Linear Regression inML
Linear regression is one of the easiest and most popular Machine Learning
algorithms. It is a statistical method that is used for predictive analysis.
Linear regression makes predictions for continuous/real or numeric
variables such as sales, salary, age, product price, etc.
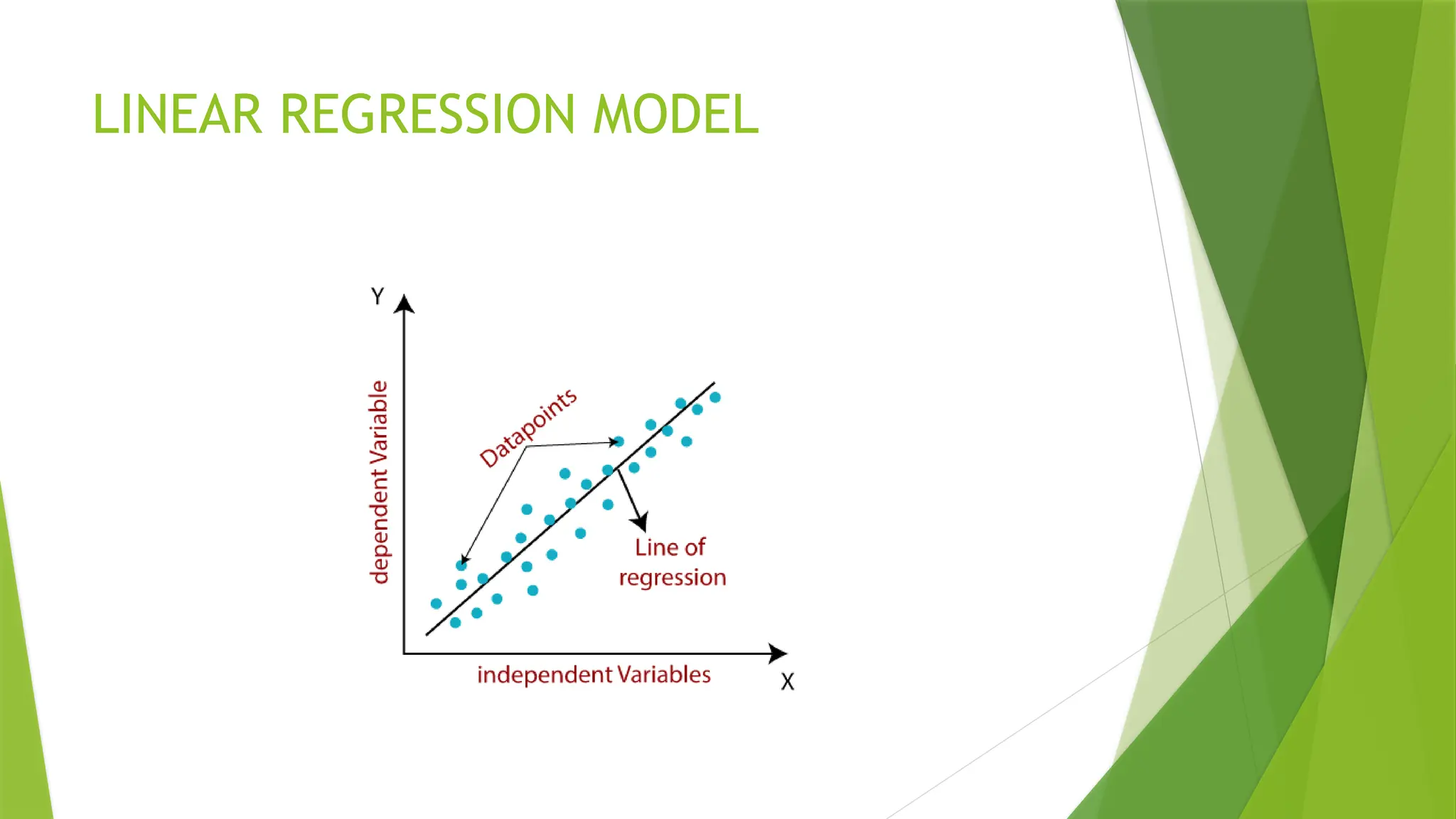
Linear regression algorithm shows a linear relationship between a
dependent (y) and one or more independent (y) variables, hence called as
linear regression.
LINEAR REGRESSION FORMULA
The measure of the extent of the relationship between two variables is
shown by the correlation coefficient. A linear regression line equation is
written in the form of:
Y = a + bX
where X is the independent variable and plotted along the x-axis
Y is the dependent variable and plotted along the y-axis
The slope of the line is b, and a is the intercept (the value of y when x = 0)
5.
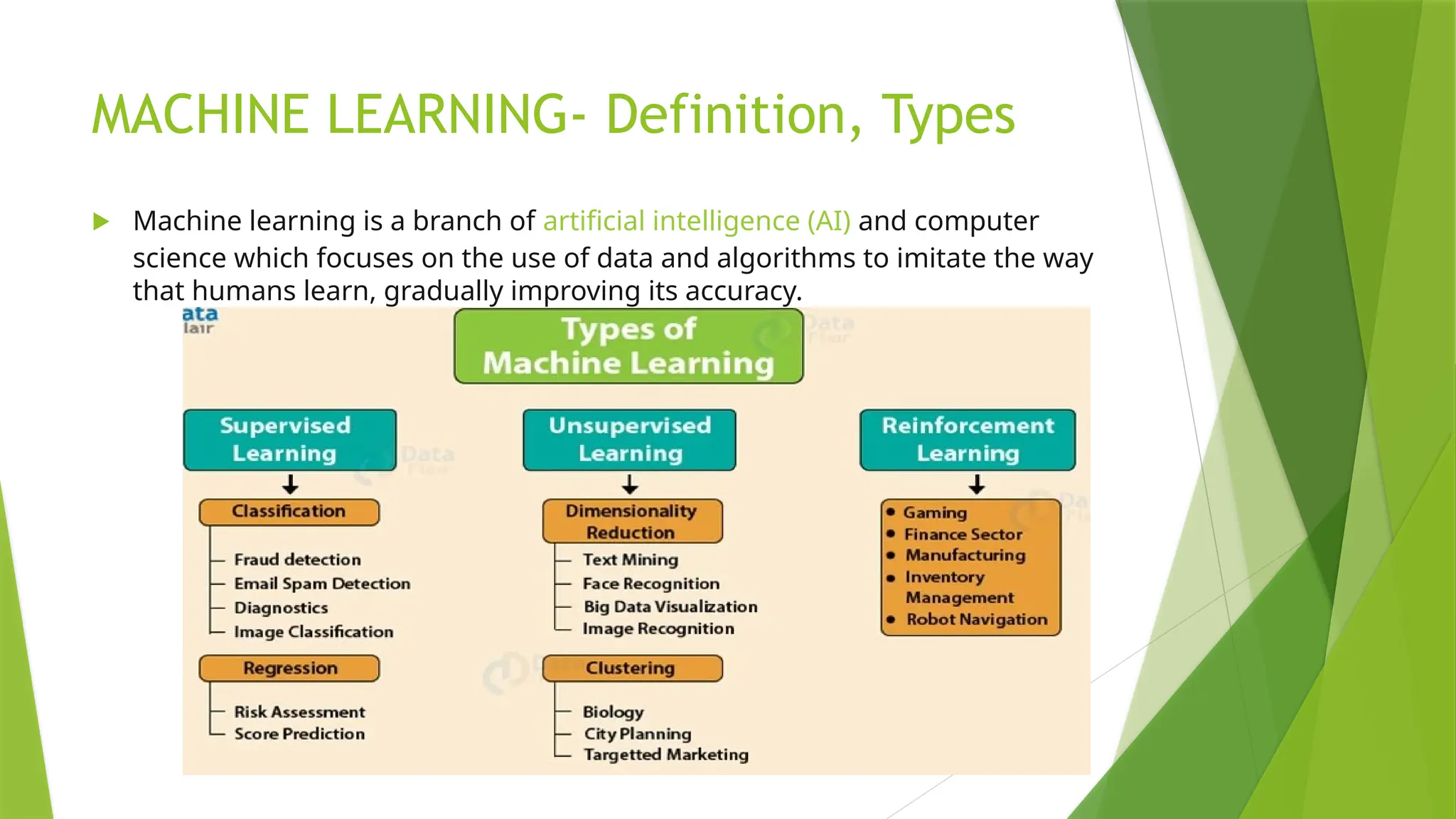
MACHINE LEARNING- Definition,Types
Machine learning is a branch of artificial intelligence (AI) and computer
science which focuses on the use of data and algorithms to imitate the way
that humans learn, gradually improving its accuracy.
6.
Inductive bias
Needto make assumptions
Experience alone doesn’t allow us to make conclusions about unseen data instances.
Two types of bias:
Restriction: Limit the hypothesis space.
Preference: Impose ordering on hypothesis
space
UNIT III SUPERVISEDLEARNING
Linear Regression Models: Least squares, single & multiple variables, Bayesian linear regression,
gradient descent, Linear Classification Models: Discriminant function – Perceptron algorithm,
Probabilistic discriminative model - Logistic regression, Probabilistic generative model – Naive
Bayes, Maximum margin classifier – Support vector machine, Decision Tree, Random Forests
9.
Linear Regression Models:
Learning:
A supervised algorithm that learns from a set of training samples.
Each training sample has one or more input values and a single output value.
The algorithm learns the line, plane or hyper-plane that best fits the training samples.
Prediction
Use the learned line, plane or hyper-plane to predict the output value for any input sample.
10.
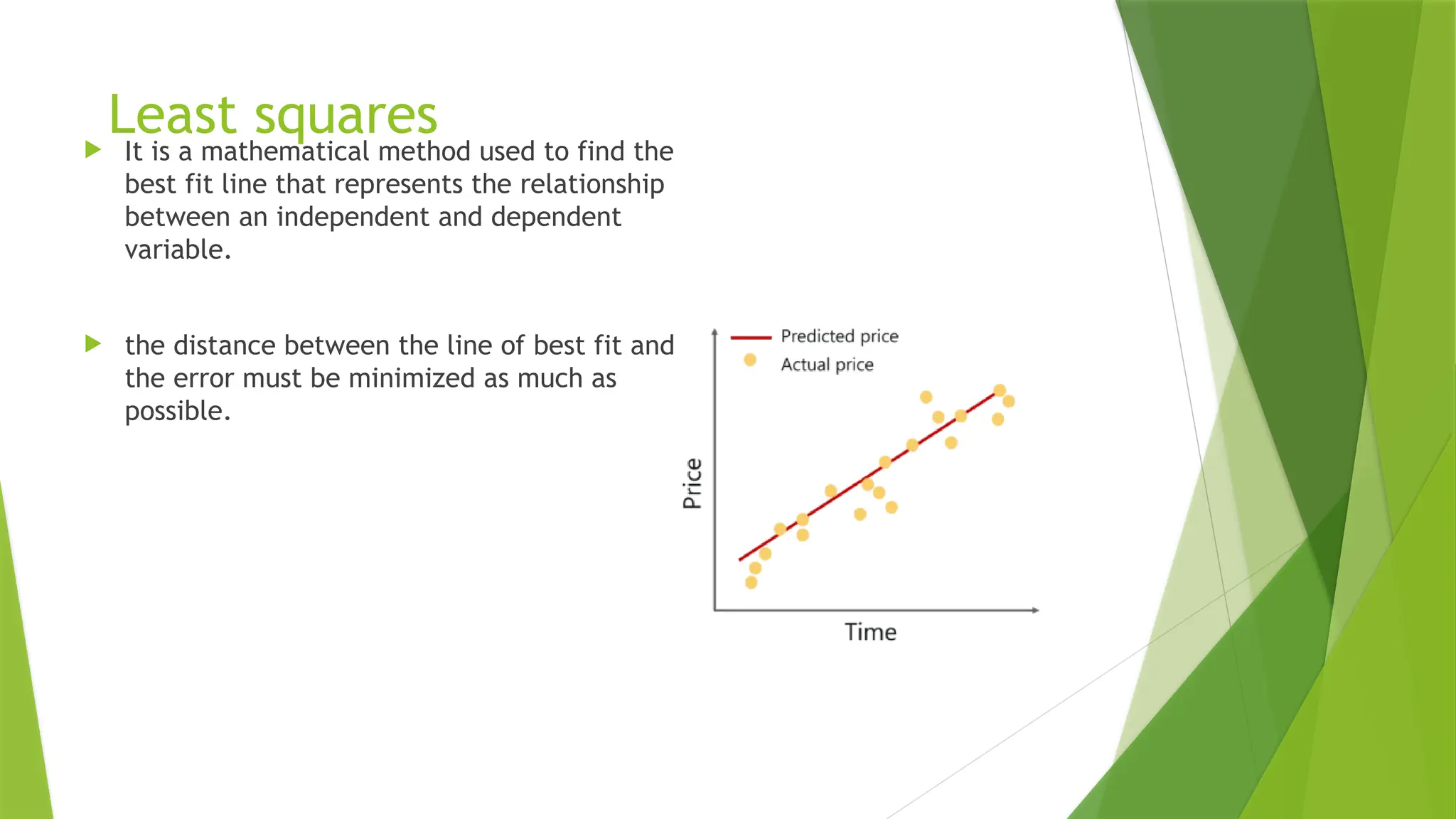
Least squares
Itis a mathematical method used to find the
best fit line that represents the relationship
between an independent and dependent
variable.
the distance between the line of best fit and
the error must be minimized as much as
possible.
11.
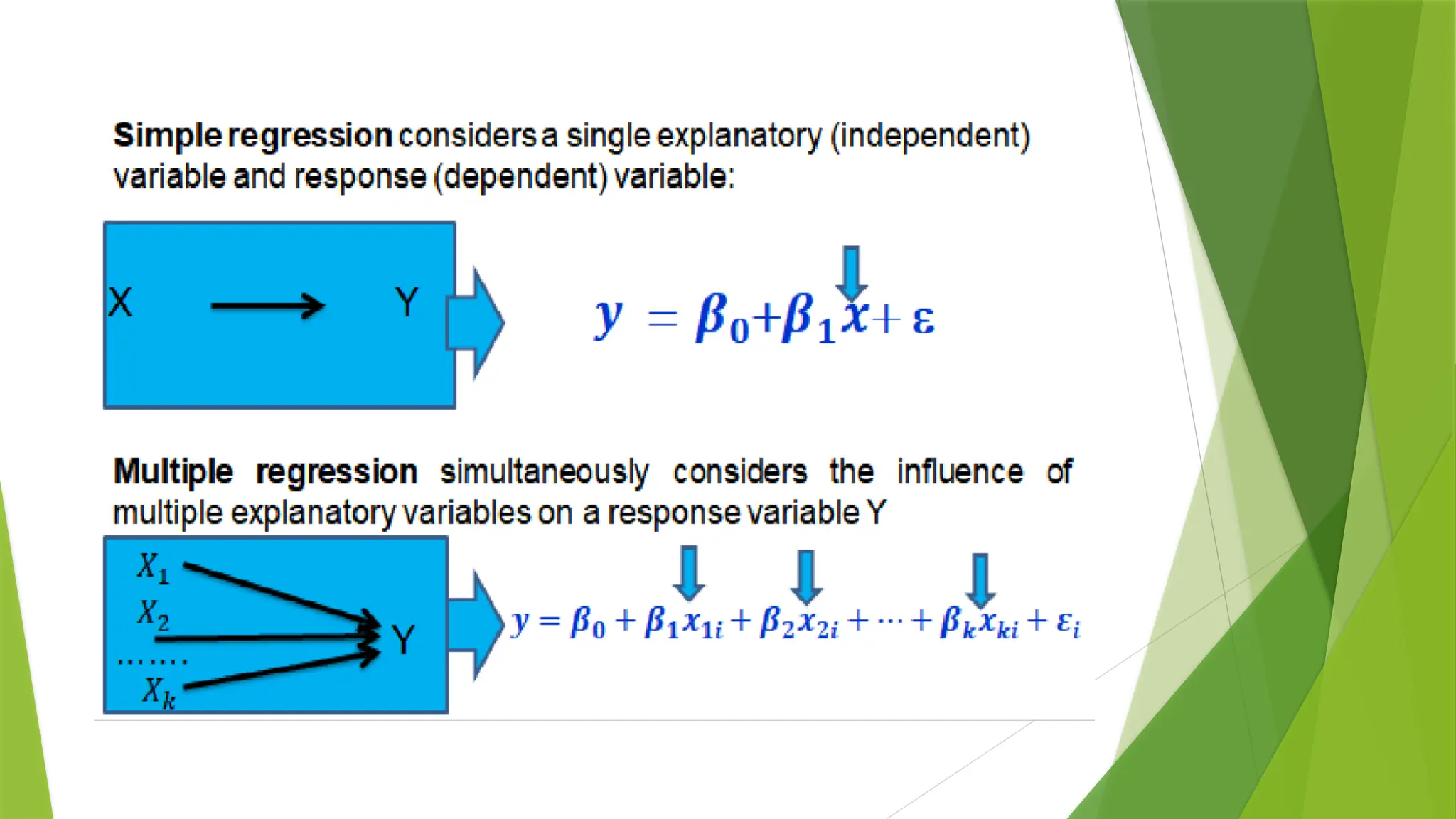
single & multiplevariables:
Single Variable Linear Regression is a technique used to model the relationship between a single input
independent variable (feature variable) and an output dependent variable using a linear model i.e a line.
12.
Multi-Variable Linear Regression
Multi-VariableLinear Regression where a model is created for
the relationship between multiple independent input
variables (feature variables) and an output dependent
variable.
14.
Bayesian linear regression
The aim of Bayesian Linear Regression is not to find the single “best” value of the model
parameters, but rather to determine the posterior distribution for the model parameters.
The posterior probability of the model parameters is conditional upon the training inputs and
outputs:
P(β|y, X) -- posterior probability distribution
P(β|X) -- prior probability of the parameters
P(y| X) -- normalization constant
15.
Two primary benefitsof Bayesian Linear Regression
Priors: If we have domain knowledge, or a guess for what the
model parameters should be, we can include them in our model,
unlike in the frequentist approach which assumes everything
there is to know about the parameters comes from the data.
Posterior: The result of performing Bayesian Linear Regression is
a distribution of possible model parameters based on the data
and the prior. This allows us to quantify our uncertainty about
the model: if we have fewer data points, the posterior
distribution will be more spread out.
16.
gradient descent
Eg: Imaginea valley and a person
with no sense of direction who
wants to get to the bottom of
the valley. He goes down the
slope and takes large steps when
the slope is steep and small steps
when the slope is less steep. He
decides his next position based
on his current position and stops
when he gets to the bottom of
the valley which was his goal.
17.
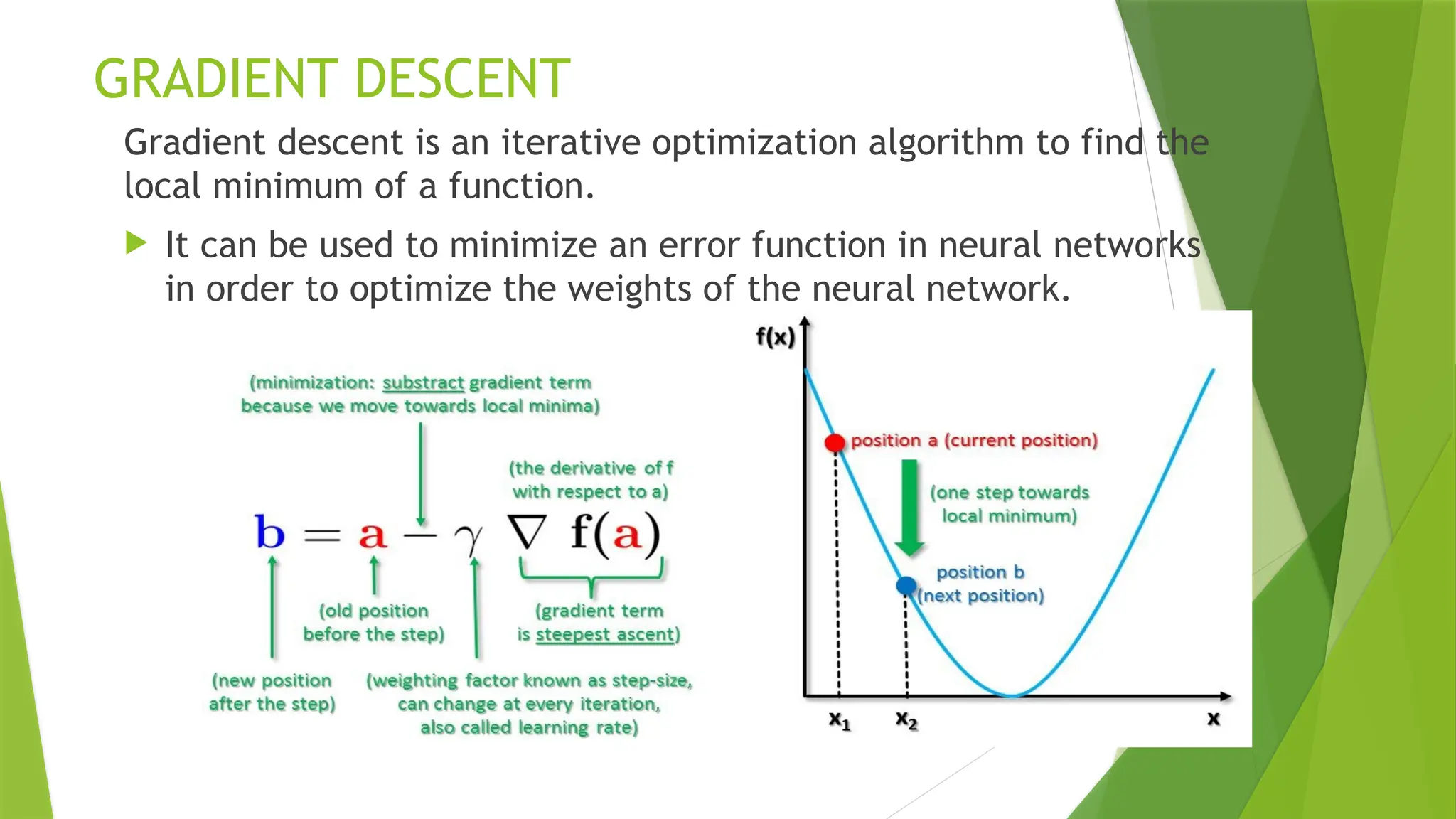
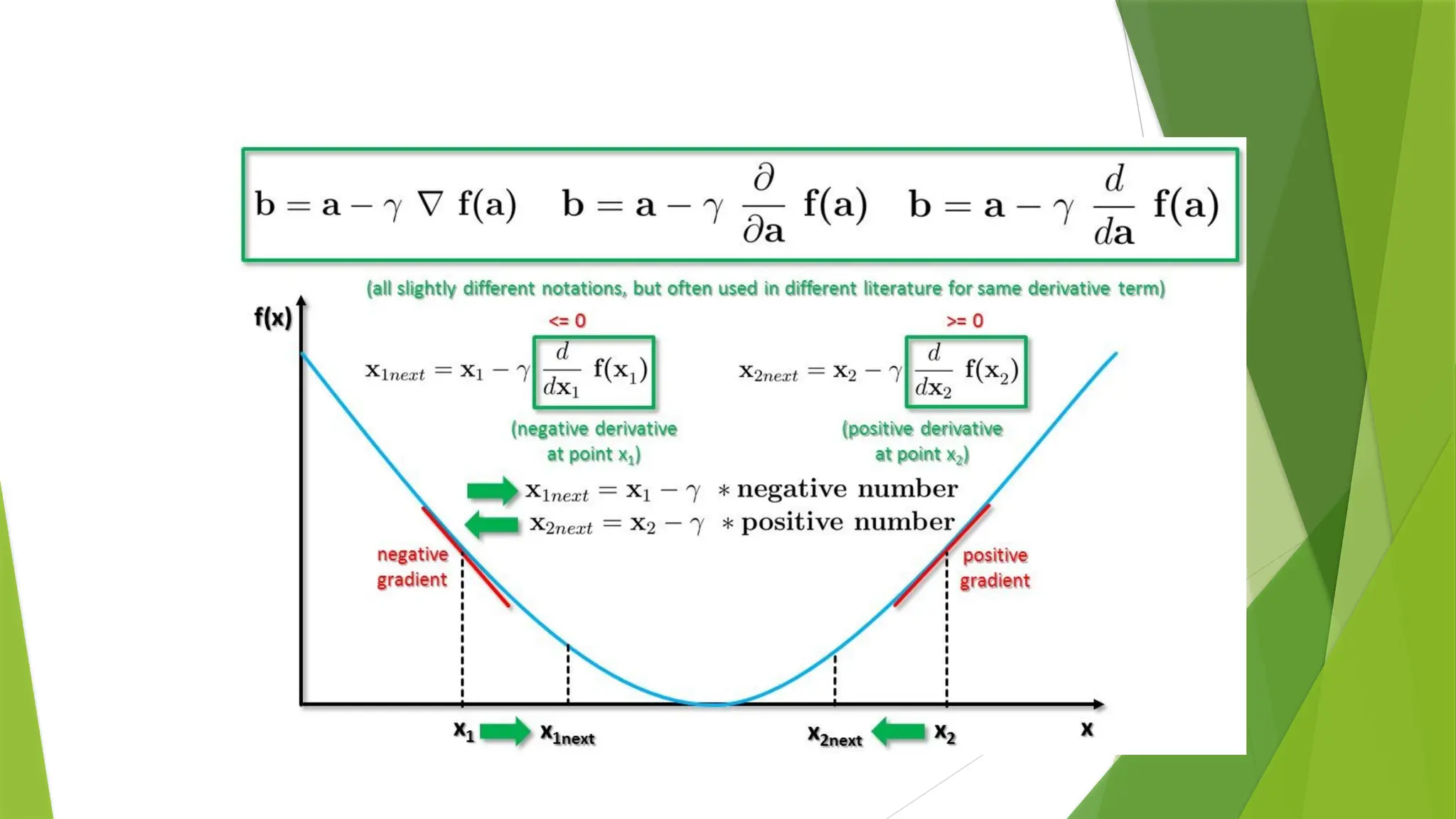
GRADIENT DESCENT
Gradient descentis an iterative optimization algorithm to find the
local minimum of a function.
It can be used to minimize an error function in neural networks
in order to optimize the weights of the neural network.
19.
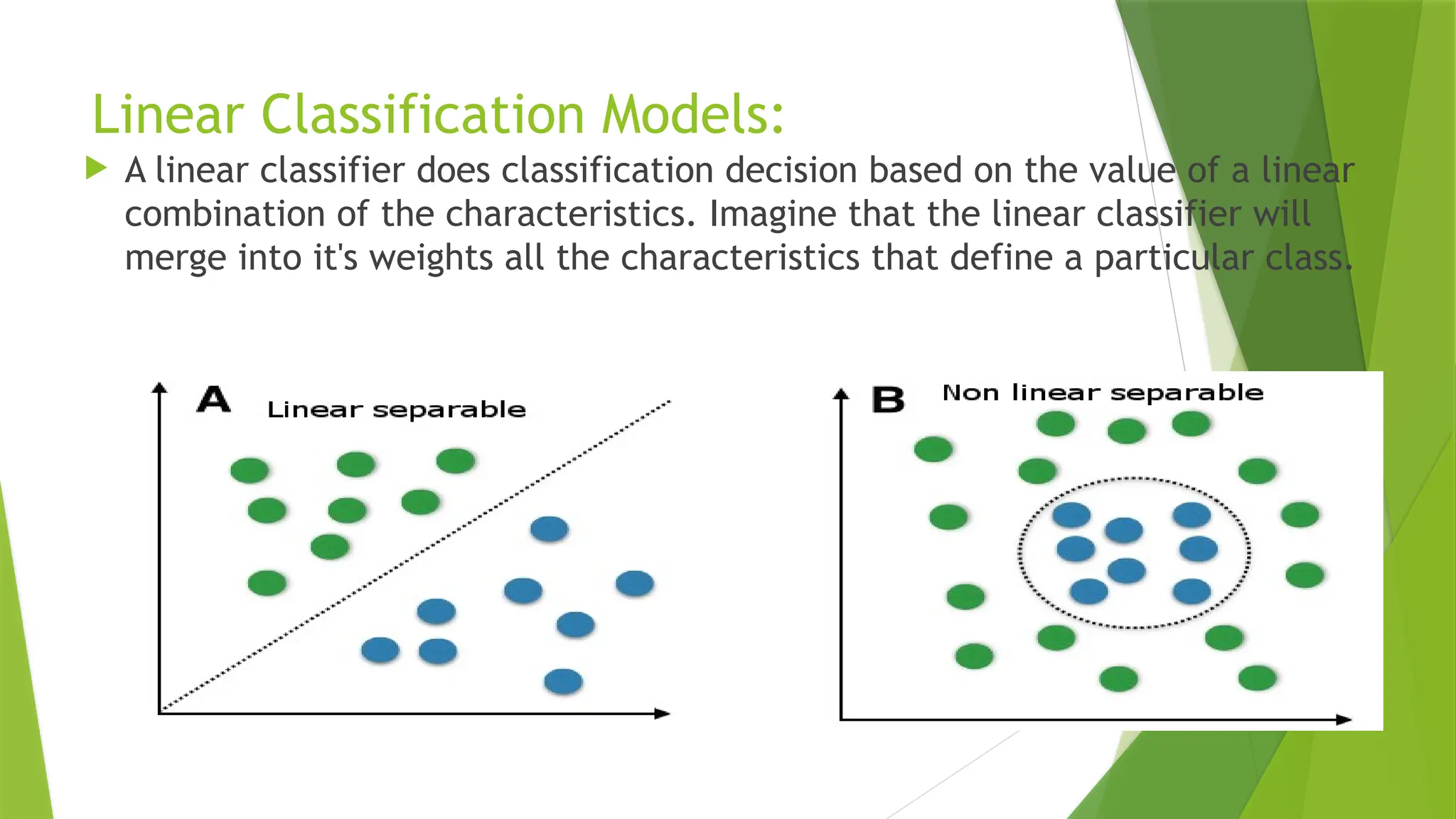
Linear Classification Models:
A linear classifier does classification decision based on the value of a linear
combination of the characteristics. Imagine that the linear classifier will
merge into it's weights all the characteristics that define a particular class.
20.
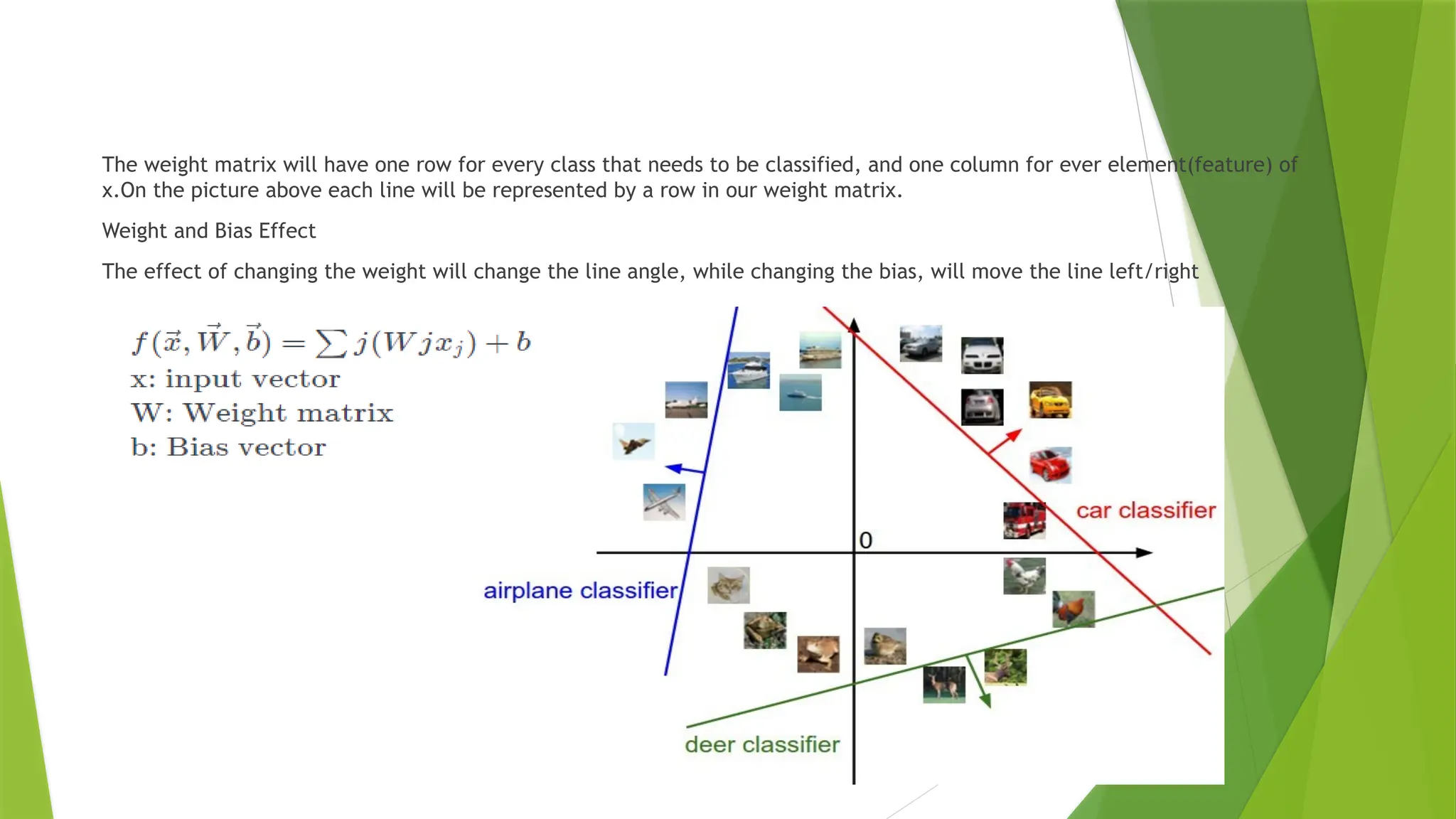
The weight matrixwill have one row for every class that needs to be classified, and one column for ever element(feature) of
x.On the picture above each line will be represented by a row in our weight matrix.
Weight and Bias Effect
The effect of changing the weight will change the line angle, while changing the bias, will move the line left/right
21.
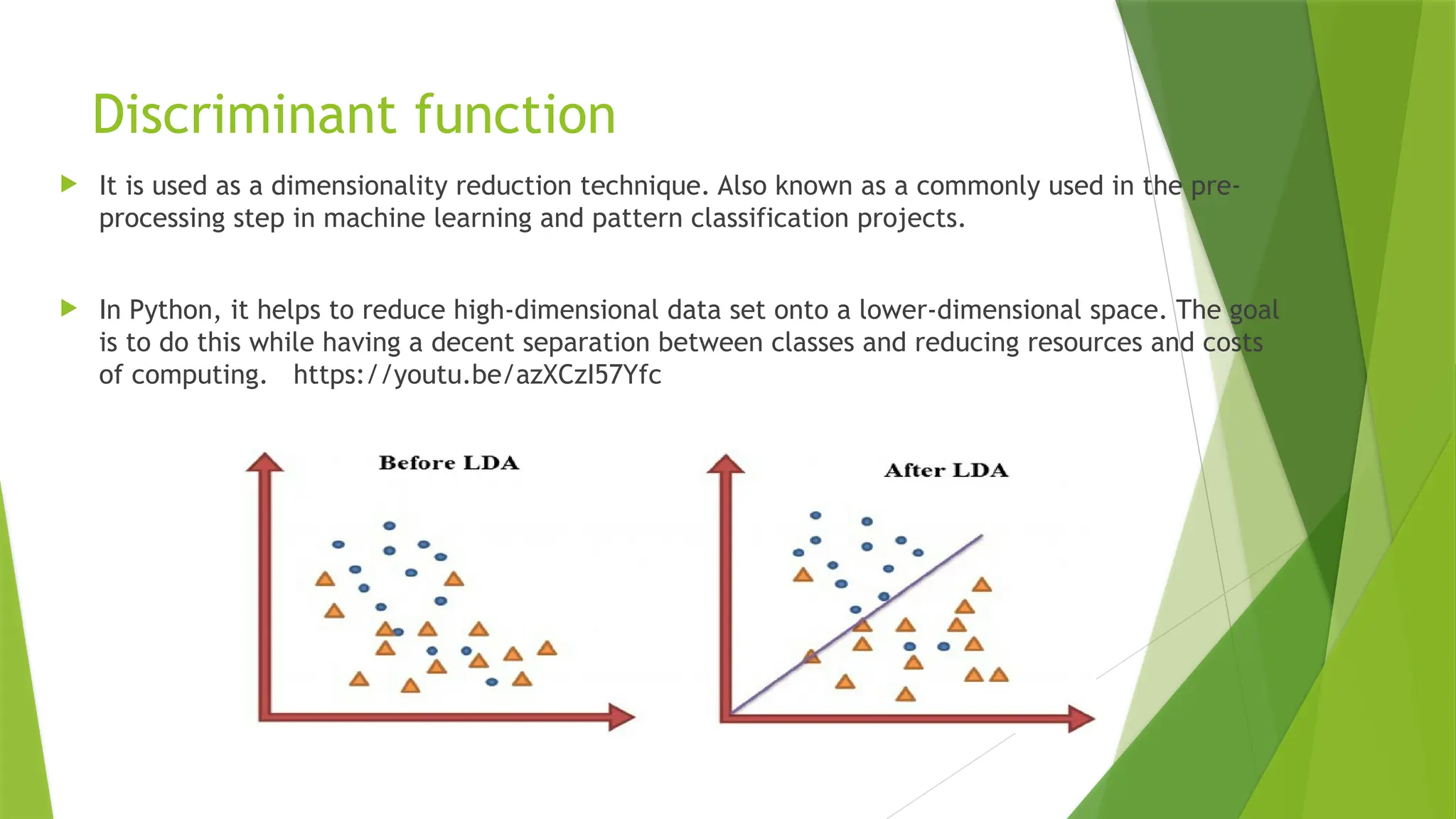
Discriminant function
Itis used as a dimensionality reduction technique. Also known as a commonly used in the pre-
processing step in machine learning and pattern classification projects.
In Python, it helps to reduce high-dimensional data set onto a lower-dimensional space. The goal
is to do this while having a decent separation between classes and reducing resources and costs
of computing. https://youtu.be/azXCzI57Yfc
22.
Linear Discriminant Analysis
three key steps.
1. Calculate the separability between different classes. This is also known as
between-class variance and is defined as the distance between the mean of
different classes.
2. Calculate the within-class variance. This is the distance between the mean and
the sample of every class.
3. Construct the lower-dimensional space that maximizes Step1 (between-class
variance) and minimizes Step 2(within-class variance). In the equation below P is
the lower-dimensional space projection. This is also known as Fisher’s criterion.
23.
Naïve Bayes ClassifierAlgorithm
It is a probabilistic classifier, which means it predicts on the basis of the
probability of an object.
Examples : spam filtration, Sentimental analysis, and classifying articles.
Naïve: It assumes that the occurrence of a certain feature is independent of the
occurrence of other features. Such as if the fruit is identified on the
bases of color, shape, and taste, then red, spherical, and sweet fruit is
recognized as an apple. Hence each feature individually contributes to
identify that it is an apple without depending on each other.
Bayes: It is used to determine the probability of a hypothesis with prior
knowledge. It depends on the conditional probability.
24.
P(A|B) isPosterior probability: Probability of hypothesis A on the observed event B.
P(B|A) is Likelihood probability: Probability of the evidence given that the probability of a hypothesis is true
P(A) is Prior Probability: Probability of hypothesis before observing the evidence.
P(B) is Marginal Probability: Probability of Evidence.
Step for NB Classification:
1. Convert the given dataset into frequency tables.
2. Generate Likelihood table by finding the probabilities of given features.
3. Now, use Bayes theorem to calculate the posterior probability.
25.
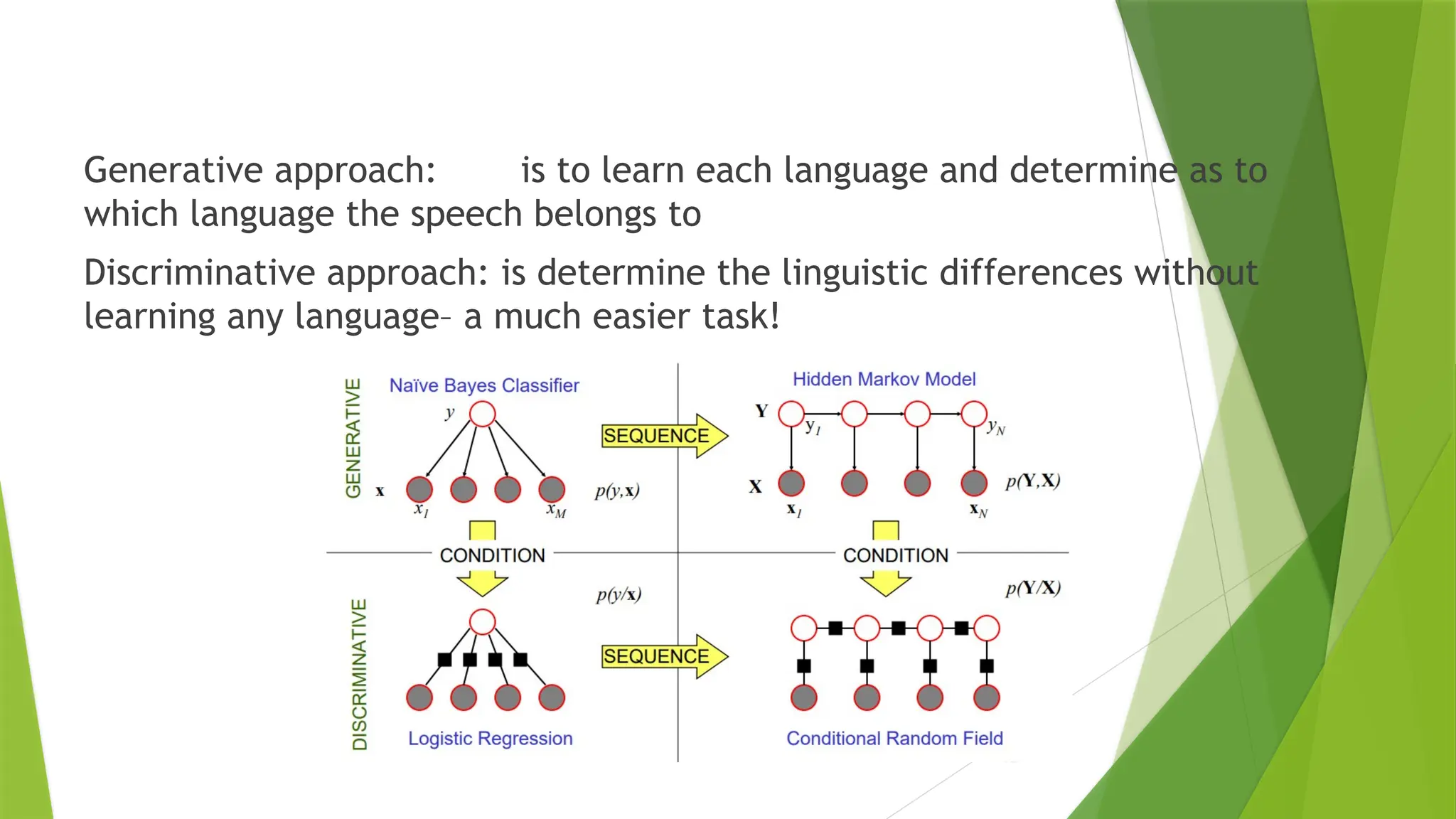
Generative approach: isto learn each language and determine as to
which language the speech belongs to
Discriminative approach: is determine the linguistic differences without
learning any language– a much easier task!
26.
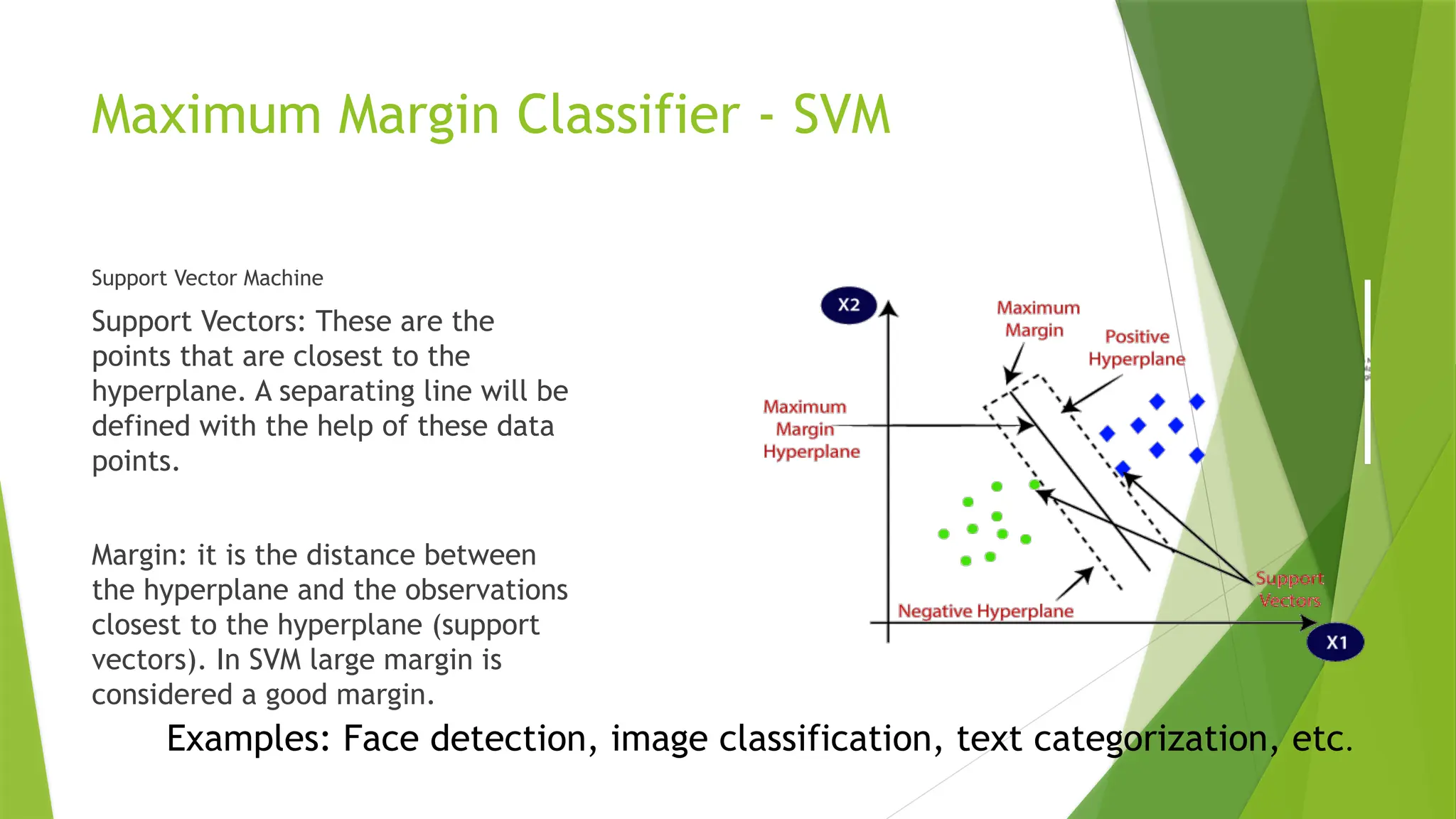
Maximum Margin Classifier- SVM
Support Vector Machine
Support Vectors: These are the
points that are closest to the
hyperplane. A separating line will be
defined with the help of these data
points.
Margin: it is the distance between
the hyperplane and the observations
closest to the hyperplane (support
vectors). In SVM large margin is
considered a good margin.
Examples: Face detection, image classification, text categorization, etc.
27.
Decision Tree ClassificationAlgorithm
Decision Trees usually mimic human
thinking ability while making a
decision, so it is easy to understand.
internal nodes --> features of a dataset
branches --> decision rules
leaf node --> outcome.
28.
Random Forest Algorithm
Random Forest is a classifier that contains a number of decision trees on various subsets
of the given dataset and takes the average to improve the predictive accuracy of that
dataset.
The greater number of trees in the forest leads to higher accuracy and prevents the
problem of overfitting.
29.
UNIT IV ENSEMBLETECHNIQUES AND UNSUPERVISED LEARNING
Combining multiple learners: Model combination schemes, Voting, Ensemble Learning - bagging,
boosting, stacking,
Unsupervised learning: K-means, Instance Based Learning: KNN, Gaussian mixture models and
Expectation maximization.
30.
Combining multiple learners
No one single algorithm is always the most accurate.
So many models are composed of multiple learners that complement each
other .
By combining them, we attain higher accuracy.
the combining of models is done by using two approaches namely “Ensemble
Models” & “Hybrid Models”.
31.
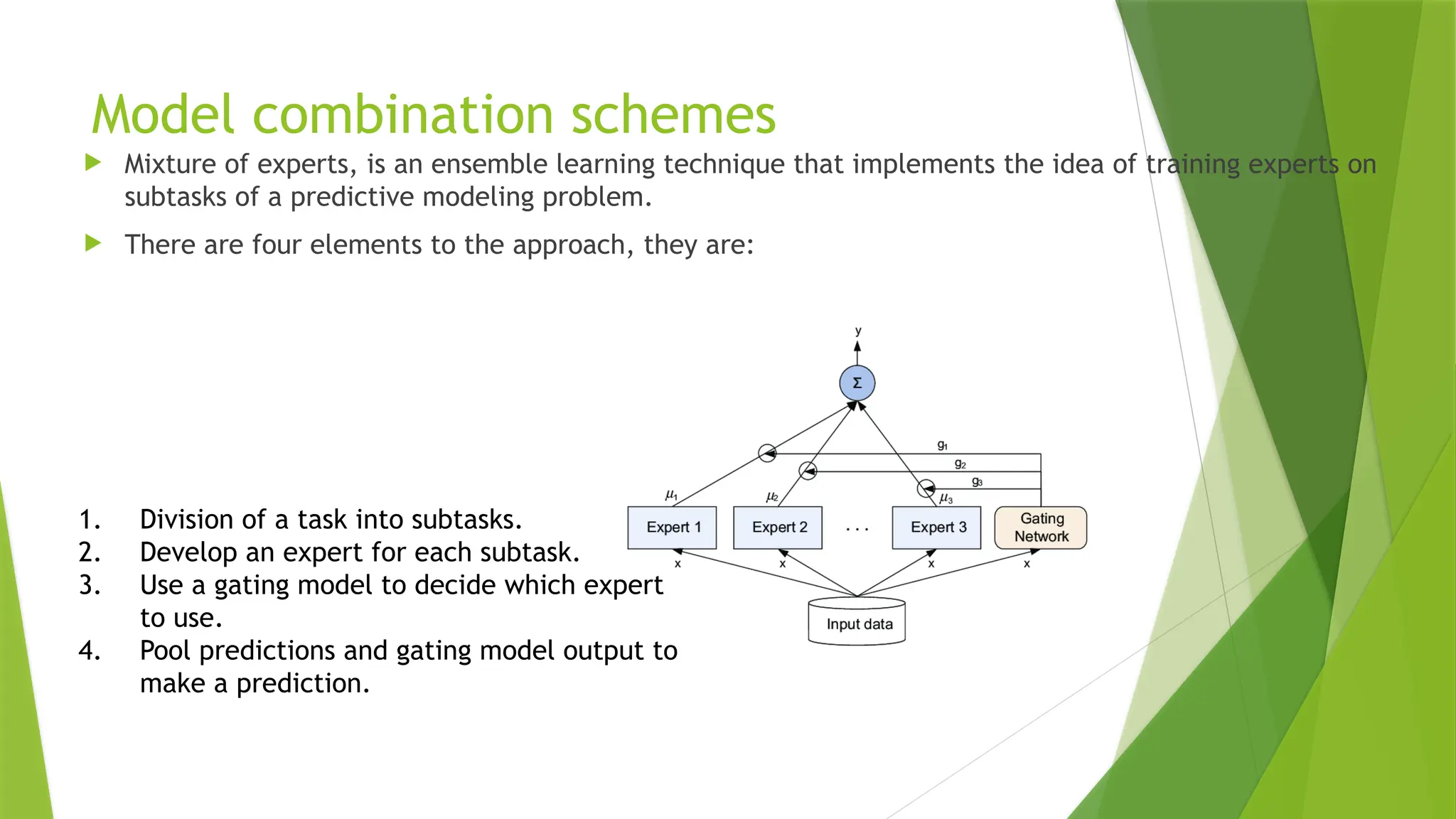
Model combination schemes
Mixture of experts, is an ensemble learning technique that implements the idea of training experts on
subtasks of a predictive modeling problem.
There are four elements to the approach, they are:
1. Division of a task into subtasks.
2. Develop an expert for each subtask.
3. Use a gating model to decide which expert
to use.
4. Pool predictions and gating model output to
make a prediction.
32.
Voting
• In VotingClassifiers, multiple models of the different
machine learning algorithms are present, to whom the
whole dataset is fed, and every algorithm will predict once
trained on the data.
• Once all the models predict the sample data, the most
frequent strategy is used to get the final prediction from
the model.
• Here, the category most predicted by the multiple
algorithms will be treated as the final prediction of the
model.
33.
Ensemble Learning
Ensemble ofclassifiers is a set of classifiers whose individual decisions combined in some way to
classify new approach.
Simplest approach:
1. Generate multiple classifiers
2. Each votes on test instance
3. Take majority as classification
Classifiers different due to different sampling of training data, or randomized parameters within
the classification algorithm
Aim: take simple mediocre algorithm and transform it into a super classifier without requiring any
fancy new algorithm
34.
BAGGING
• In bagging,we use bootstrap sampling to obtain subsets of data for
training a set of base models.
• Bootstrap sampling is the process of using increasingly large random
samples until you achieve diminishing returns in predictive accuracy.
• Each sample is used to train a separate decision tree, and the results
of each model are aggregated.
• For classification tasks, each model votes on an outcome.
• In regression tasks, the model result is averaged. Base models with
low bias but high variance are well-suited for bagging.
• Random forest, which are bagged combinations of decision trees, are
the canonical example of this approach.
35.
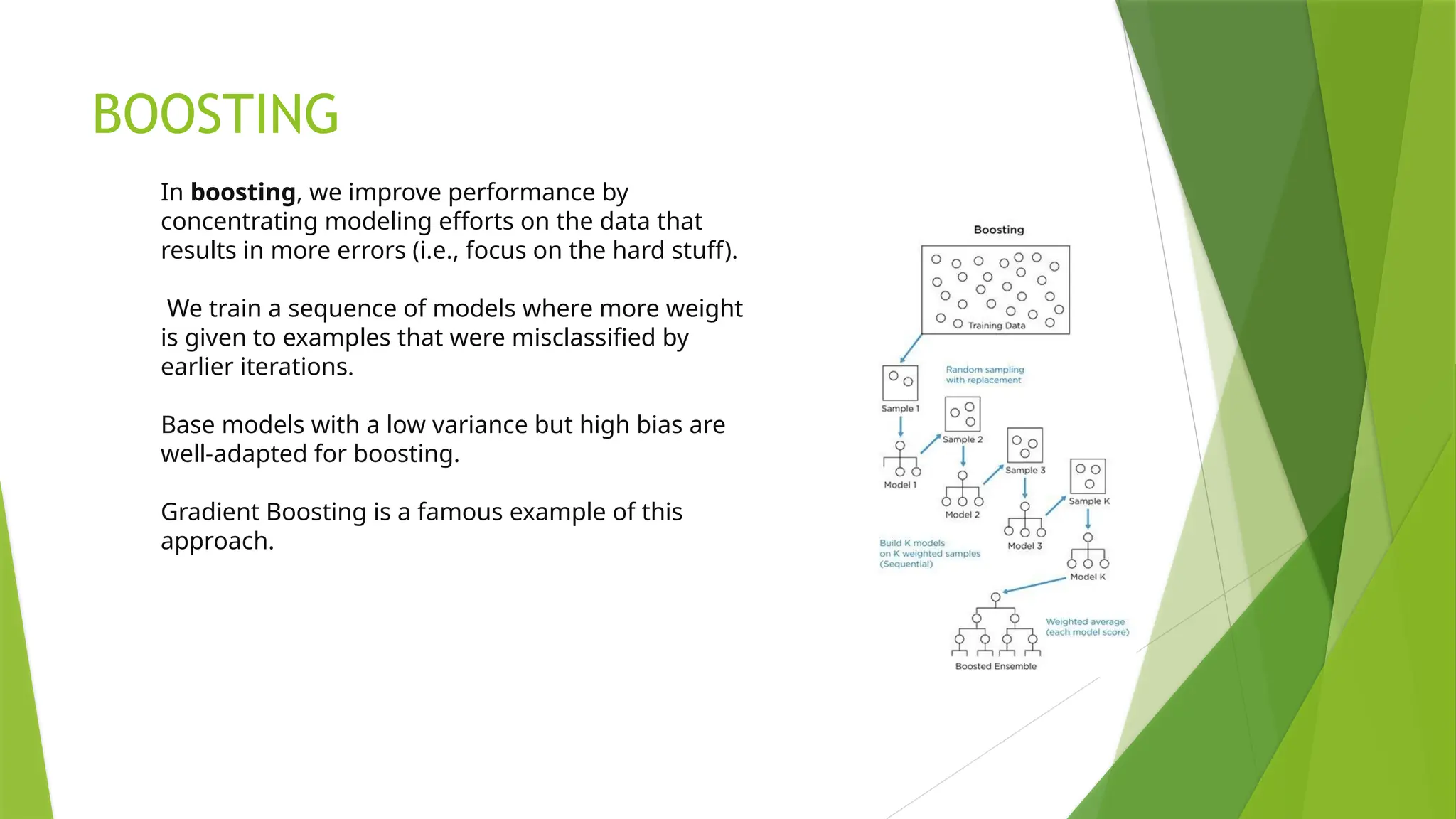
BOOSTING
In boosting, weimprove performance by
concentrating modeling efforts on the data that
results in more errors (i.e., focus on the hard stuff).
We train a sequence of models where more weight
is given to examples that were misclassified by
earlier iterations.
Base models with a low variance but high bias are
well-adapted for boosting.
Gradient Boosting is a famous example of this
approach.
36.
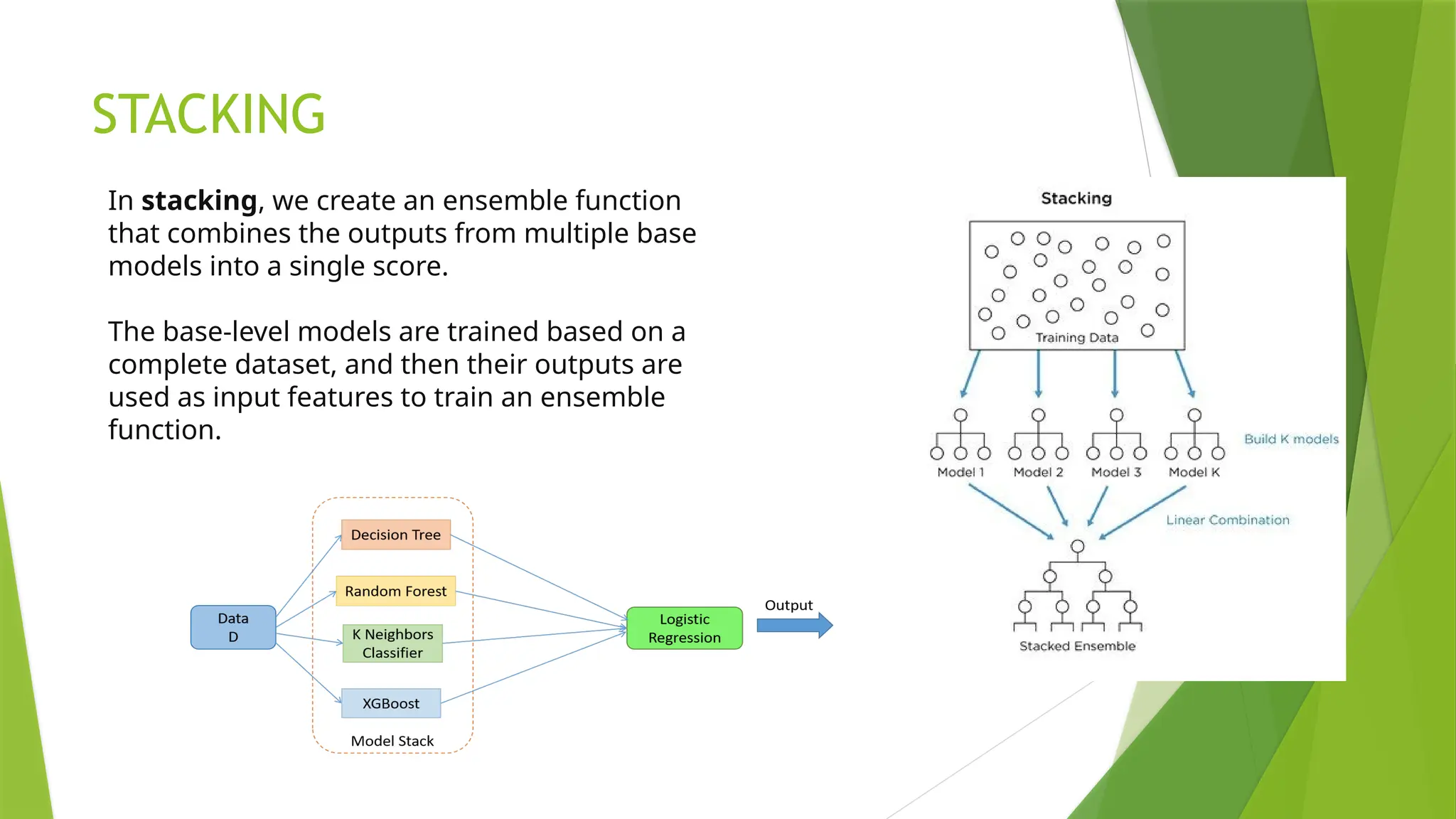
STACKING
In stacking, wecreate an ensemble function
that combines the outputs from multiple base
models into a single score.
The base-level models are trained based on a
complete dataset, and then their outputs are
used as input features to train an ensemble
function.
37.
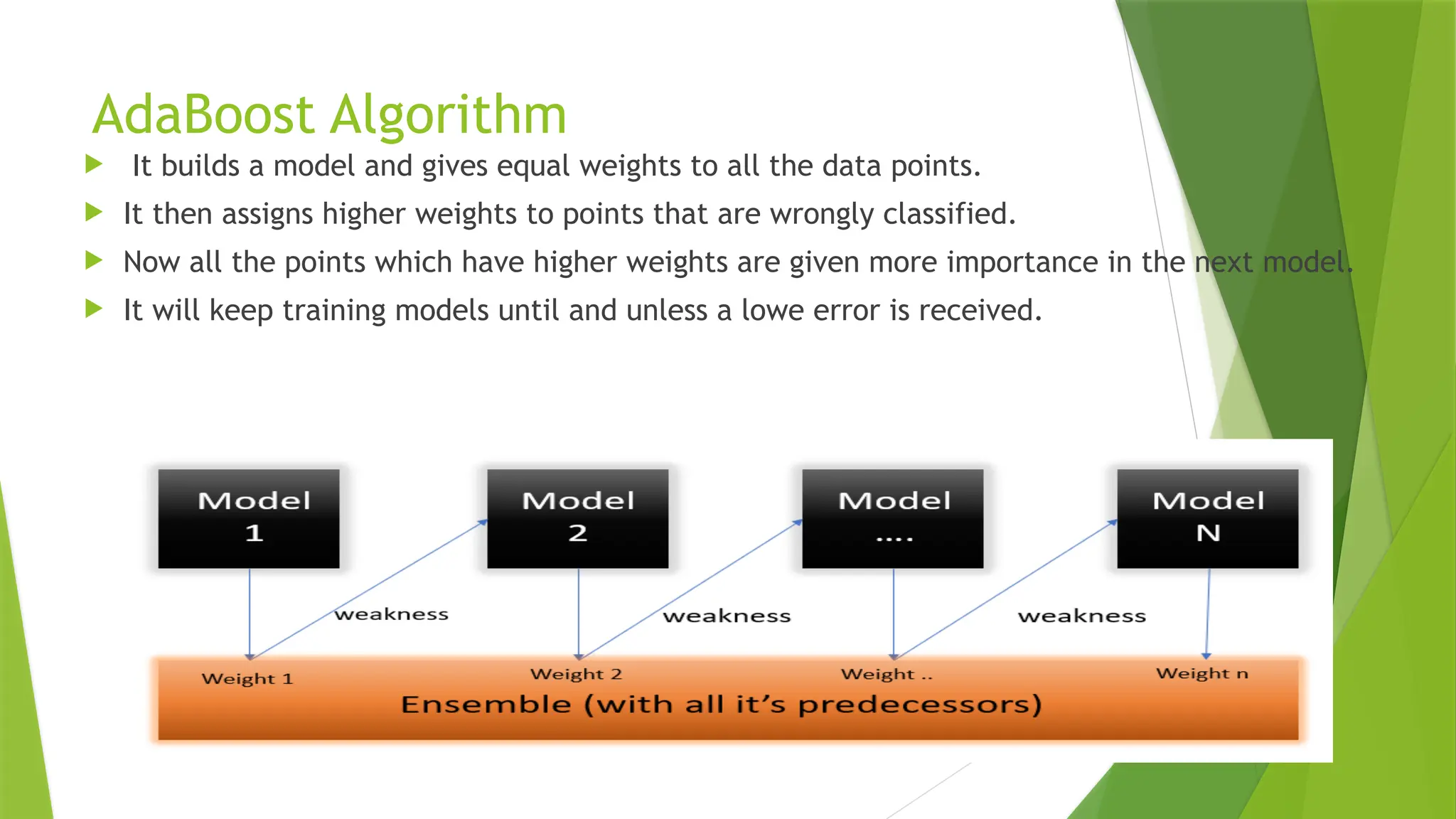
AdaBoost Algorithm
Itbuilds a model and gives equal weights to all the data points.
It then assigns higher weights to points that are wrongly classified.
Now all the points which have higher weights are given more importance in the next model.
It will keep training models until and unless a lowe error is received.
38.
Unsupervised learning: K-means
It is an iterative algorithm that divides the unlabeled dataset into k different clusters in such a way that
each dataset belongs only one group that has similar properties.
The k-means clustering algorithm mainly performs two tasks:
Determines the best value for K center points or centroids by an iterative process.
Assigns each data point to its closest k-center. Those data points which are near to the particular k-center, create a
cluster.
39.
Instance-based learning
Itsimply store the training examples instead of learning explicit description of the target function.
Generalizing the examples is postponed until a new instance must be classified.
When a new instance is encountered, its relationship to the stored examples is examined in order
to assign a target function value for the new instance.
Instance-based methods are sometimes referred to as lazy learning methods because they delay
processing until a new instance must be classified.
• A key advantage of lazy learning is that instead of
estimating the target function once for the entire
instance space, these methods can estimate it locally
and differently for each new instance to be classified.
• Instance-based learning includes KNN, Gaussian mixture
models and Expectation maximization.
40.
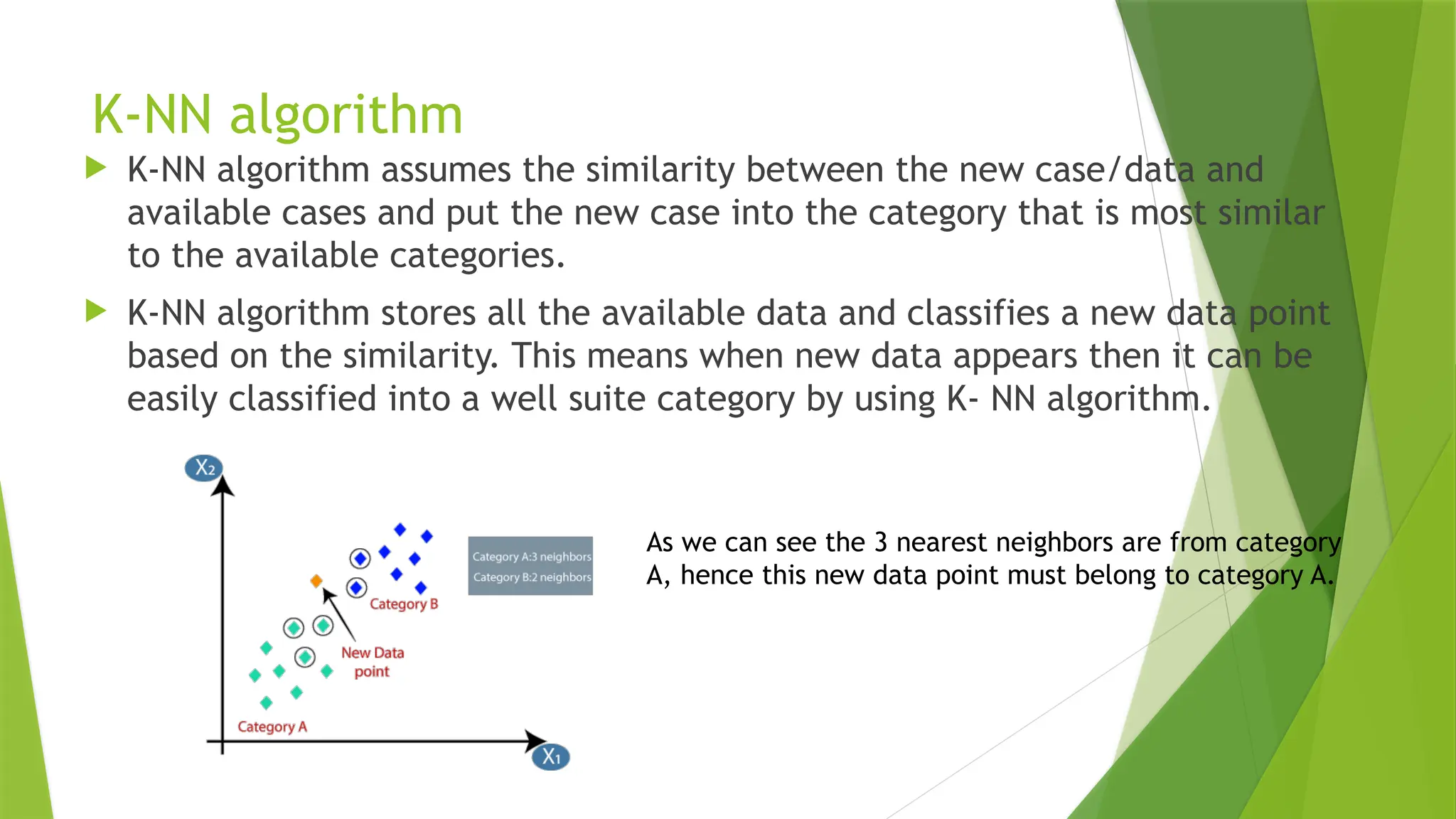
K-NN algorithm
K-NNalgorithm assumes the similarity between the new case/data and
available cases and put the new case into the category that is most similar
to the available categories.
K-NN algorithm stores all the available data and classifies a new data point
based on the similarity. This means when new data appears then it can be
easily classified into a well suite category by using K- NN algorithm.
As we can see the 3 nearest neighbors are from category
A, hence this new data point must belong to category A.
41.
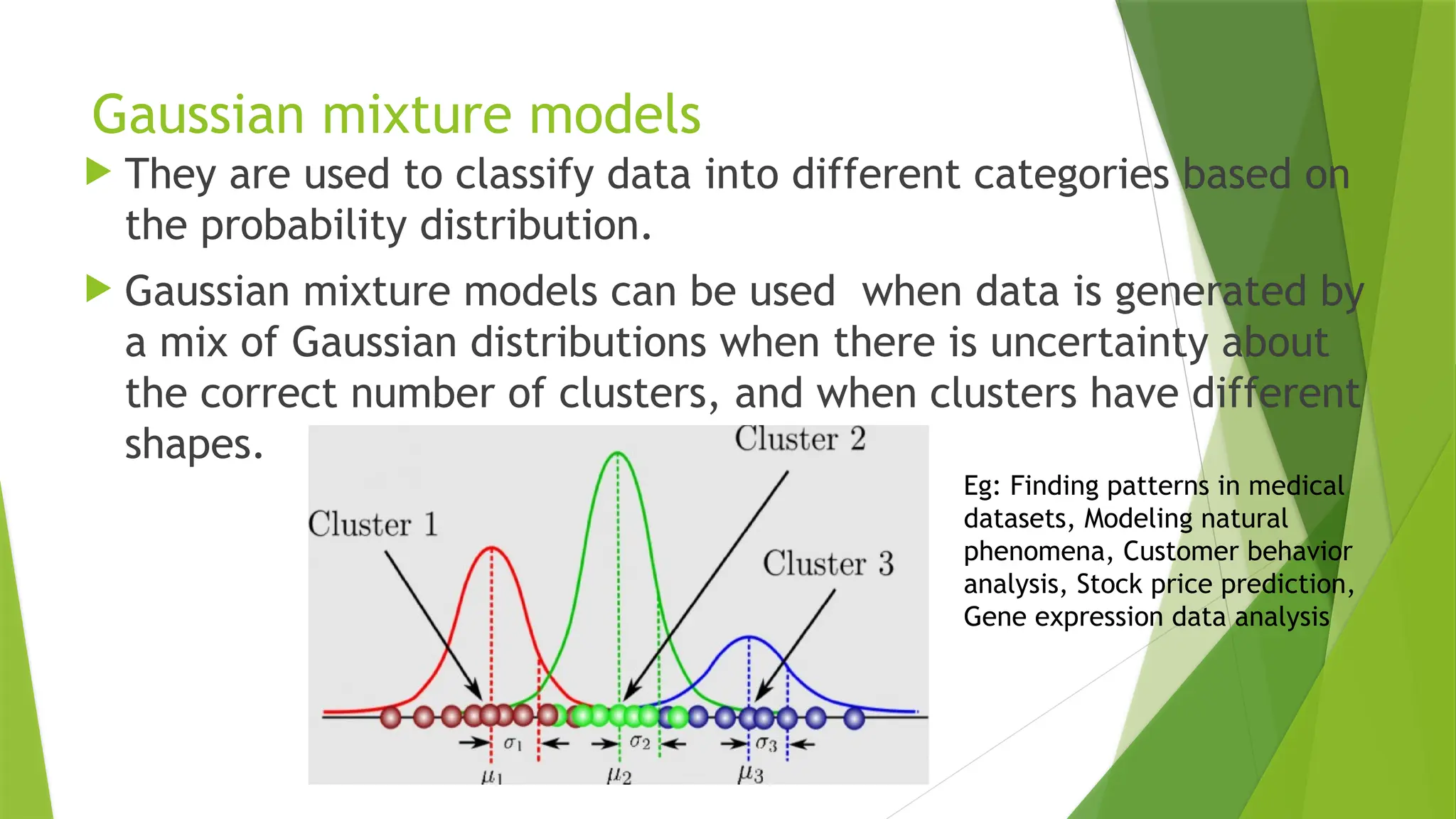
Gaussian mixture models
They are used to classify data into different categories based on
the probability distribution.
Gaussian mixture models can be used when data is generated by
a mix of Gaussian distributions when there is uncertainty about
the correct number of clusters, and when clusters have different
shapes.
Eg: Finding patterns in medical
datasets, Modeling natural
phenomena, Customer behavior
analysis, Stock price prediction,
Gene expression data analysis
42.
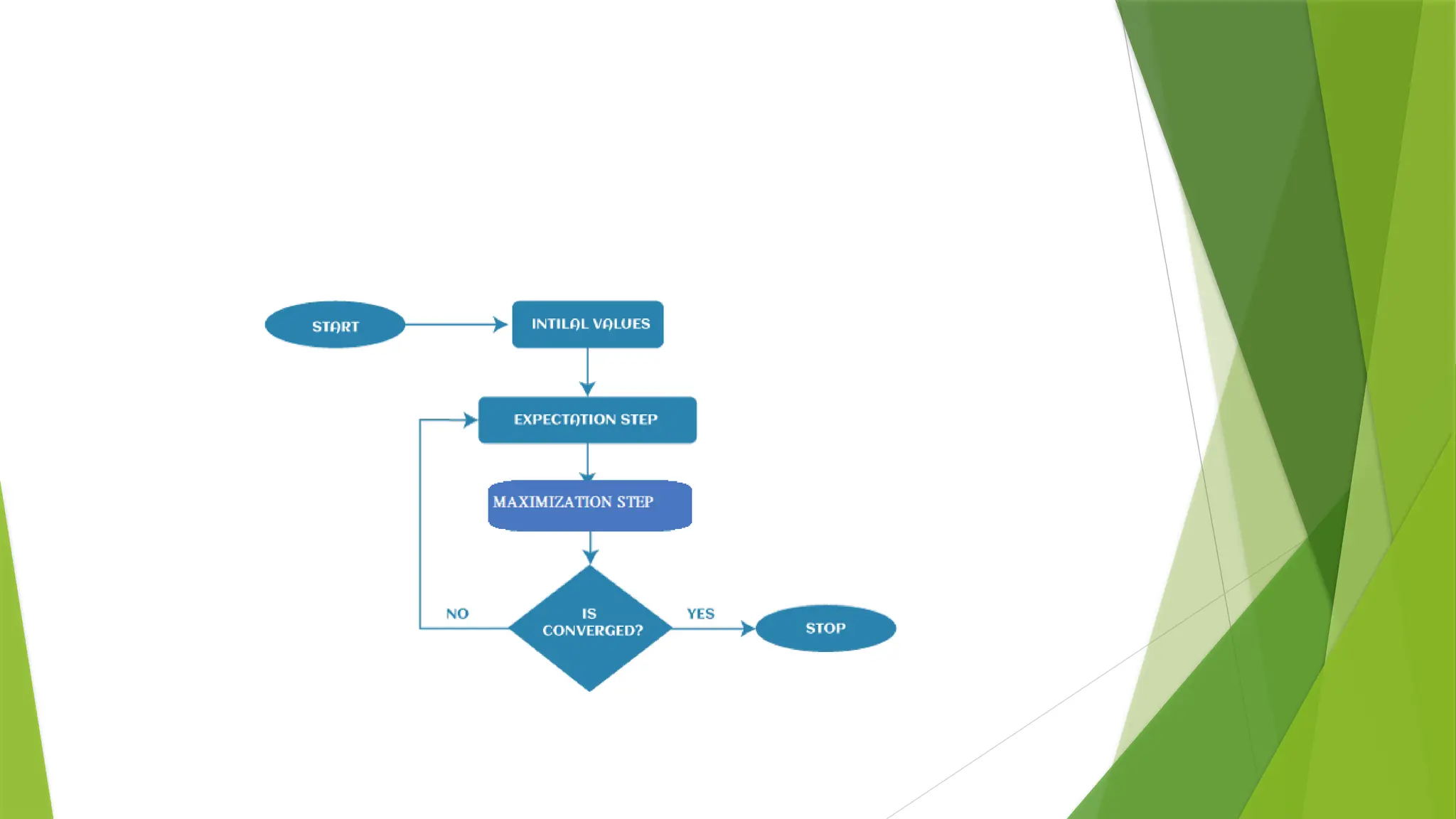
Expectation-Maximization (EM)
Algorithm
TheExpectation Maximization (EM) algorithm is an iterative way to find maximum-likelihood
estimates for model parameters when the data is incomplete or has some missing data points or has
some hidden variables.
EM chooses some random values for the missing data points and estimates a new set of data. These
new values are then recursively used to estimate a better data, by filling up missing points, until the
values get fixed.
44.
1. Expectation step(E - step): It involves the estimation (guess) of all missing
values in the dataset so that after completing this step, there should not be
any missing value.
2. Maximization step (M - step): This step involves the use of estimated data in
the E-step and updating the parameters.
3. Repeat E-step and M-step until the convergence of the values occurs.








































































































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)




