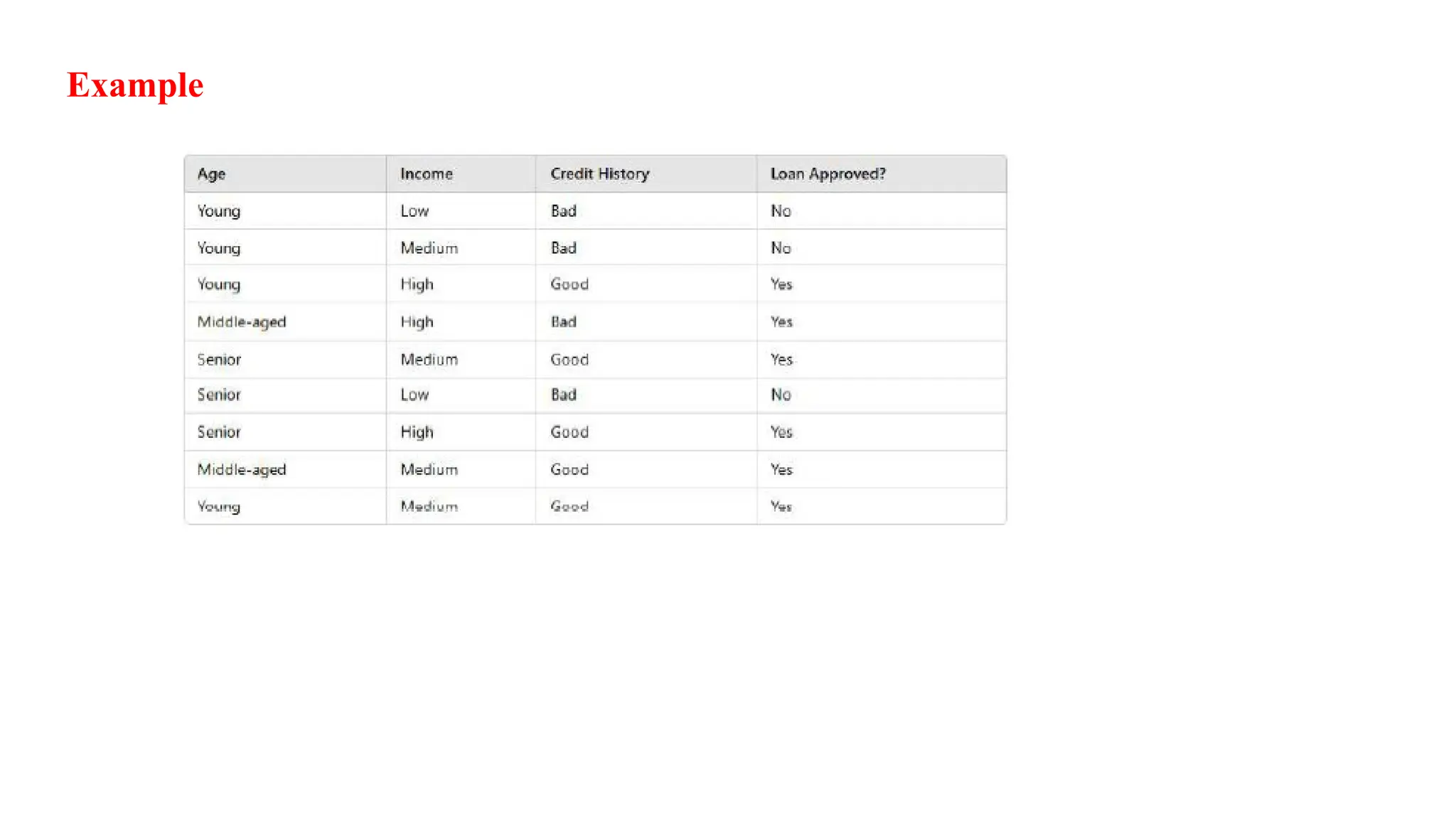
Step 1: CalculateEntropy of the Root (Before Splitting)
Our dataset has: 43
Loan Approved (Yes) = 6
Loan Not Approved (No) = 3
Total = 9 records
Root Entropy:
45.
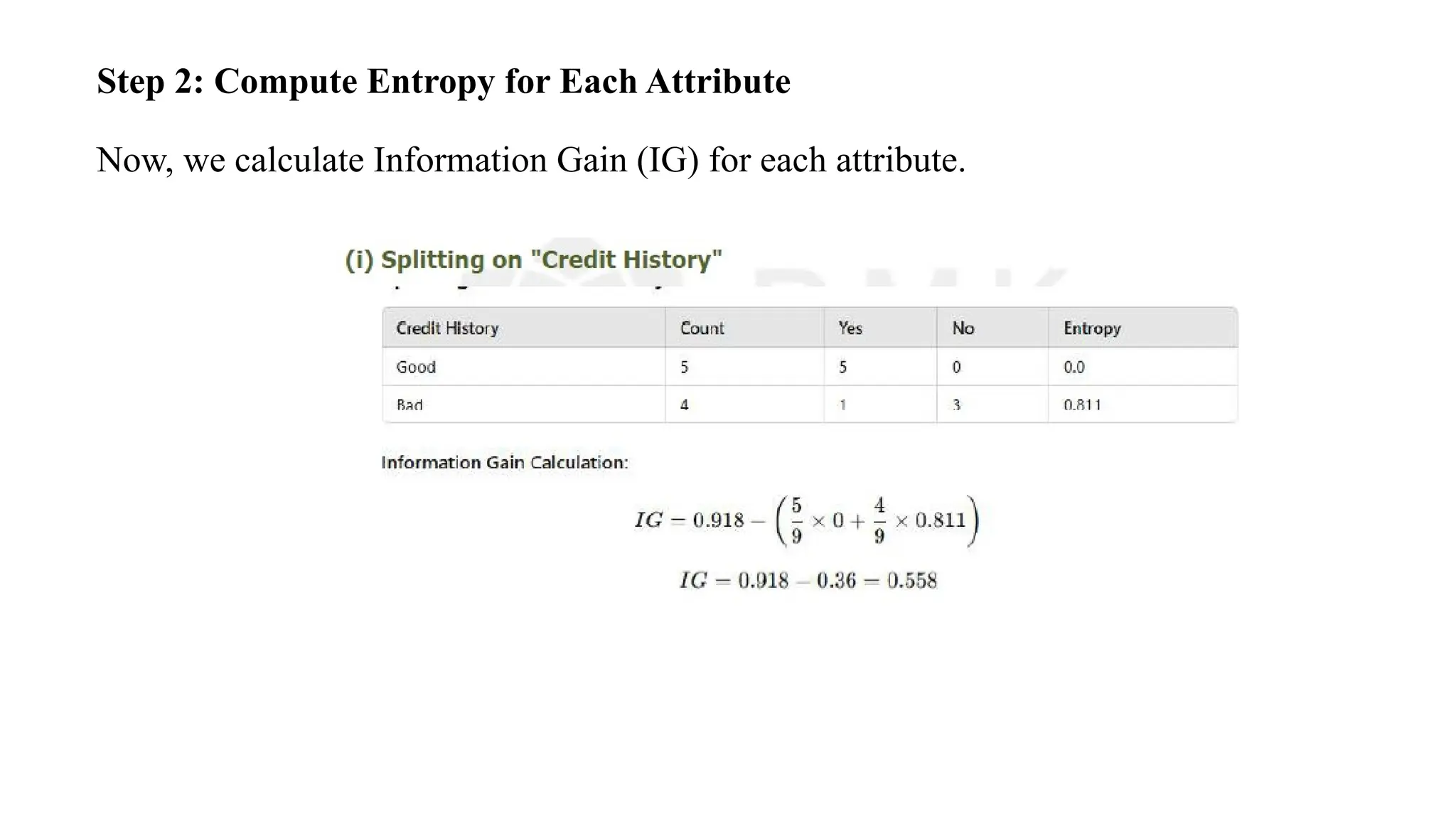
Step 2: ComputeEntropy for Each Attribute
Now, we calculate Information Gain (IG) for each attribute.
46.
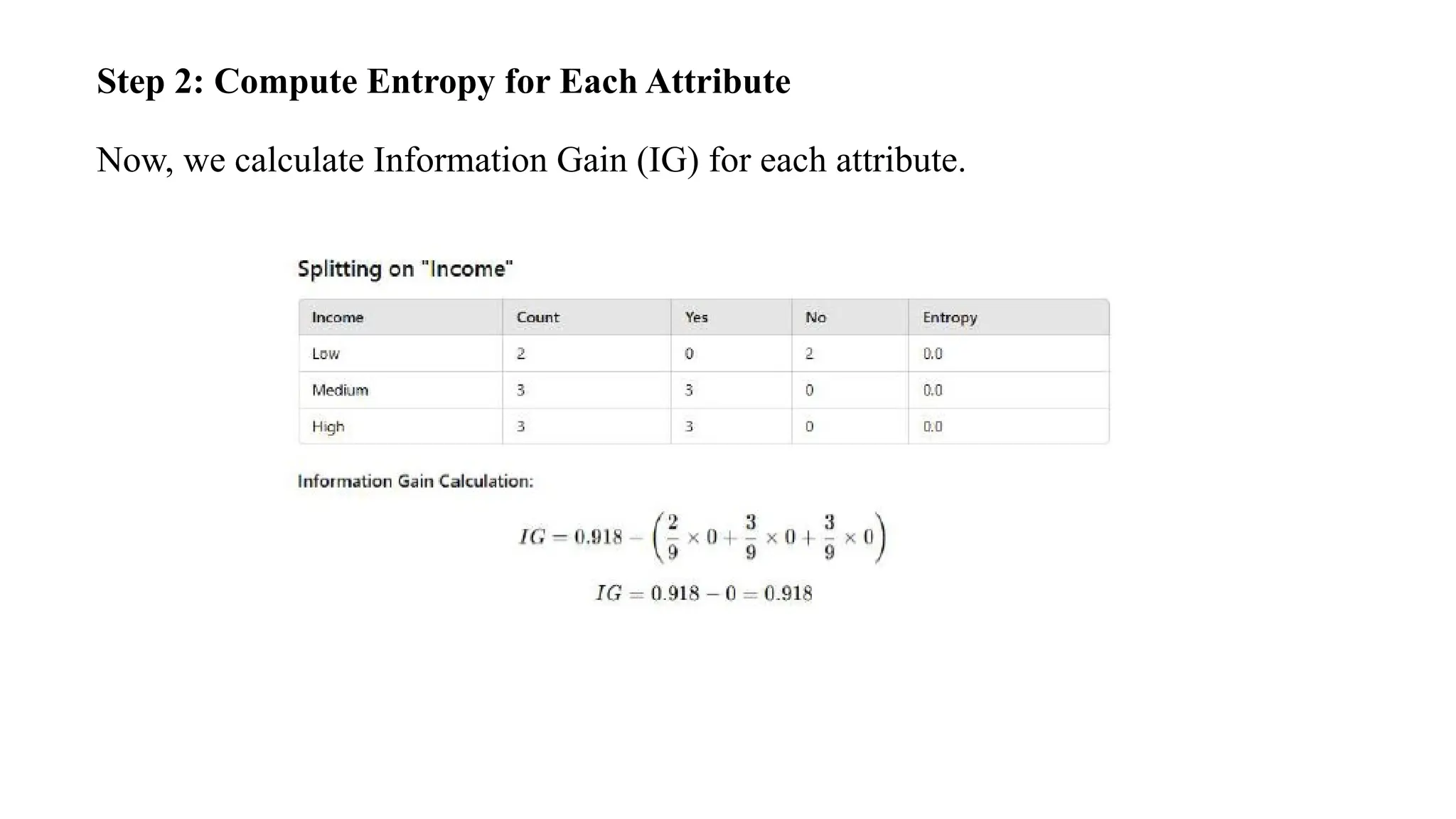
Step 2: ComputeEntropy for Each Attribute
Now, we calculate Information Gain (IG) for each attribute.
47.
Step 3: Choosethe Attribute with Highest IG
• IG for Credit History = 0.558
• IG for Income = 0.918
Since Income has a higher Information Gain, it seems like a better choice.
However, in real-world decision trees, domain knowledge is also considered. In
banking, "Credit History" is often the most important factor for loan decisions, so it
is prioritized.
48.
Random Forest Regressor
RandomForest Regressor is a machine learning algorithm based on ensemble
learning, specifically an extension of decision trees for regression tasks. It works
by constructing multiple decision trees during training and averaging their
predictions to improve accuracy and reduce overfitting.
49.
Key Features
Ensemble Learning:Uses multiple decision trees to make predictions.
Bootstrap Aggregation (Bagging): Each tree is trained on a random subset of data
with replacement.
Feature Randomness: Each tree considers a random subset of features, enhancing
diversity.
Averaging Predictions: Reduces variance and improves stability.
Handles Non-Linearity: Works well with complex relationships in data.
50.
K-Nearest Neighbors (KNN)Regression (Working)
K-Nearest Neighbors (KNN) Regression is a non-parametric, instance based
learning algorithm that predicts the output for a new data point based on the
average or weighted average of its k-nearest neighbors.
51.
Step-by-Step Working ofKNN Regression
1. Choose the Value of k (Number of Neighbors)
k is the number of nearest data points considered for predicting the output.
Small k → More sensitive to noise, may overfit.
Large k → Smoother predictions but may underfit.
2. Compute the Distance to All Training Points
For a given test point, compute the distance to all training points.
52.
Minkowski Distance (Generalizedform)
This is a generalization that includes both Euclidean and Manhattan distances
as special cases
3. Select the k Nearest Neighbors
After computing distances, pick the k closest data points.
These points are the nearest neighbors of the test point.
4. Compute the Predicted Value
There are two ways to determine the output:
Simple Average (Uniform Weights)
Each of the k nearest neighbors contributes equally to the final prediction. This
method assumes that all neighbors are equally important.
53.
Weighted Average (Distance-BasedWeights)
Closer neighbors (smaller did_idi) have a greater influence on the prediction than
farther ones.
This approach reduces the impact of distant neighbors, improving accuracy in
many cases.
59.
Reinforcement Learning Algorithms(Component)
Reinforcement Learning (RL) is a machine learning approach where an agent
learns to make optimal decisions by interacting with an environment. Instead of
being explicitly programmed, the agent learns from experience through a trial-and-
error process.
60.
Working of ReinforcementLearning
• Observation: The agent observes the current state of the
environment.
• Action Selection: The agent selects an action based on its policy.
• Reward Feedback: The environment provides a reward based on the
action.
• Update: The agent updates its policy to maximize cumulative
rewards over time.
• Repeat: Steps 1–4 are repeated until the agent learns the optimal
strategy.
61.
Key Components ofReinforcement Learning
• Agent: The decision-maker that takes actions (e.g., a robot, self-
driving car, game AI).
• Environment: The world where the agent interacts (e.g., a road for
self-driving cars, a chessboard for AI).
• State (S): The current condition of the agent in the environment
(e.g., a robot’s position, the game’s score).
• Action (A): The possible moves the agent can take (e.g., turn left,
move forward, pick up an object).
• Reward (R): A numerical score given as feedback:
- Positive rewards (+) encourage good actions.
- Negative rewards (-) discourage bad actions.
62.
Key Components ofReinforcement Learning
• Policy: The strategy the agent follows to decide which action to take.
• Value Function (V): Estimates how good a state is for long-term
rewards.
• Q-Function (Q): Estimates the expected future reward for taking a
particular action in a given state.
63.
How Reinforcement LearningWorks?
• Agent observes the current state (S)
• Agent selects an action (A) using its policy
• Agent receives a reward (R) from the environment
• Agent updates its strategy (policy) to maximize future rewards
• Repeats until it learns the best policy
Goal: Maximize the total reward over time.
64.
Example: Teaching aRobot to Walk
Imagine we have a robot learning to walk.
• State (S): Robot's current position
• Actions (A): Move left, move right, stay still
• Reward (R):
+10 for moving forward
-10 for falling down
Learning Process:
1. The robot starts randomly moving.
2. It falls and gets a negative reward (-10).
3. It moves forward and gets a positive reward (+10).
4. Over time, the robot learns that moving forward increases
rewards, while falling down decreases rewards.
5. After multiple trials, the robot discovers the best way to walk
(optimal policy).
65.
Types of ReinforcementLearning Algorithms
Model-Free vs. Model-Based RL:
• The agent knows how the environment works (e.g., chess).
Example: AlphaGo (AI that plays Go).
Model-Free RL:
• The agent doesn’t know how the environment works and learns
through trial and error.
Example: Self-driving cars (learning traffic behavior).
66.
Value-Based vs. Policy-BasedRL
Value-Based RL:
• The agent learns the value of each state and picks the best one.
• Uses Q-learning (estimates Q-values for actions).
Policy-Based RL:
• The agent learns directly the best policy to follow.
• Uses Deep Policy Gradient methods.
Actor-Critic Method:
• Combines both Value-Based and Policy-Based RL.
67.
Popular RLAlgorithms
1. Q-Learning(Value-Based)
• The agent learns Q-values (expected future rewards for actions).
• Uses the Bellman Equation to update values.
• Example: AI playing video games.
2. Deep Q-Network (DQN)
• Uses Neural Networks to estimate Q-values.
• Solves complex RL problems.
• Example: AI that beats humans in Atari games.
3. Policy Gradient (Policy-Based)
• Learns the policy directly instead of using Q-values.
• Works well for continuous actions (e.g., robotic arm
movements).
68.
Unsupervised Learning
Unsupervised learningis a type of machine learning in which models are trained
using unlabeled dataset and are allowed to act on that data without any supervision.
Unsupervised learning cannot be directly applied to a regression or classification
problem because unlike supervised learning, we have the input data but no
corresponding output data.
Unsupervised learning models are used for three main tasks:
Clustering
Association
Dimensionality reduction
69.
Clustering
Clustering is anunsupervised learning technique that groups similar data points
into clusters based on their features. The goal is to find hidden patterns or
structures in the data without needing labeled outputs.
Working Clustering
• Identifying natural groupings in data.
• Reducing data dimensionality for easier analysis.
• Discovering anomalies or unusual patterns (e.g., fraud detection).
• Preprocessing step for other algorithms like classification.
70.
Types of Clustering
1.K-Means Clustering:
• Partitions data into K clusters by minimizing the variance within each
cluster.
• Simple and effective for spherical clusters.
2. Hierarchical Clustering:
• Creates a tree-like structure (dendrogram) showing how clusters merge or
split.
• Can be Agglomerative (bottom-up) or Divisive (top-down).
71.
3. DBSCAN (Density-BasedSpatial Clustering of Applications with Noise):
• Groups densely packed points and marks outliers as noise.
• Works well with irregular shapes and varying densities.
4. Gaussian Mixture Models (GMM):
• Assumes data is generated from multiple Gaussian distributions and finds
the best combination.
• Great for overlapping clusters.
72.
5. Mean Shift:
•Shifts data points towards the densest regions to identify clusters.
• Doesn’t require specifying the number of clusters beforehand.
73.
K-Means clustering:
K-Means isan unsupervised learning algorithm used for clustering
data into K groups based on feature similarity. It minimizes the distance
between points and their cluster centroid.
How K-Means Works:
1. Choose K (number of clusters).
2. Initialize K centroids randomly.
3. Assign each data point to the nearest centroid.
4. Recalculate centroids (average of points in each cluster).
5. Repeat steps 3-4 until centroids don’t change or reach a stopping criterion.
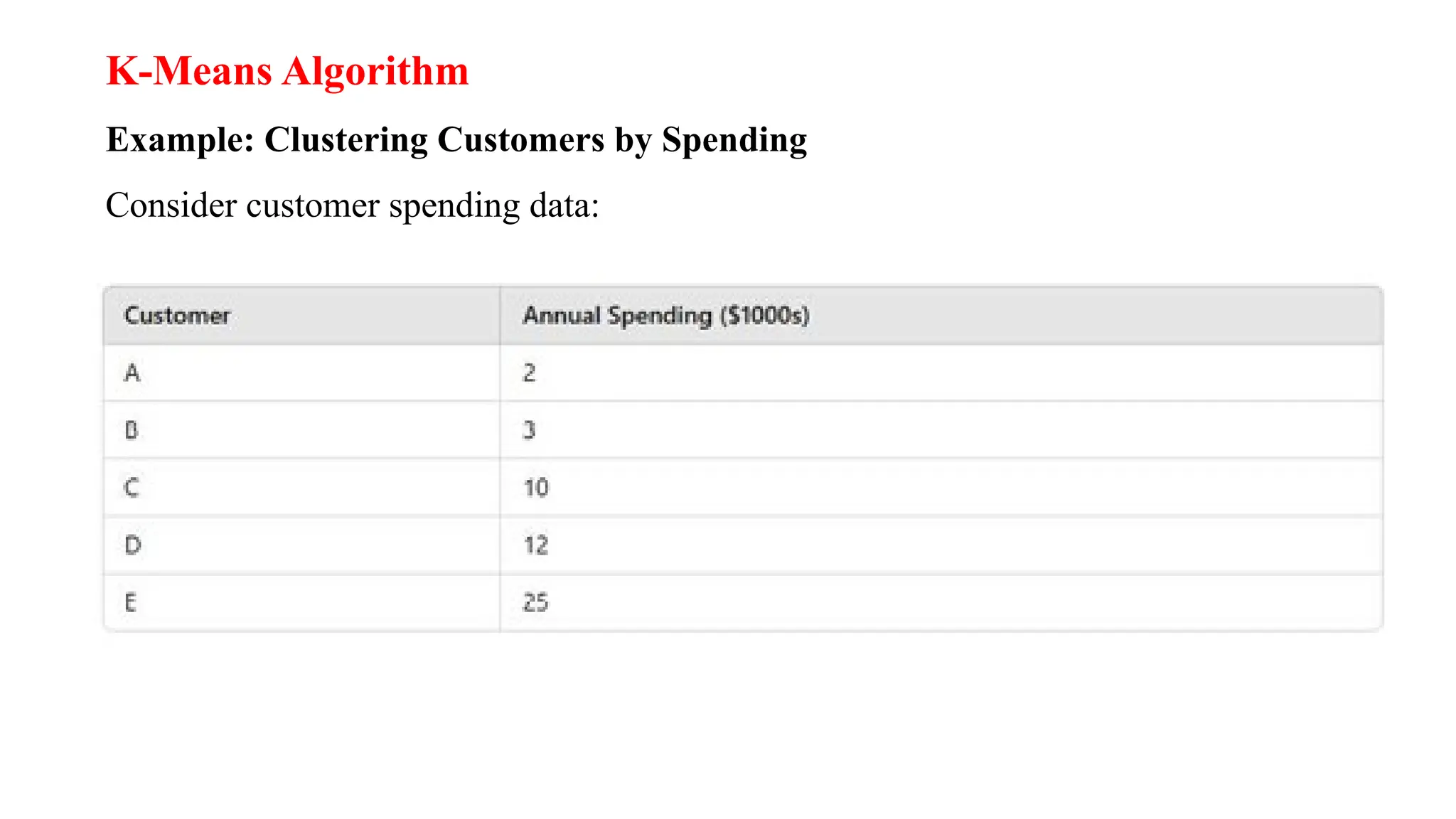
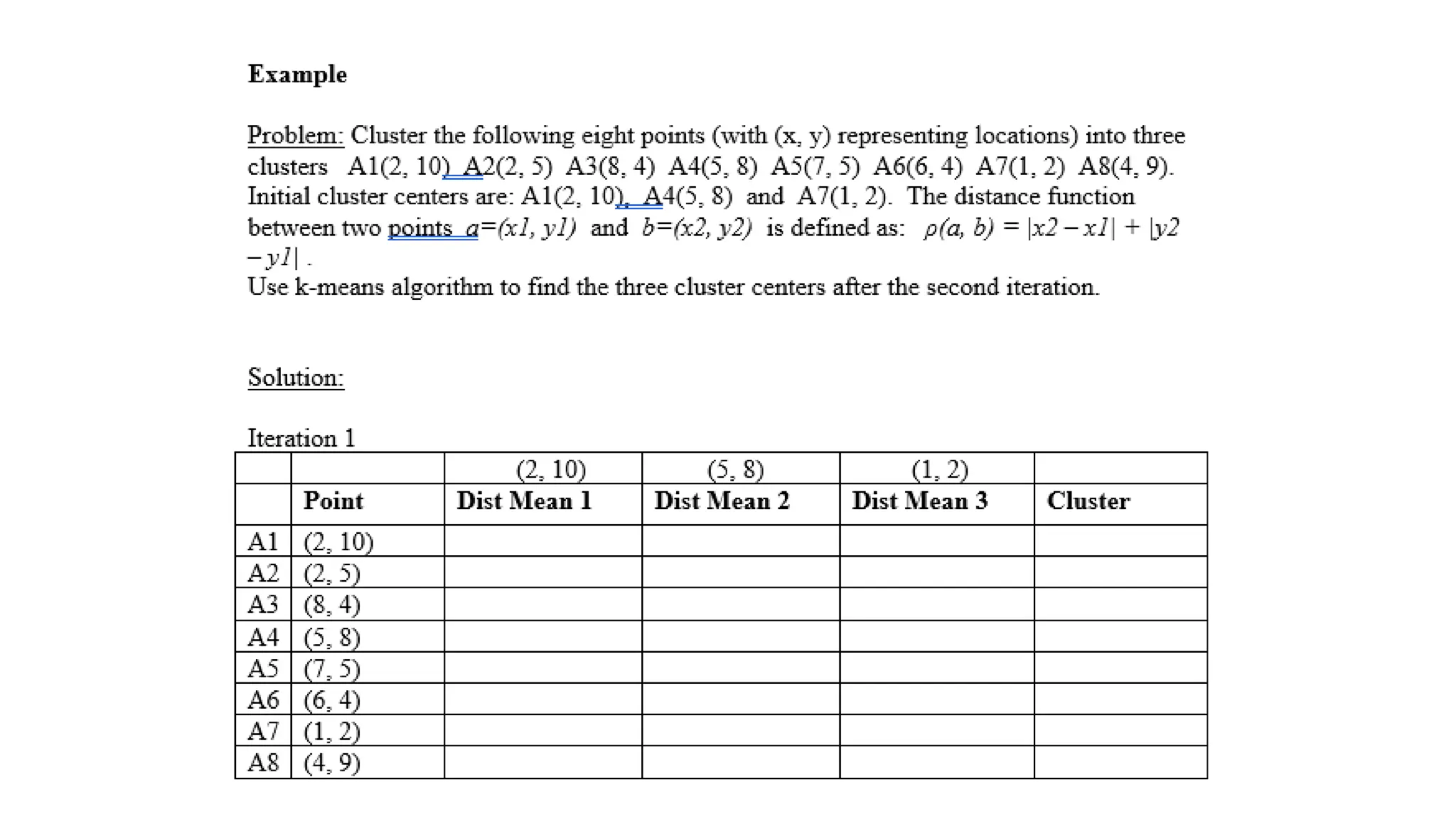
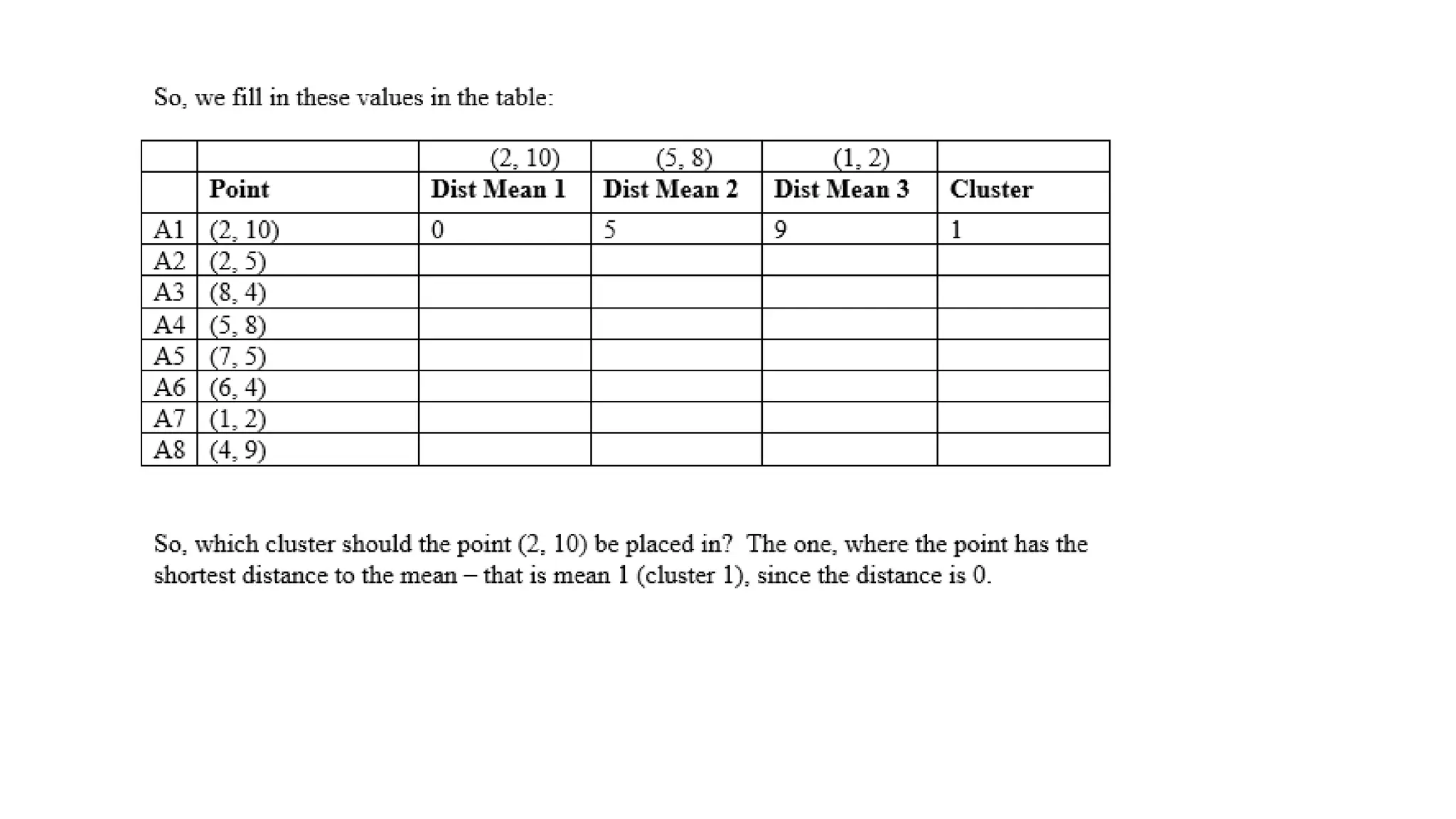
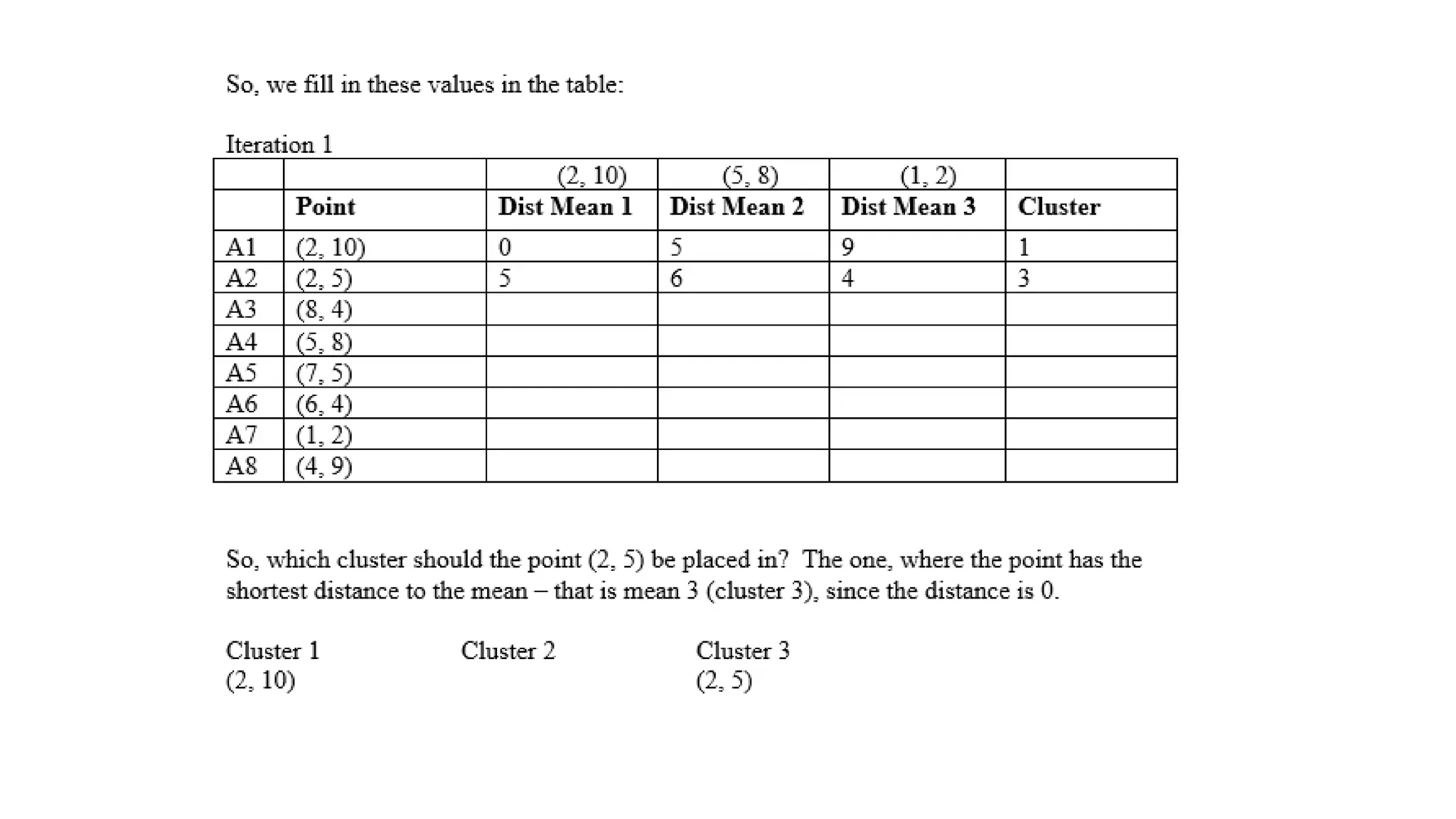
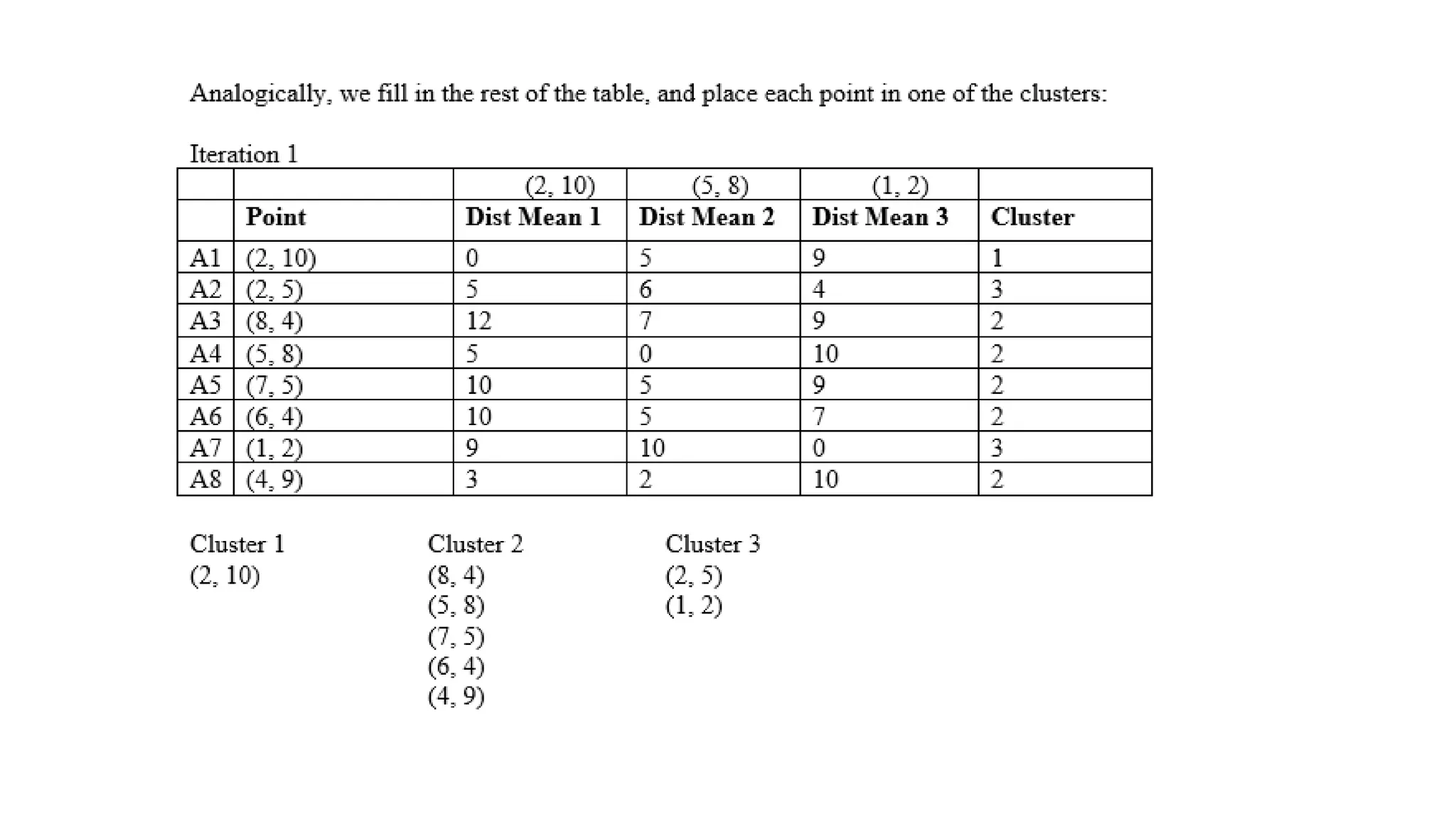
Step 1: ChooseK (e.g., K = 2)
• Initialize two centroids randomly, say at 3 and 12.
Step 2: Assign Points to Nearest Centroid
• Points closer to 3 Cluster 1:{A,B}
• Points closer to 12 Cluster 2: {C,D,E}
Step 3: Update Centroids
• New centroid for Cluster 1 = Mean(2, 3) = 2.5
• New centroid for Cluster 2 = Mean(10, 12, 25) = 15.67
Step 4: Repeat Until Convergence
• Reassign points based on new centroids.
• Update centroids until positions don’t change.
84.
Advantages:
• These algorithmscan handle more complicated tasks compared to supervised
ones.
• They work on unlabeled datasets.
• Unsupervised algorithms are preferable for various tasks.
• Obtaining an unlabeled dataset is easier compared to a labeled dataset.
85.
Disadvantages:
• The outputof an unsupervised algorithm can be less accurate due to the absence
of labeled data.
• These algorithms are not trained with the exact output before hand.
• Working with unsupervised learning is more difficult as it deals with unlabeled
datasets.
• Unlabeled data does not have a direct mapping to the output, making analysis
more challenging.
86.
Applications of UnsupervisedLearning :
Network Analysis: Unsupervised learning is used for identifying plagiarism and
copyright in document network analysis of text data for scholarly articles.
Recommendation Systems: Recommendation systems widely use unsupervised
learning techniques for building recommendation applications for different web
applications and e- commerce websites.
Anomaly Detection: Anomaly detection is a popular application of unsupervised
learning, which can identify unusual data points within the dataset. It is used to
discover fraudulent transactions.
87.
Association
Association is anothertype of unsupervised learning method that uses different
rules to find relationships between variables in a given data set. These methods are
frequently used for market basket analysis and recommendation engines, along the
lines of “Customers Who Bought This Item Also Bought” recommendations.
• Example: Compressing image data for faster processing
• Algorithms: PCA (Principal Component Analysis), t-distributed Stochastic
Neighbor Embedding (t-SNE), Non-negative Matrix Factorization (NMF),
Isomap, Locally Linear Embedding (LLE), Latent Semantic Analysis (LSA) and
Autoencoders
88.
Dimensionality Reduction:
Di9msnsionality reductionis a learning technique that is used when the number of
features (or dimensions) in a given data set is too high. It reduces the number of
data inputs to a manageable size while also preserving the data integrity. Often, this
technique is used in the preprocessing data stage, such as when autoencoders
remove noise from visual data to improve picture quality.
• Example: Market Basket Analysis (e.g., "People who buy bread also buy
butter")
• Algorithm: Apriori, FP-Growth
89.
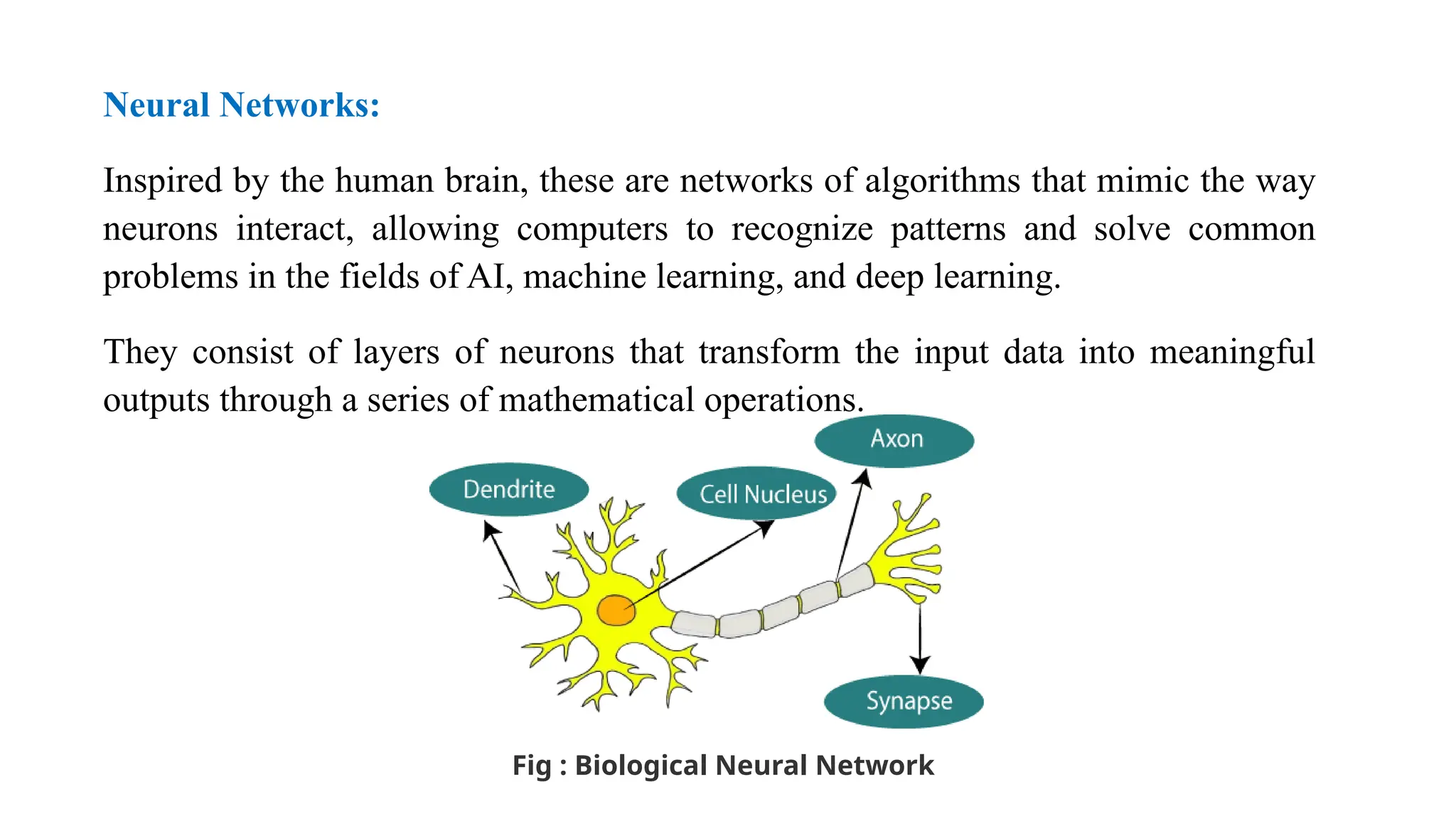
Neural Networks:
Inspired bythe human brain, these are networks of algorithms that mimic the way
neurons interact, allowing computers to recognize patterns and solve common
problems in the fields of AI, machine learning, and deep learning.
They consist of layers of neurons that transform the input data into meaningful
outputs through a series of mathematical operations.
Fig : Biological Neural Network
90.
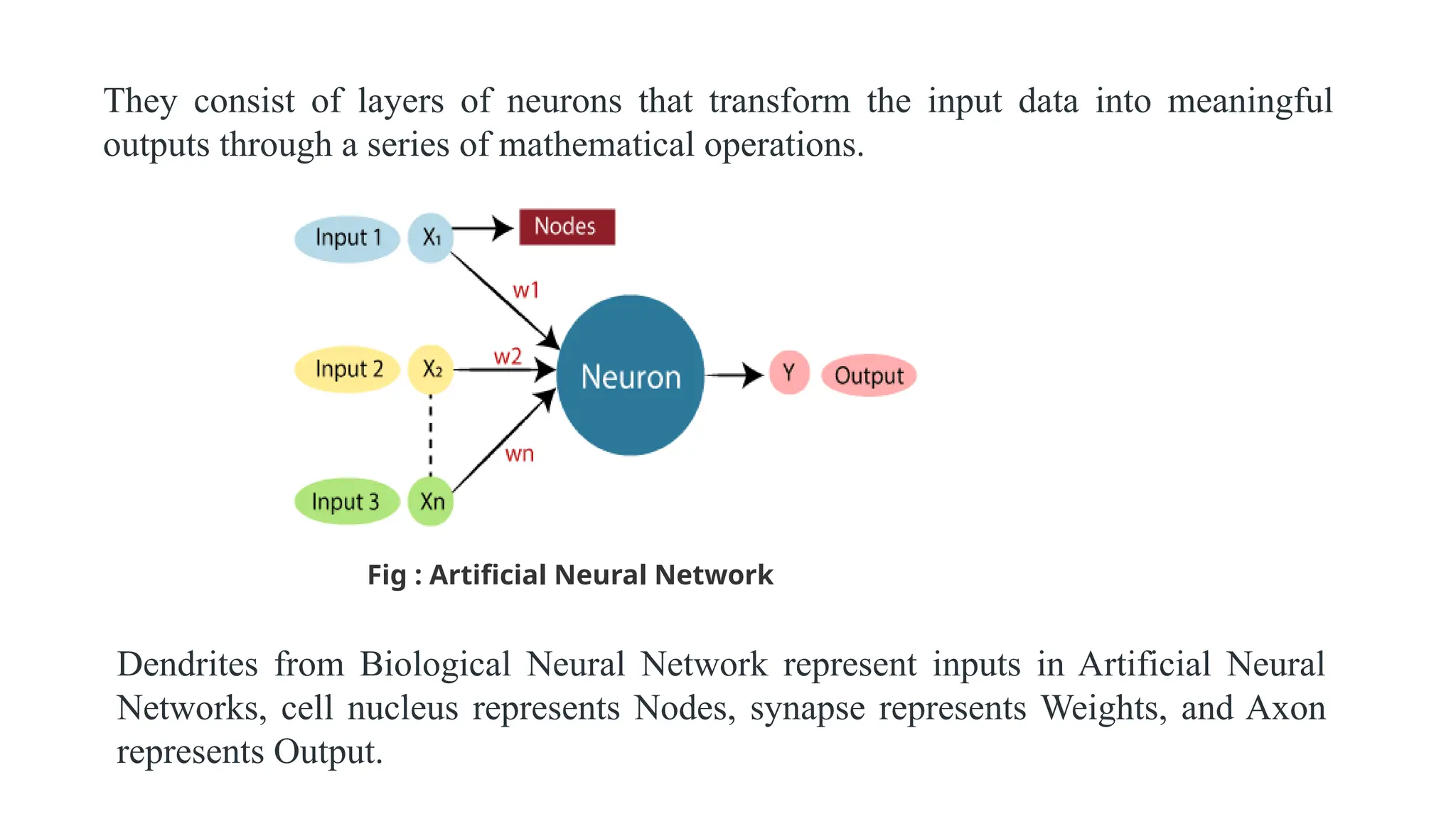
They consist oflayers of neurons that transform the input data into meaningful
outputs through a series of mathematical operations.
Fig : Artificial Neural Network
Dendrites from Biological Neural Network represent inputs in Artificial Neural
Networks, cell nucleus represents Nodes, synapse represents Weights, and Axon
represents Output.
91.
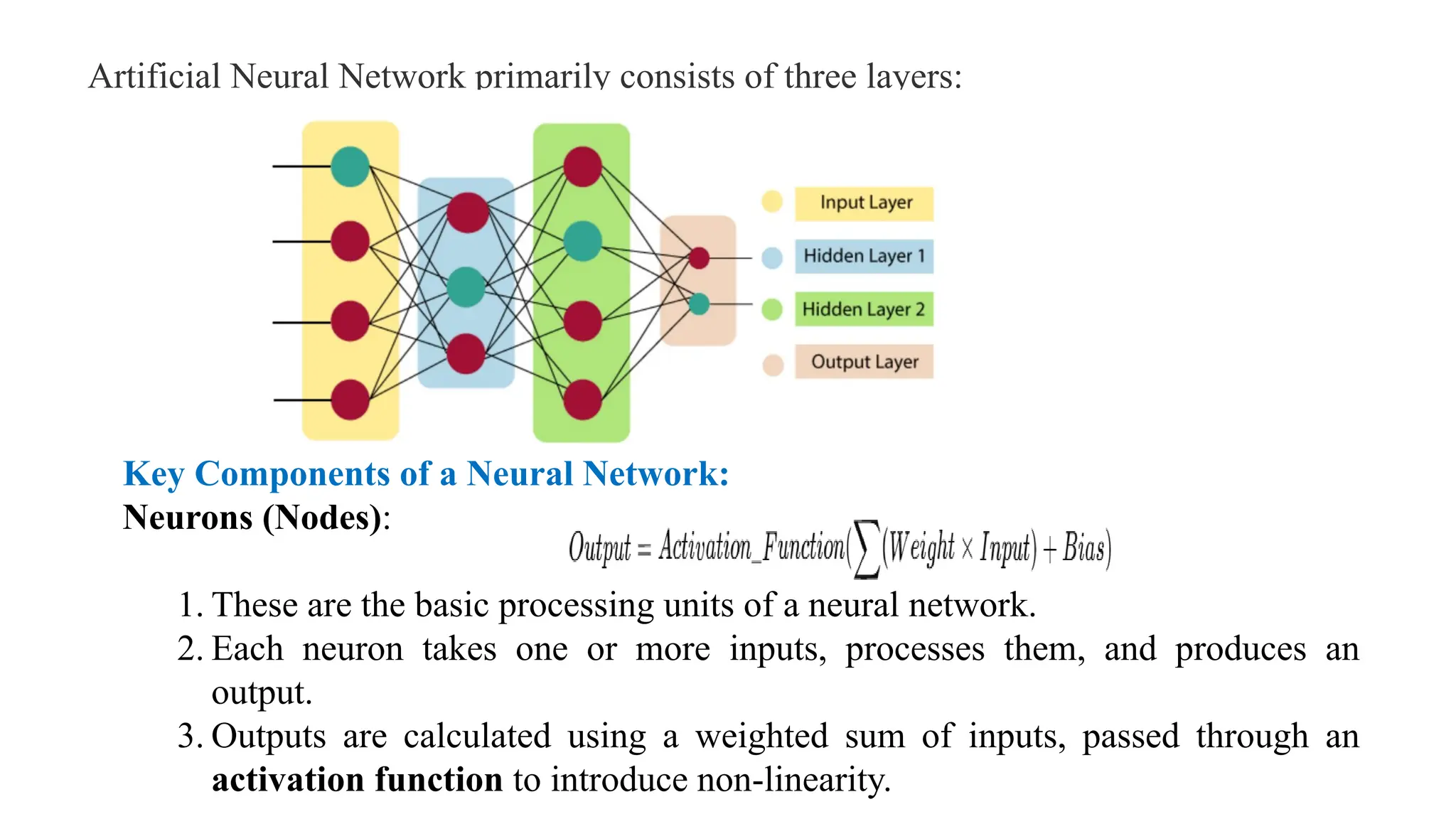
Artificial Neural Networkprimarily consists of three layers:
Key Components of a Neural Network:
Neurons (Nodes):
1. These are the basic processing units of a neural network.
2. Each neuron takes one or more inputs, processes them, and produces an
output.
3. Outputs are calculated using a weighted sum of inputs, passed through an
activation function to introduce non-linearity.
92.
Layers:
1. Input Layer:The first layer that receives raw data (e.g., images, text, or
numerical data). This layer doesn't perform computations, only feeds data into
the network.
2. Hidden Layers: Layers between the input and output layers that process and
transform the data by learning patterns and features. The number of hidden
layers and the number of neurons in each layer determine the network's depth
and capacity.
3. Output Layer: The final layer that provides the desired prediction or
classification.
The number of neurons in this layer depends on the specific task. For
example:
Binary classification: 1 neuron (often with a sigmoid activation function).
Multiclass classification: Neurons equal to the number of classes (often
with a softmax activation function).
93.
Weights:
• Weights arenumerical values associated with the connections between
neurons in a neural network.
• Represent the strength of the connection between neurons.
• They determine how much importance a neuron gives to each input.
• Adjusted during training to minimize errors and improve performance.
Biases:
• Bias is an additional constant value added to the weighted sum of inputs. It
helps the network shift the activation function's output to better fit the data.
• They allow the network to shift the activation function, enabling it to better fit
the data.
94.
Scenario: Predicting ExamScores Based on Study Hours
Step 1: Simple Formula
The relationship between a student's exam score (y) and the number of hours they
study (x) can be represented as: y = (w.x) + b
Where:
w: Weight (how much 1 hour of study impacts the score).
b: Bias (base score, even if the student doesn’t study at all).
x: Input (number of study hours).
Step 2: Example Calculation
w = 10 : Each hour of study adds 10 points to the score.
b = 20: The base score when the student doesn’t study is 20 points.
If the student studies for x = 5 hours, the predicted score (y) is: y = (10 . 5) + 20 =
50 + 20 = 70
So, the predicted score is 70.
95.
Step 3: AdjustingWeights and Bias
If the predictions are inaccurate (e.g., actual scores are lower or higher than
predicted),
you need to:
- Adjust (w) (Weight): To better reflect how study hours impact scores.
- Adjust (b) (Bias): To improve the base score for zero study hours.
This adjustment is typically done during training using historical data of study hours
and actual scores.
In Summary:
- Weight : Determines how much studying influences the score.
- Bias : Accounts for a base score, even without studying (e.g., natural ability).
96.
Activation Function
• Inneural networks, an activation function is a mathematical function applied to
the output of a neuron in order to introduce non-linearity into the model.
• Without this non-linearity feature, a neural network would behave like a linear
regression model, no matter how many layers it has. Linear models can't handle
complex patterns in data.
• This non-linearity allows the network to learn and model complex data patterns
and relationships, which is critical for solving tasks like classification, regression,
and other machine learning problems.
• Each neuron computes a weighted sum of the inputs and adds a bias term. This
sum is then passed through an activation function, which decides the output of the
neuron.
97.
Types of ActivationFunctions:
• Linear Activation Function
• Non-Linear Activation Function
Sigmoid (Logistic) Function
Tanh (Hyperbolic Tangent) Function
ReLU (Rectified Linear Unit)
Softmax Function, ELU (Exponential Linear Unit)
98.
Loss Function: Measuresthe error between predicted and actual output.
Backpropagation & Optimization: Adjusts weights using algorithms like gradient
descent to minimize errors.
99.
Types of NeuralNetworks
Feedforward Neural Network (FNN)
Convolutional Neural Network (CNN)
Recurrent Neural Network (RNN)
Long Short-Term Memory (LSTM)
100.
Feed Forward NeuralNetwork
• It is the simplest form of neural networks where information moves in one
direction
• It moves from the input layer through hidden layers (if any) to the output layer.
• There are no loops or feedback connections, making it ideal for tasks that don’t
require memory or sequential data processing.
Working
• Each neuron receives input, applies a weight, adds a bias, and passes the result
through an activation function to produce an output.
• This process repeats layer by layer until the final output is produced.
101.
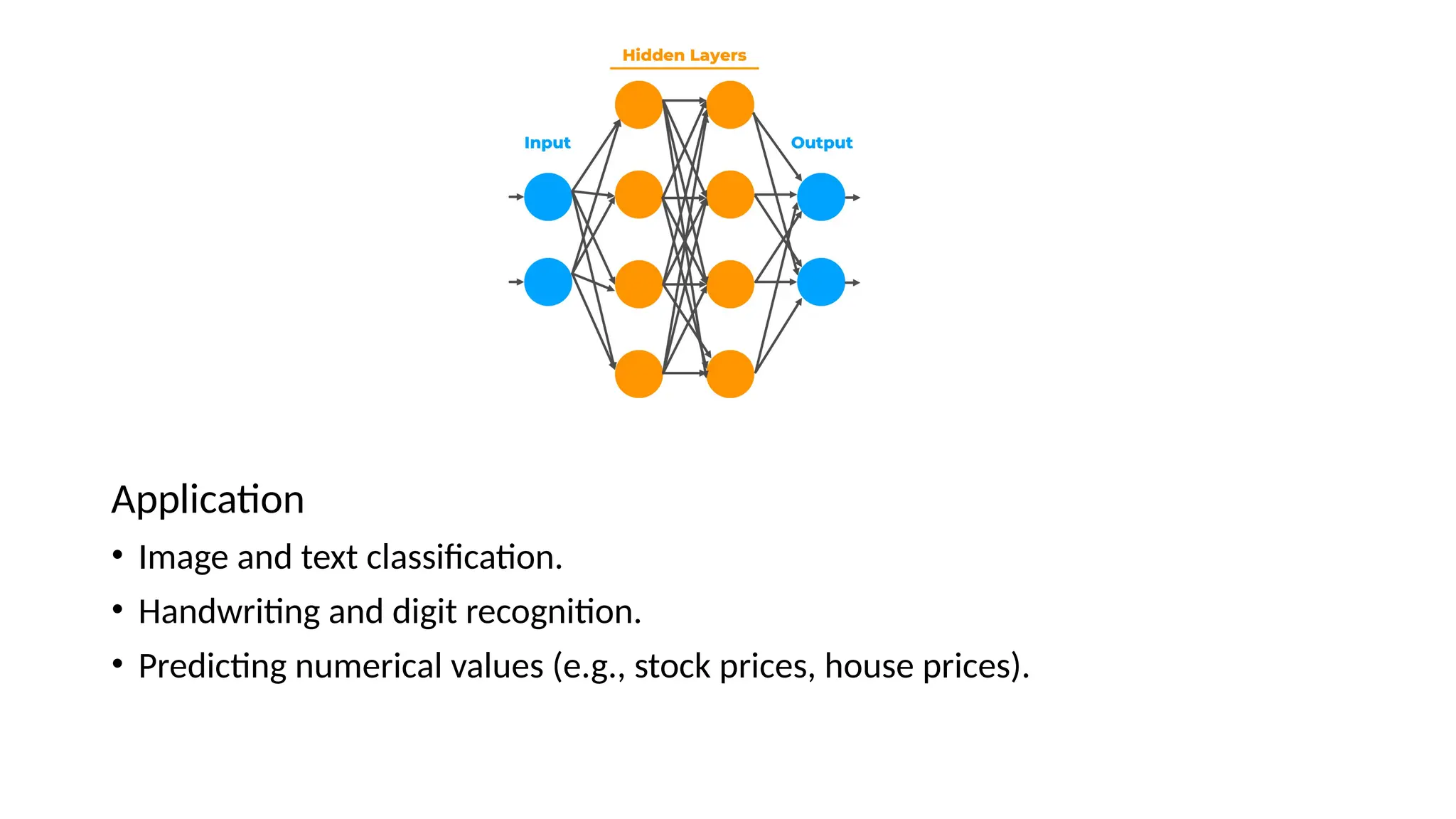
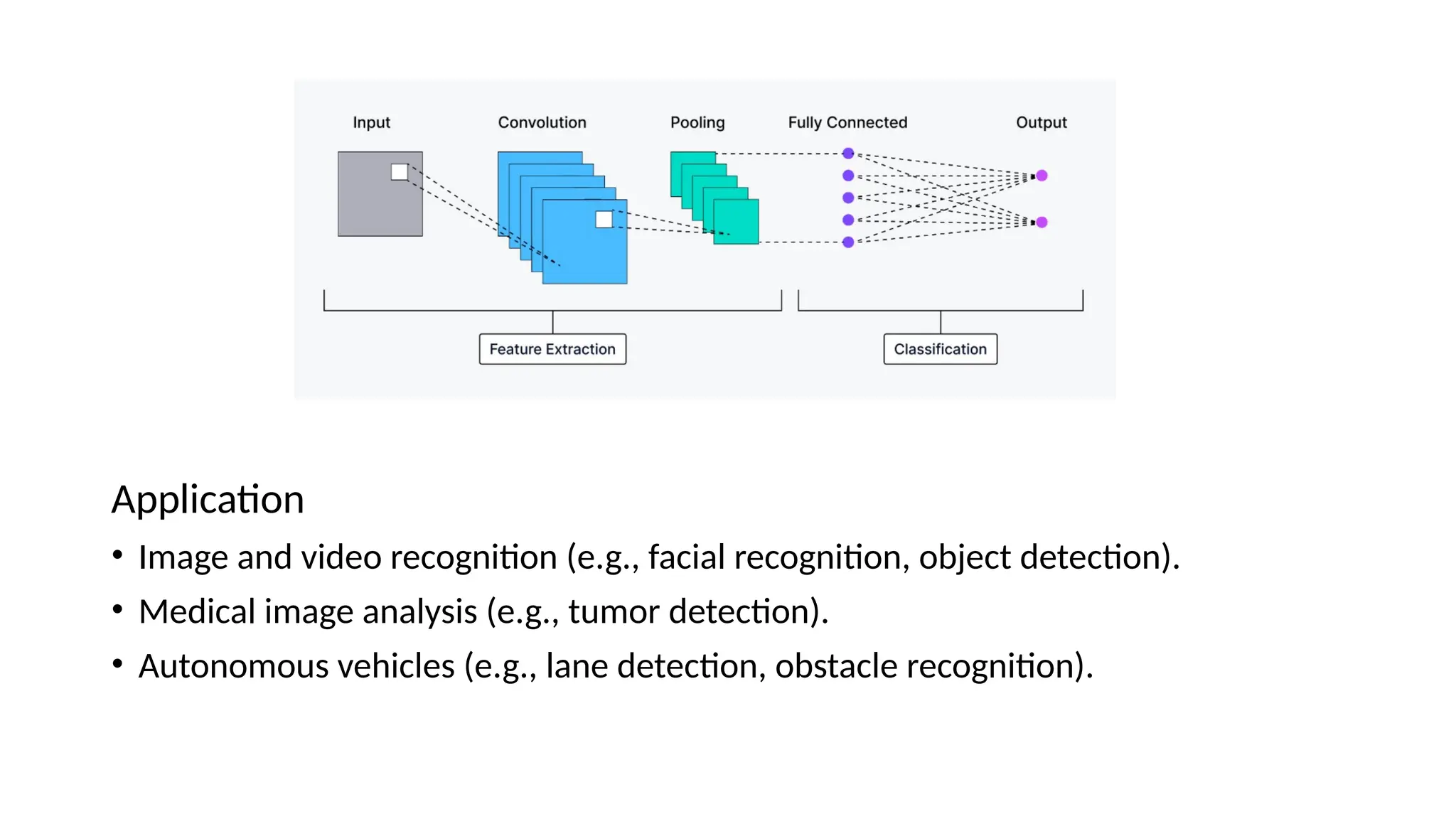
Application
• Image andtext classification.
• Handwriting and digit recognition.
• Predicting numerical values (e.g., stock prices, house prices).
102.
Advantages
• Automatic FeatureExtraction - No need for manual feature engineering.
• Translation Variance – Detects objects regardless of the position in the image.
• Parameter Sharing – Reduces the number of parameters compared to
traditional networks
• Handles Large Data Efficiently – Useful for high-dimensional image data
103.
Convolutional Neural Network
•CNNs are designed for processing grid-like data, such as images.
• They automatically learn spatial hierarchies of features through convolutional
layers, making them highly effective for visual data processing.
Working
• Convolutional Layers: Extract features like edges, textures, and patterns by sliding
small filters (kernels) over the input.
• Pooling Layers: Reduce the dimensionality of feature maps, retaining only the
most important features, which helps prevent overfitting and reduces
computational load.
• Fully Connected Layers: Take the extracted features and use them to make final
predictions (e.g., classifying an object).
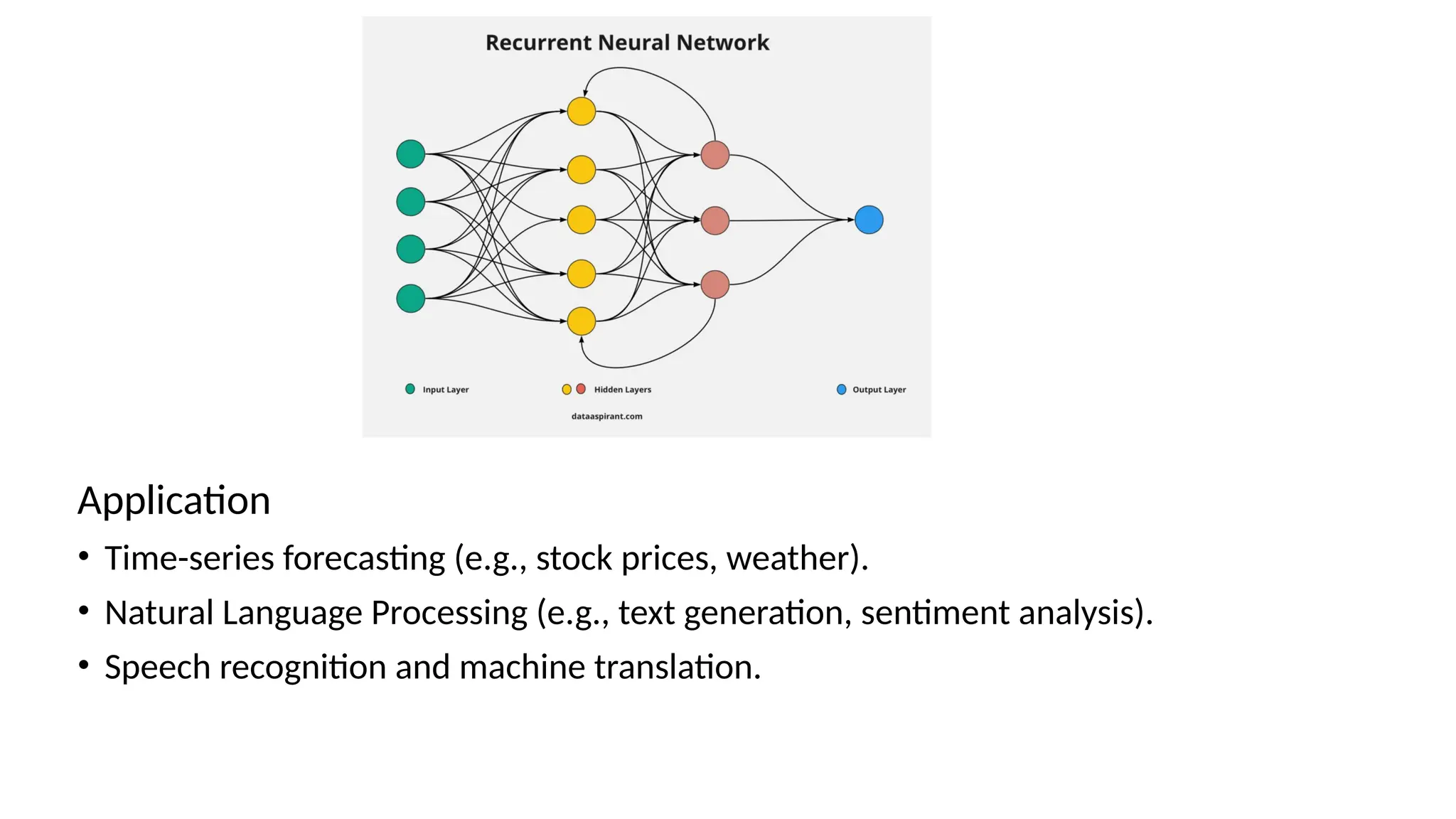
Recurrent Neural Network
•RNNs are designed to handle sequential data by introducing loops that allow
information to persist over time.
• They maintain a "hidden state" that captures information about previous time
steps, making them ideal for tasks where context matters.
Working
• Each neuron receives both the current input and the hidden state from the
previous step, allowing the network to remember past information.
• However, traditional RNNs struggle with long sequences due to the vanishing
gradient problem — where gradients shrink over time, making it hard to learn
long-term dependencies.
106.
Application
• Time-series forecasting(e.g., stock prices, weather).
• Natural Language Processing (e.g., text generation, sentiment analysis).
• Speech recognition and machine translation.
107.
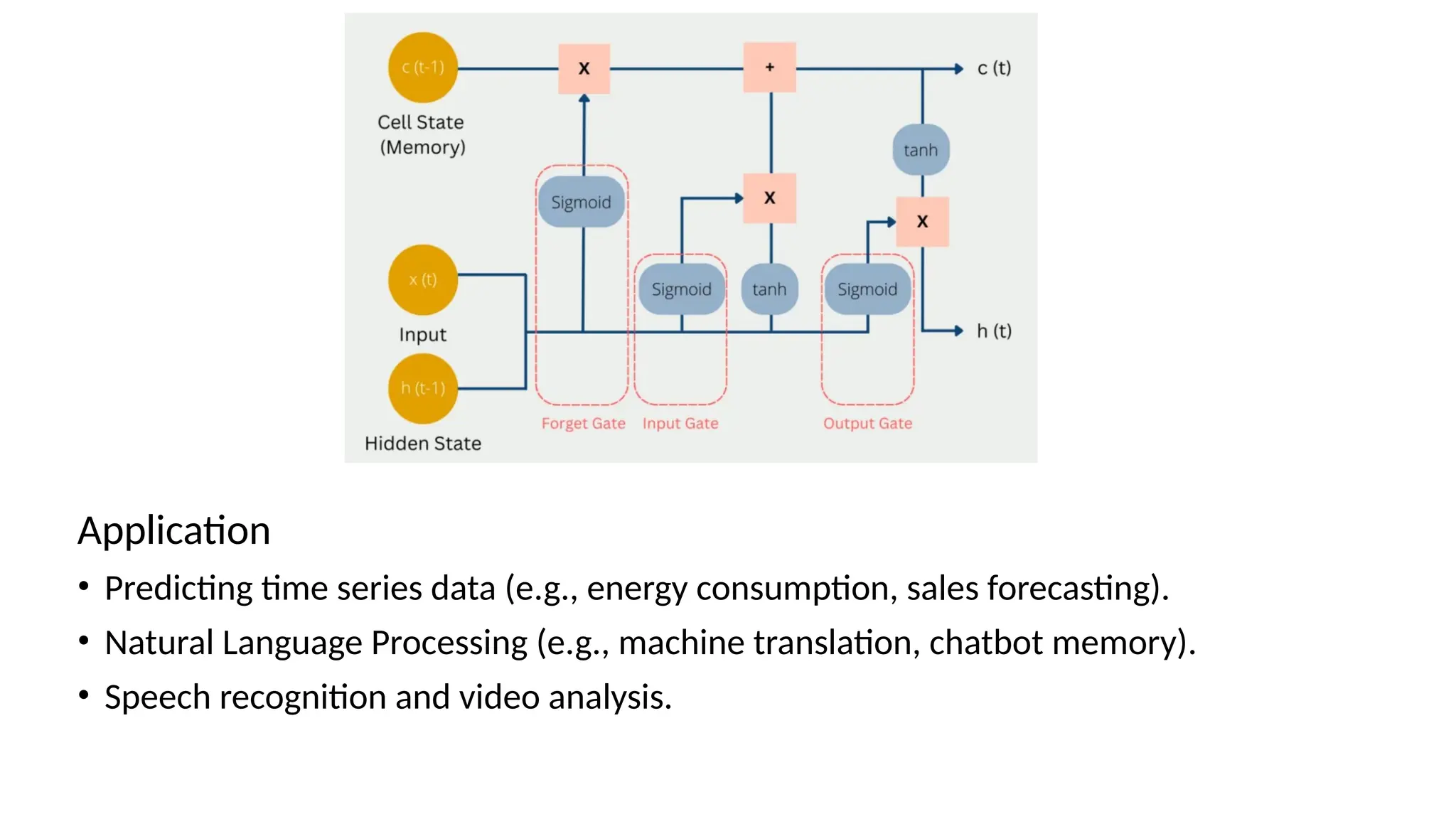
Long Short-Term Memory(LSTM)
• LSTM networks are a special kind of RNN designed to overcome the vanishing
gradient problem.
• They excel at learning long-term dependencies by introducing gates that control
what information to keep, forget, or output.
Working
• Forget Gate: Decides what information to discard from the cell state.
• Input Gate: Decides what new information to add to the cell state.
• Output Gate: Controls what part of the cell state should be output.
108.
Application
• Predicting timeseries data (e.g., energy consumption, sales forecasting).
• Natural Language Processing (e.g., machine translation, chatbot memory).
• Speech recognition and video analysis.
109.
Advanced Neural NetworkArchitecture
Modern advancements in neural networks have led to the development of more
sophisticated architectures. Two prominent examples are Generative Adversarial
Networks (GANs) and Transformer Networks, which have transformed how we
approach data generation and natural language processing.
Generative Adversarial Networks (GANs)
Structure: GANs consist of two neural networks
• Generator: Creates new data instances (e.g., images, text) that mimic real data.
• Discriminator: Evaluates the generated data to determine if it is real or fake.
Transformer Networks
Role: Transformernetworks are designed for processing sequences of data, making
them especially powerful in tasks like natural language processing (NLP) and
sequence modeling.
Key Feature: They use a mechanism called selfattention, which allows the model to
focus on relevant parts of the sequence regardless of its length. This solves the
limitations of earlier models like RNNs and LSTMs.
Deep Learning
• DeepLearning is a subset of Machine Learning (ML) that mimics the
structure and functioning of the human brain through artificial neural
networks (ANNs).
• It’s called "deep" because these networks have multiple hidden layers
between the input and output layers, enabling them to learn complex
patterns from vast amounts of data.
114.
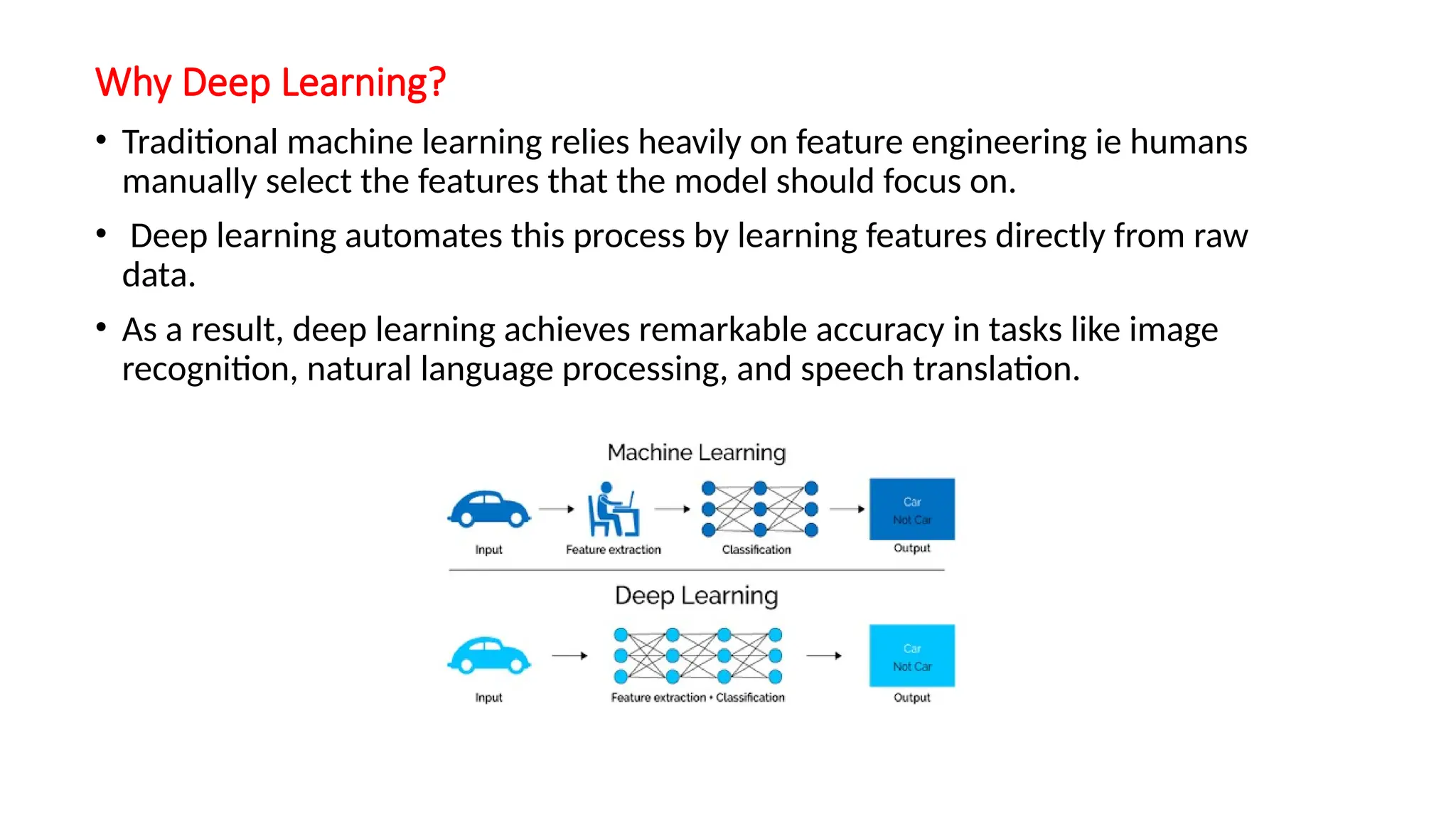
Why Deep Learning?
•Traditional machine learning relies heavily on feature engineering ie humans
manually select the features that the model should focus on.
• Deep learning automates this process by learning features directly from raw
data.
• As a result, deep learning achieves remarkable accuracy in tasks like image
recognition, natural language processing, and speech translation.
115.
Working of DeepLearning
1. Input Data Collection:
• Data can be anything: images, audio, text, or numerical data.
Example: In an image classification task, the input could be pixel
values of an image.
2.Data Preprocessing:
• Raw data is cleaned, normalized, and transformed into a suitable format.
For images: Normalize pixel values (0 to 255) to a range between 0
and 1.
For text: Convert text into numerical representations (e.g., word
embeddings).
116.
3. Neural NetworkArchitecture:
• A typical deep neural network consists of:
Input Layer: Receives the data.
Hidden Layers: Perform complex computations and extract features.
Output Layer: Produces the final prediction (e.g., image label).
4. Forward Propagation:
• Data flows through the network from input to output.
• Each neuron performs a calculation:
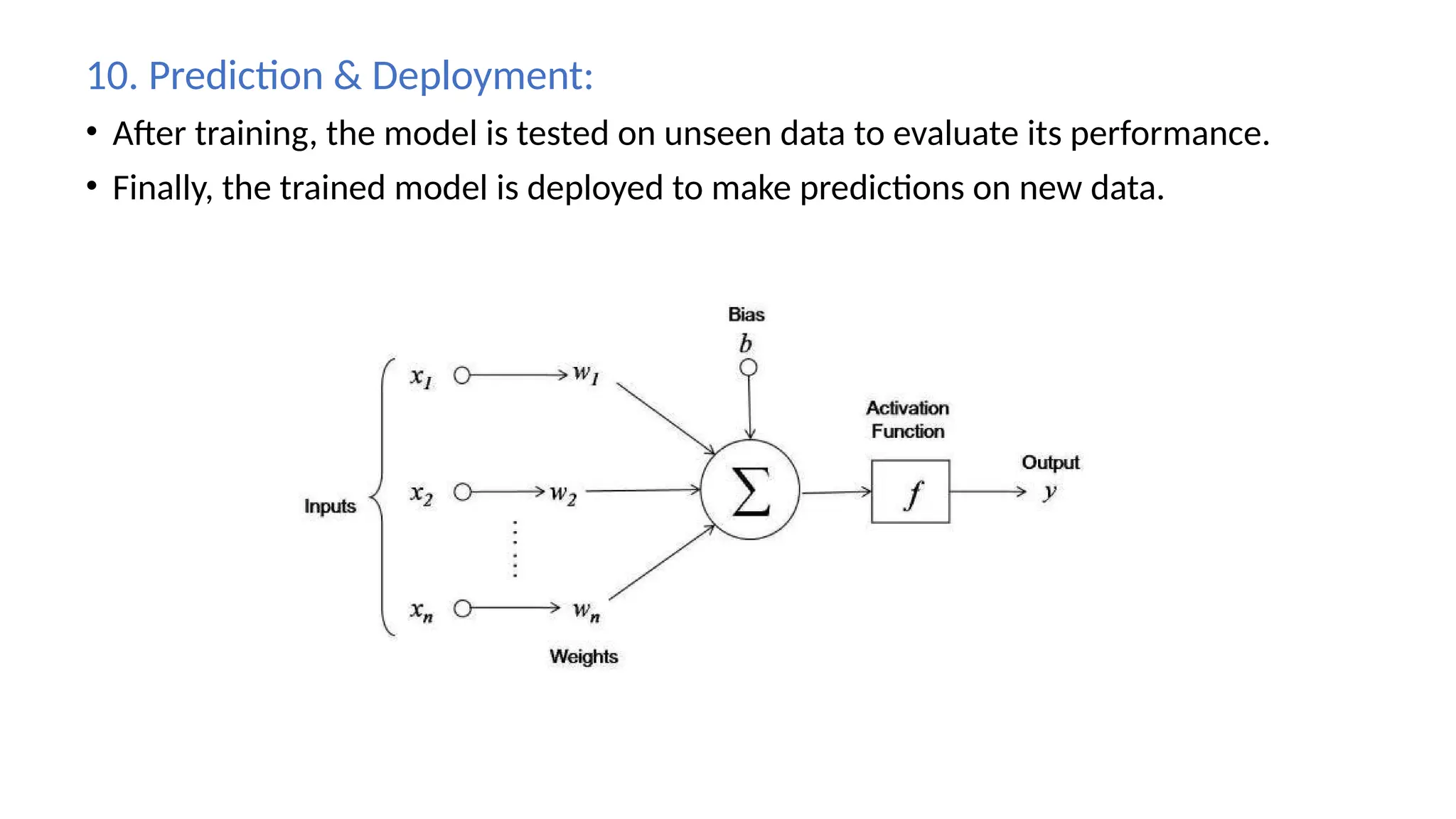
𝑍=( × )+
𝑊 𝑋 𝐵
Z = Weighted sum of inputs.
W = Weights assigned to inputs.
X = Input data.
B = Bias term.
117.
5. Activation Functions:
•Introduce non-linearity, allowing the network to learn complex patterns. Common
ones include:
• ReLU (Rectified Linear Unit): f(x)=max(0,x)
• Sigmoid: Squashes the output between 0 and 1.
• SoftMax: Used in multi-class classification to output probabilities for each class
6. Loss Calculation:
• Measures the difference between predicted and actual outputs using a Loss
Function.
• For classification: Cross-entropy loss.
• For regression: Mean Squared Error (MSE).
118.
7. Backward Propagation:
•Adjusts the model to minimize loss.
• Calculates gradients of the loss function with respect to each weight using the
chain rule, then updates the weights to reduce the error.
8. Optimization:
• Optimizers like Stochastic Gradient Descent (SGD) or Adam help fine-tune the
weights by adjusting them incrementally.
9. Iteration (Epochs):
• The process of forward and backward propagation repeats for multiple epochs
(iterations over the entire dataset) until the model reaches optimal performance.
119.
10. Prediction &Deployment:
• After training, the model is tested on unseen data to evaluate its performance.
• Finally, the trained model is deployed to make predictions on new data.
120.
Applications of DeepLearning
1. Computer vision
2. Natural language processing (NLP)
3. Reinforcement learning
Challenges of Deep Learning
4. Data Dependency
5. High Computational Cost
6. Overfitting
7. Black Box Nature
8. Ethical Concerns
9. Energy Consumption
121.
Advantages of DeepLearning
1. Automatic Feature Extraction
2. High Accuracy
3. Handles Complex Data
4. Adaptability
5. Continuous Improvement
6. Scalability
Disadvantages of Deep Learning
1. Requires Large Data
2. Computational Complexity
3. Long Training Times
4. Interpretability Issues
5. Overfitting Risk
6. Dependency on Quality Data
7. Ethical Risks
122.
Ethical Considerations ofArtificial Intelligence and Machine
Learning
1. Bias and Fairness:
• AI models can inherit biases from training data, leading to unfair outcomes.
• Example: Gender or racial bias in hiring algorithms.
2. Transparency and Explainability:
• AI systems, especially deep learning models, are often "black boxes," making it hard to
understand their decision-making process.
• Solution: Develop Explainable AI (XAI) methods to provide insights into decisions.
123.
3. Privacy andData Security:
• AI requires large datasets, raising concerns about unauthorized access and misuse of
personal data.
• Solution: Implement data encryption, anonymization, and comply with regulations like
GDPR.
4. Accountability and Responsibility:
• Unclear who is responsible when AI makes a mistake — the developer, the company, or
the AI itself?
• Solution: Establish legal and ethical guidelines for AI accountability.
5. Job Displacement and Economic Impact:
• Automation powered by AI can replace human workers, leading to unemployment.
• Solution: Implement reskilling programs to help workers transition to new roles.
124.
6. Misinformation andManipulation:
• AI can create deepfakes or fake news, influencing public opinion and spreading
misinformation.
• Solution: Develop AI-based detection tools to identify fake content.
7. Environmental Impact:
• Training AI models consumes vast energy, contributing to a higher carbon footprint.
• Solution: Optimize models to be more energy-efficient and use renewable energy.