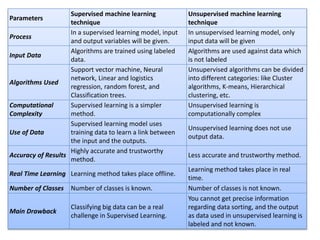
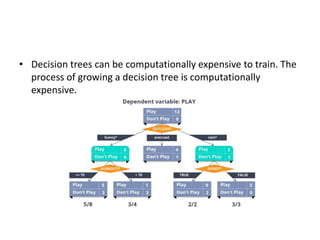
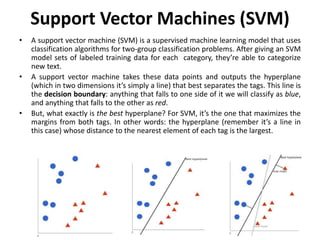
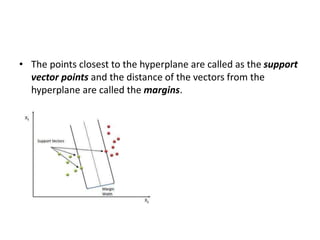
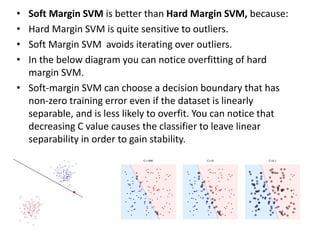
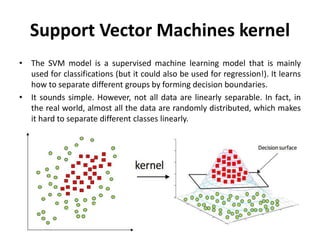
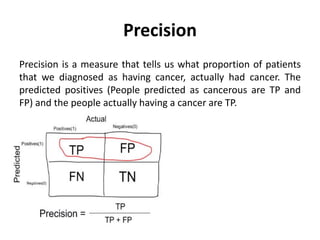
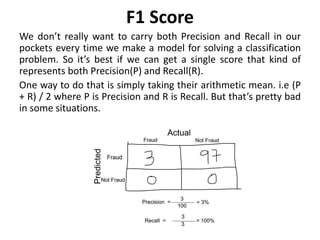
Supervised learning uses labeled training data to predict outcomes for new data. Unsupervised learning uses unlabeled data to discover patterns. Some key machine learning algorithms are described, including decision trees, naive Bayes classification, k-nearest neighbors, and support vector machines. Performance metrics for classification problems like accuracy, precision, recall, F1 score, and specificity are discussed.